Adopting a ChatGPT-like large model as the core of autonomous driving algorithms - Waymo's End-to-End Multimodal Algorithm EMMA
 11/08 2024
11/08 2024
 584
584
Recently, an internal research team from Waymo, an autonomous driving company that has been leveraging LiDAR and high-precision maps to achieve L4 autonomous driving, published a new paper on the realization of autonomous driving through end-to-end multimodal autonomous driving models.
It employs a large language model, Gemini LLM, similar to ChatGPT, as the core of the algorithm. All inputs and outputs of the algorithm are represented as plain text, showcasing remarkable versatility and generalizability. Additionally, the algorithm is interpretable.
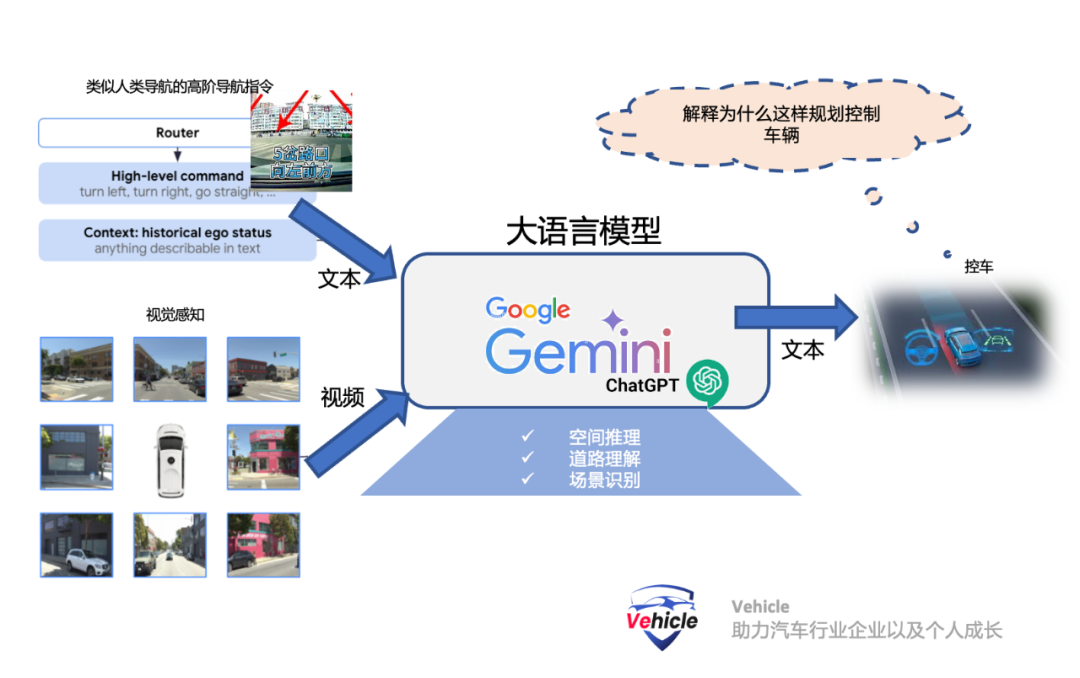
This has caused a sensation in the autonomous driving industry. Therefore, this article will provide a preliminary summary and introduction to Waymo's end-to-end multimodal autonomous driving model, EMMA, and related information:
Four current algorithmic approaches in the intelligent driving industry.
How does the "End-to-End Multimodal Autonomous Driving Model" (EMMA) work?
What are the limitations of current EMMA-like solutions?
What impact do they have on the current intelligent driving industry and even the automotive industry?
I hope to provide some information and insights into the development of intelligent driving and automobiles.
Four current algorithmic approaches in the intelligent driving industry:
Modular autonomous driving algorithms
Modular high-order intelligent driving systems utilize different modules or components such as perception, mapping, prediction, and planning.
