AI Everywhere: Arm Technology's "Zhouyi" NPU Ushers in a New Era of Edge AI
 11/08 2024
11/08 2024
 575
575
Illuminated by the glow of technology, large models have gracefully descended from the cloud-based halls to the stage of terminals. This historic leap not only endows data processing with swift wings but also elevates the intelligent experience to unprecedented heights. The large models on terminals, with their agile postures, instantly capture and respond to every subtle need, extending the reach of AI to every corner of the world.

Recently, at the 12th China Hard Technology Industry Chain Innovation Trend Summit and Hundred Media Forum hosted by EEVIA, Bao Minqi, Product Director of Arm Technology, delivered a fascinating keynote speech titled "Edge AI Application Chip Opportunities, NPU Accelerates Terminal Computing Power Upgrade." He delved into the vast prospects of edge AI development and detailed the latest advancements in Arm Technology's self-developed NPU.
Edge AI is on the Rise

The computing power boost brought by AIGC large models presents the biggest opportunity for edge AI. Bao Minqi noted that recent announcements from leading companies indicate that edge AI applications have gained unanimous industry recognition.

Currently, the mainstream edge-side large models deployed internationally and domestically mainly have fewer than 10 billion parameters. This limitation primarily stems from the memory bandwidth of edge devices, which typically ranges between 50-100GB/s. To meet users' real-time application demands, large models with 1-3 billion parameters are best suited for deployment under current bandwidth conditions. These models maintain high efficiency while providing rapid response and high-quality service.
Leading terminal manufacturers such as OPPO, vivo, Xiaomi, Honor, and Huawei are actively promoting edge AI development. They have not only developed large models suitable for edge deployment but also closely integrated them with specific business scenarios. Chip manufacturers also agree that AI NPU (Neural Processing Unit) will be the focus of future consumer electronics development. By leveraging specially optimized hardware architectures, NPU significantly enhances edge devices' AI computing capabilities while reducing power consumption.
Despite the robust momentum of edge AI, Bao Minqi emphasized that this does not mean abandoning cloud AI altogether. Instead, he believes that edge and cloud AI should complement each other to maximize benefits. Edge AI excels in timeliness and data localization security. Since data processing occurs locally on devices, user privacy is better protected, and real-time responses are achieved. Cloud AI, on the other hand, boasts stronger inference capabilities and large-scale data processing abilities, enabling more complex tasks. Combining the strengths of edge and cloud AI will provide users with a more comprehensive and efficient AI experience.