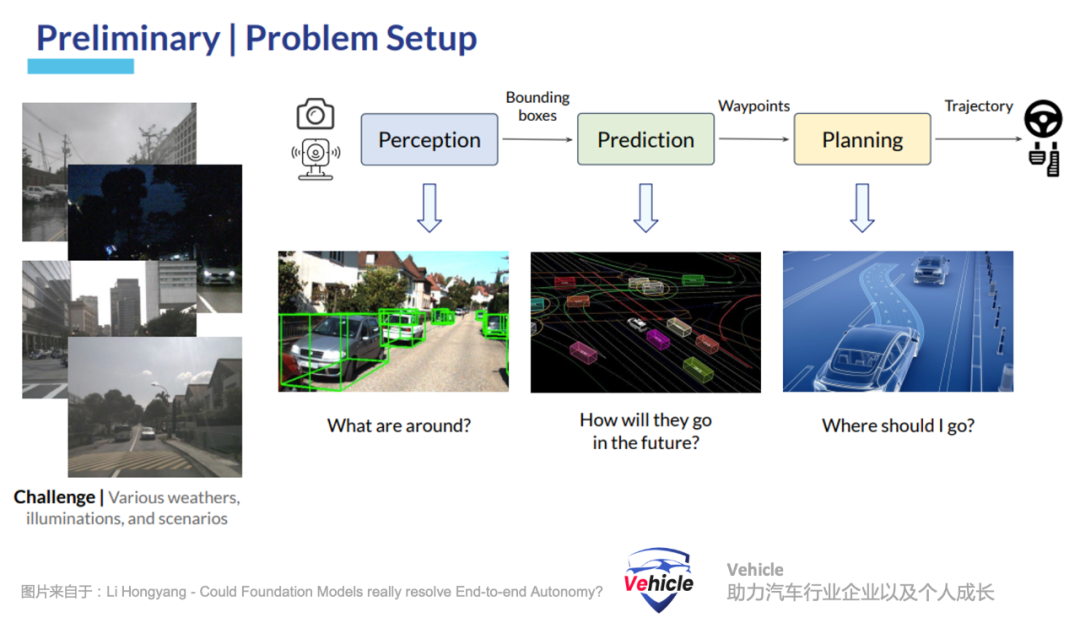
This design facilitates the debugging and optimization of individual modules or components. However, due to the accumulation of errors between modules and limited communication between them, it faces challenges in scalability. Notably, these modules are typically predefined based on target scenarios, so the rule-based interfaces between these modules (e.g., between perception and behavior modules) may struggle to adapt to new environments.
This approach can achieve high performance and cost-effectiveness in targeted scenarios in current intelligent driving applications. Mobileye, introduced in our previous article "Mobileye, Cornered, Raises the CAIS Banner to Challenge End-to-End Large Model Intelligent Driving," is a prominent representative in this regard.End-to-End Autonomous Driving Algorithms
Tesla FSD V12 was the first to adopt end-to-end autonomous driving algorithms in intelligent driving, learning driving behavior directly from sensor data. This method eliminates the need for signal interfaces between modules and allows the joint optimization of driving objectives from raw sensor inputs. This end-to-end algorithm is specifically designed for the task of driving and requires the collection of vast amounts of road driving data to train an entirely new model.

This is the current approach of Tesla and numerous domestic intelligent driving companies. Data and computing power are king, and everyone is diligently reinventing the wheel, hoping that one day their wheel will become a Michelin or Continental tire, unrivaled in the world. However, the long tail theory always exists, and everyone is constantly pushing to find out how long this tail really is.End-to-End Autonomous Driving Algorithms + LVM Image Language Model. Our previous article "Evolution and Future Challenges of Intelligent Driving Technology: From Object Recognition to Large Model Integration" shared cases of integrating and enhancing the capabilities of existing intelligent driving systems with multimodal language models. It leverages the large language model's ability to understand the world to interpret road image information, thereby enhancing end-to-end algorithm capabilities and compensating for the long tail.
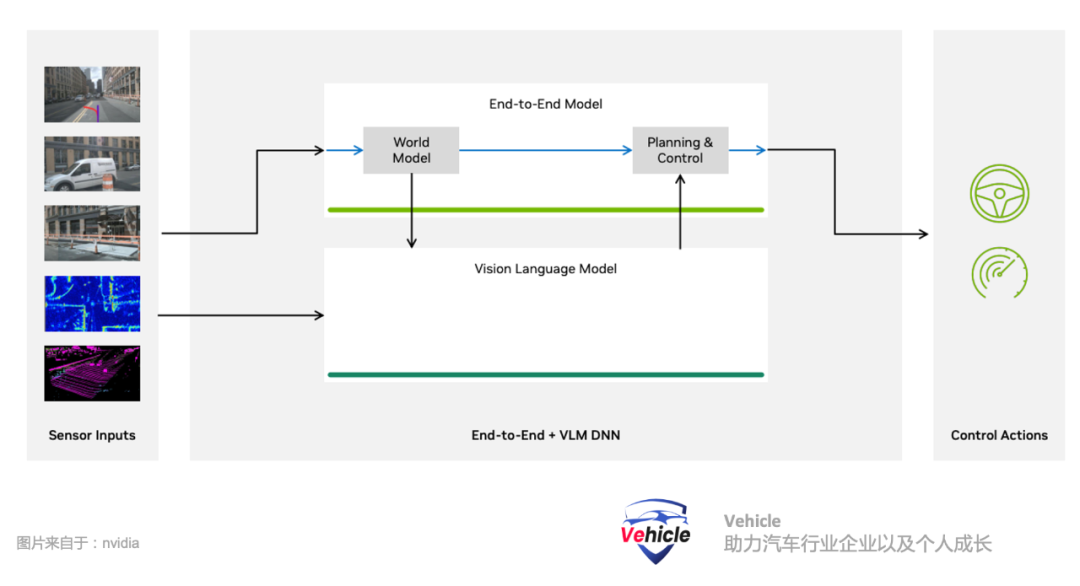
The latest autonomous driving technology from NIO, an industry leader, adopts this approach: E2E large model + LVM image language model.End-to-End Multimodal Autonomous Driving Large ModelThe Waymo end-to-end multimodal autonomous driving model EMMA introduced in this article represents another approach. Currently, it exists only as an academic paper and has not undergone engineering. It employs a multimodal large language model, providing a promising new paradigm for artificial intelligence in autonomous driving. It uses a general-purpose foundational large language model specifically adjusted for driving as the core algorithm or component of intelligent driving algorithms. Large language models excel in two key areas, eliminating the need to retrain a model: they are trained on textual information accumulated by humans on the internet, akin to the "sophons" in "The Three-Body Problem," which encapsulate human "world knowledge" into their algorithms. Their knowledge far surpasses that contained in common driving logs. They demonstrate remarkable reasoning abilities through techniques such as chain-of-thought reasoning, which are absent in dedicated driving systems.
Currently, a couple of companies in the industry are already moving towards this approach. For example, as mentioned in our previous article "Exploring California's Autonomous Driving Road Tests: Intense Competition, Diligent Exploration, and Technological Challenges," Ghost (which has since closed down this year) and Wayve employ the Open AI large model. However, they appear to have partially adopted this concept."How does the "End-to-End Multimodal Autonomous Driving Model" (EMMA) work?"The "End-to-End Multimodal Autonomous Driving Model" (EMMA) is built around Google's large language model, the Gemini framework, as its algorithmic core. Gemini is a text-based LLM similar to Open AI's ChatGPT, trained on extensive general text corpora to acquire knowledge of the world and human natural language. Simultaneously, the algorithm is trained and fine-tuned on a vast amount of text related to roads and driving, as well as many other general pieces of knowledge. Additionally, "end-to-end" training based on driving videos is incorporated. EMMA's key innovation lies in its ability to simultaneously process visual inputs (such as camera images) and non-visual inputs (like text-based driving instructions and historical contexts).