From the history of human-computer interaction interfaces, every transformation—from initial physical buttons to touchscreens and voice interaction, to current Agent intelligent agents—has significantly enhanced user experience. The future trend leans towards multimodal scenarios, integrating images, audio, video, and other input methods to enable devices to more comprehensively understand user needs. Through observation and learning, future AI systems will better predict and satisfy user expectations, achieving true intelligence.
Addressing Triple Challenges with Triple Upgrades
The rapid development of edge AI poses triple challenges to hardware devices: cost, power consumption, and ecosystem.
Cost challenges arise from device storage capacity, bandwidth, and chip computing resources. Power consumption stems from extensive data movement, and large models, unlike CNNs, cannot achieve high reuse, significantly increasing power consumption. Finally, continuous optimization and support for development tools also present challenges.
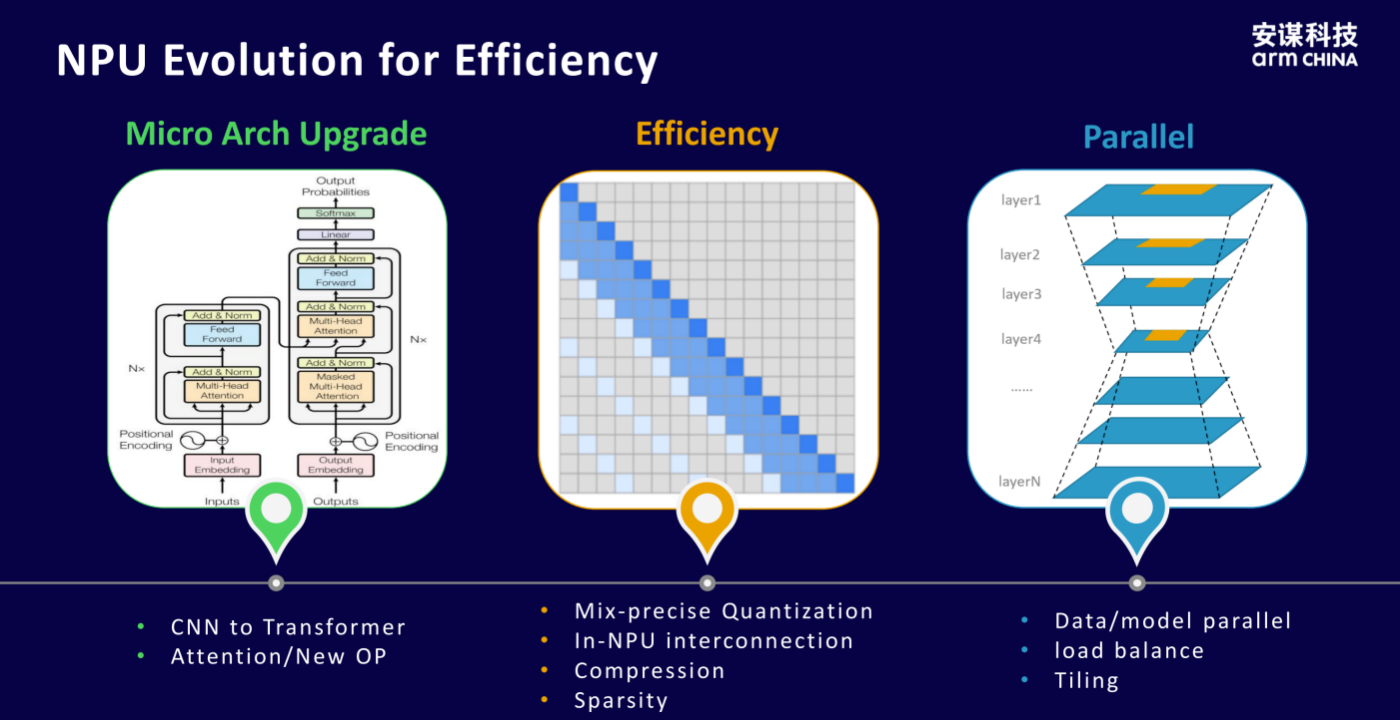
To tackle these challenges, Arm Technology's self-developed "Zhouyi" NPU has undergone upgrades in microarchitecture, energy efficiency, and parallel processing.
○ Microarchitecture: Recognizing the differences between CNNs and Transformers, the "Zhouyi" NPU retains CNN capabilities while optimizing for Transformers, overcoming bottlenecks in practical computations.
○ Efficiency: Implements mixed-precision quantization, such as int4 and fp16, achieving low-precision quantization at the algorithm and toolchain levels. Simultaneously, lossless data compression and sparsity alteration increase effective bandwidth. Additionally, In-NPU interconnection technology expands bus bandwidth.
○ Parallel Processing: Employs data or model parallelism, using load balancing and tiling to reduce data movement.
Bao Minqi also detailed the next-generation "Zhouyi" NPU architecture, which includes a Task Schedule Manager adaptable to multi-task scenarios. The entire architecture is scalable, adds DRAM for high-bandwidth matching, and includes OCM (Optional on Chip SRAM) to support algorithms with special requirements.
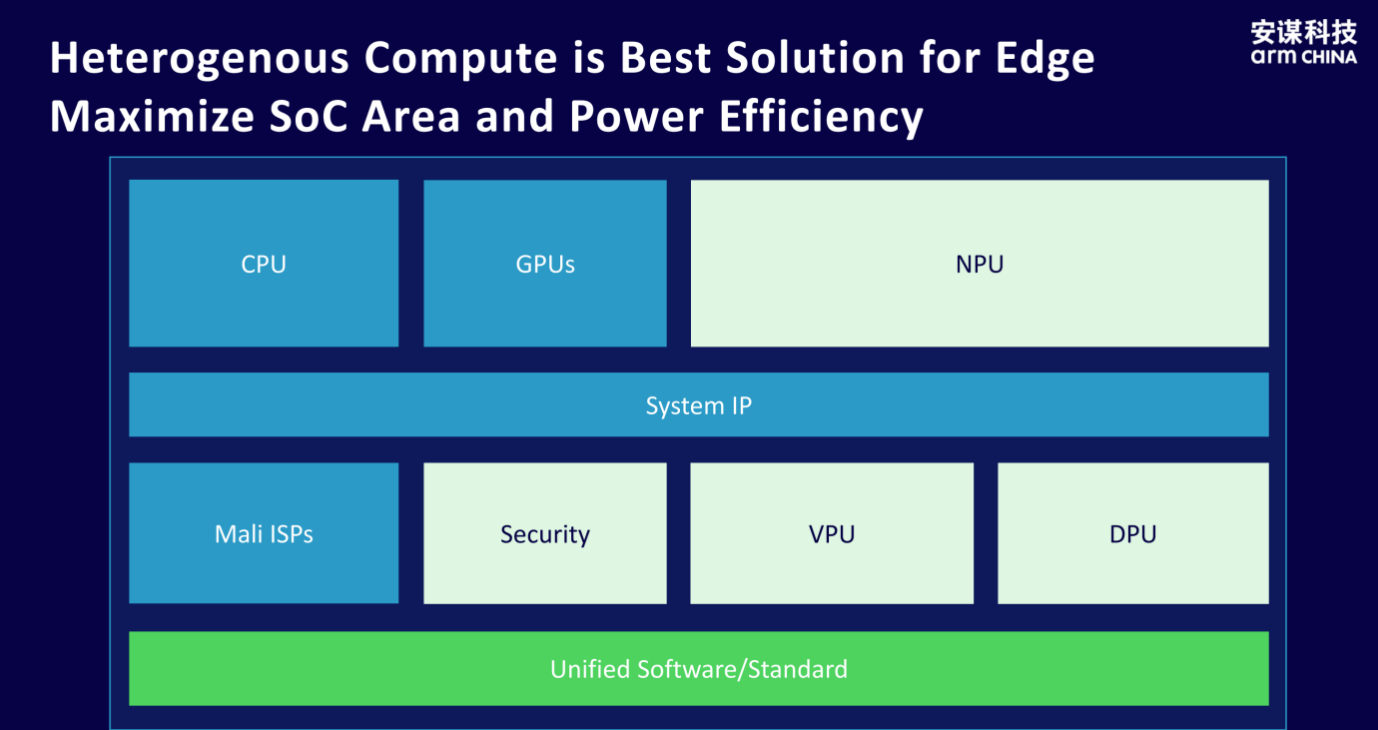
Bao Minqi emphasized the "Zhouyi" NPU's support for heterogeneous computing, noting that it is the optimal choice for edge AI chips from both energy efficiency and SoC (System on Chip) area perspectives. He explained that heterogeneous computing can flexibly tailor computing power for different application scenarios and minimize unnecessary power consumption.
Cross-Domain Application Experts
The "Zhouyi" NPU has demonstrated its robust performance and flexibility in key areas, particularly in automotive applications, AI accelerator cards, and AIoT scenarios.