By reframing driving tasks as visual question answering (VQA) problems, EMMA can leverage the extensive knowledge encoded in Gemini's original model while endowing it with the ability to handle various driving tasks. The following are several key elements discussed in the paper:Multimodal Input: EMMA accepts camera images (visual data) as well as text inputs such as navigation instructions, driving instructions, and historical contexts, enabling it to understand and respond to complex driving scenarios involving both visual and non-visual information.Visual Question Answering (VQA) Method: By reframing driving tasks as VQA problems, EMMA can interpret visual data within the context of text instructions. This aids the model in better understanding dynamic and diverse situations in driving.Fine-tuning with Task-Specific Prompts: EMMA is fine-tuned using driving logs and task-specific prompts, enabling it to generate various driving outputs, such as future trajectories for motion planning, perceived objects, road map elements, and scene semantics.EMMA Overview Diagram:
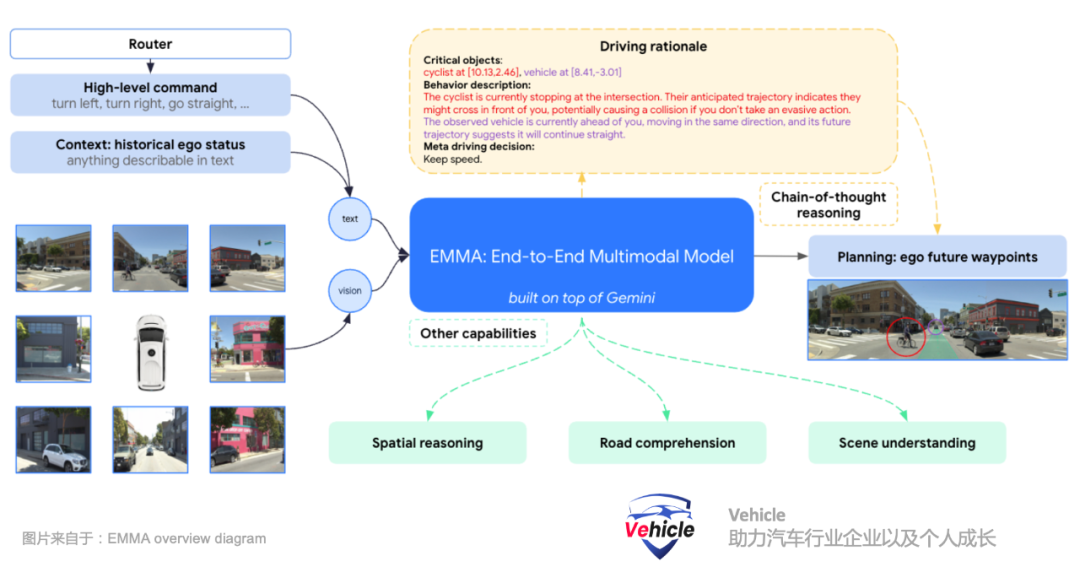
Its three inputs are:
Navigation instructions, similar to how humans use navigation, where the system receives high-level text instructions from navigation, such as "turn left in 100 meters ahead" or "turn right at the next intersection."The historical state of the ego vehicle, represented as a set of landmark coordinates in the Bird's Eye View (BEV) space at different timestamps. All landmark coordinates are expressed as plain text without special notation, facilitating extension to include higher-order ego vehicle states like speed and acceleration.Camera video perception. Perceiving the three-dimensional world, identifying surrounding objects, road maps, and traffic conditions through cameras.The Waymo team has built EMMA as a general model capable of handling multiple driving tasks through mixed training. By utilizing a visual-language framework, all inputs and outputs are represented as plain text, providing flexibility to integrate many other driving tasks into the system. The original large language model is fine-tuned using instruction-tuning, organizing perception tasks into three main categories: spatial reasoning, road map estimation, and scene understanding.