In automotive applications, different scenarios demand varying computing power. While in-vehicle infotainment systems require moderate computing power, ADAS applications often need to perform multiple tasks, significantly increasing demands. The "Zhouyi" NPU offers a computing power range of 20~320TOPS, scalable to meet specific needs. Bao Minqi noted that over 400,000 chips equipped with the "Zhouyi" NPU from Xinqing Technology, the "Longying 1," have been shipped and successfully applied to over 20 main models from Geely's Link&Co, Geely Auto, and FAW Hongqi.

In AI accelerator card applications, the "Zhouyi" NPU efficiently interacts with various host processors (Host AP) like smart cars, PCs, and robots, processing audio, images, videos, and other data forms. This multimodal model support enables the "Zhouyi" NPU to maintain high performance and flexibility in complex data environments. In AIoT scenarios, devices are often strictly limited by area and power consumption. Nevertheless, the "Zhouyi" NPU provides efficient computing power while ensuring high security, making it an ideal choice for multiple applications.
Bao Minqi concluded by stating that the next-generation "Zhouyi" NPU will inherit and significantly enhance the strong computing power, easy deployment, and programmability of its predecessor. It will also continuously optimize aspects such as precision, bandwidth, scheduling management, and operator support. Additionally, the NPU must consider compatibility with current and future storage media to better meet market demands.
-
![]()
AI Hardware Competition Among Tech Giants: Integration of Software and Hardware is Easy, but Capturing the Ecosystem Entry Point is Tough
-
![]()
Why Doubao: The Latest Starter with the Lowest Cost Became the Hottest AI
-
![]()
Red Packets for Large Models Go Viral, Computing Power Leasing Emerges as the Biggest Winner
-
![]()
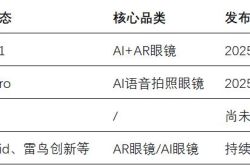
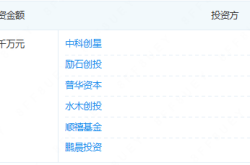
Established for Just Six Months, This Optical Enterprise Secures Tens of Millions in Funding: What’s Its Secret?
-
![]()
Computing Power Race (Part 1): How GPUs Transform into the New Oil of the AI Era
-
![]()
The 'Money-Burning War' Among Sino-US Tech Giants Erupts Again: Who Has Calculated the Costs of AI Investment?
-
![]()
Eleven Years of Internet Firms' Spring Festival Gala Marketing: 18 Billion Yuan in Giveaways, Yet the Era of WeChat Red Packet Excitement Fades
-
![]()
Kuaishou Joins the 'Battle': What's the Allure of Spring Festival Gala Red Packets?