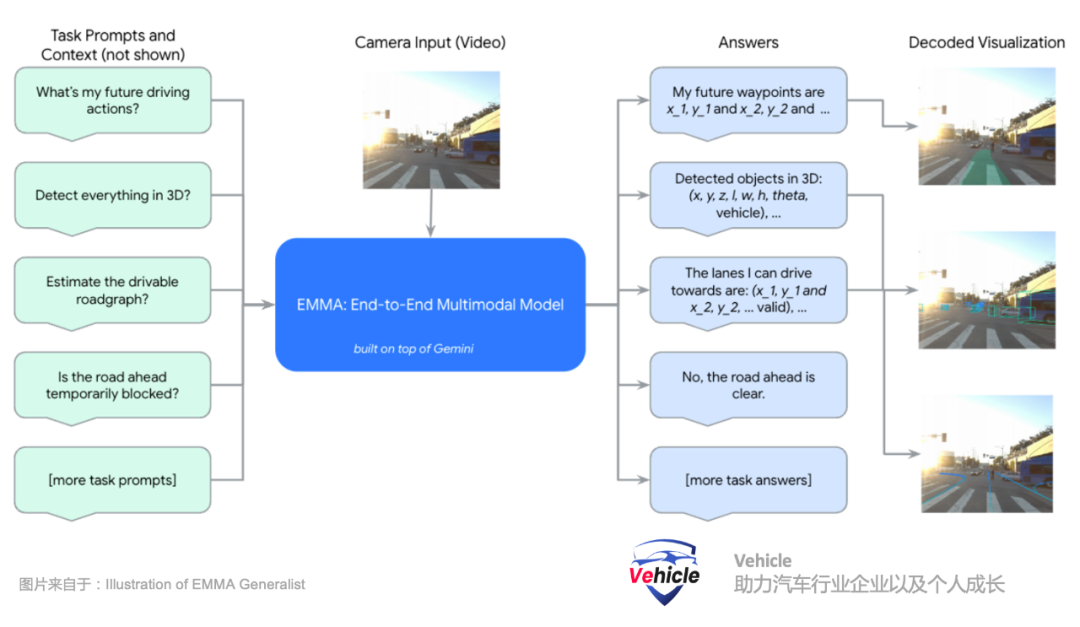
Spatial reasoning involves understanding, reasoning, and deriving conclusions about objects and their relationships in space. This enables the autonomous driving system to interpret and interact with its surroundings, facilitating safe navigation. The Waymo team ingeniously converts the 7-dimensional bounding box results of spatial reasoning ((x, y, z) represent the center position in the vehicle coordinate system, l, w, h are the length, width, and height of the bounding box, and θ is the heading angle) into text representations.Road map estimation focuses on identifying crucial road elements to ensure safe driving, including semantic elements (like lane markings, signs) and physical attributes (such as lane curvature). These collections of road elements constitute the road map.Scene understanding tasks test the model's comprehension of the entire scene context, which is particularly crucial for driving. For instance, roads might be temporarily blocked due to construction, emergencies, or other events. Timely detection of these blockages and safe detours are vital for ensuring smooth and safe operation of autonomous vehicles; however, multiple clues in the scene must be combined to determine the existence of blockages.All inputs and outputs are textual information. EMMA is fine-tuned using driving logs and task-specific prompts, enabling the fine-tuned LLM language model to generate various driving outputs, including motion planning and driving control signals.
This algorithm offers three advantages:Self-supervised: The only supervision required is the future position of the ego vehicle, eliminating the need for specialized manual labels.Camera-only: The only sensor input is from surround-view cameras.No high-definition maps: Apart from high-level navigation information from navigation systems (like Google Maps, similar to our Gaode and Baidu Maps), high-definition maps are not required.In fact, the biggest issue with end-to-end large models is interpretability. EMMA introduces Chain-of-Thought Prompting, which enhances the reasoning capabilities of multimodal large language models (MLLMs) and improves their interpretability. In EMMA, the Waymo team integrates chain-of-thought reasoning into end-to-end trajectory planning by requiring the model to articulate its decision rationale (Orationale) when predicting the final future trajectory landmarks (Otrajectory).The Waymo team structures driving reasoning into four coarse-to-fine information types:R1 - Scene Description: Provides a broad description of the driving scene, including weather, time, traffic conditions, and road conditions. For instance, "It's sunny and daytime. The road is a four-lane undivided street with sidewalks in the middle and parked cars on both sides."R2 - Key Objects: Refers to other agents on the road that may affect the ego vehicle's driving behavior. The model is required to identify their precise 3D/BEV coordinates. For example, "The pedestrian is located at [9.01, 3.22], and the vehicle is at [11.58, 0.35]."R3 - Behavior Description of Key Objects: Describes the current state and intention of identified key objects. For example, "The pedestrian is currently standing on the sidewalk, facing the road, and may be preparing to cross. The vehicle is currently in front of me, traveling in the same direction, and its future trajectory indicates it will continue straight ahead."R4 - Meta-driving Decisions: Encompasses 12 categories of high-level driving decisions that summarize the driving plan based on the aforementioned observations. For example, "I should maintain my current low speed."The Waymo team emphasizes that the driving reasoning text is generated through automated tools without any additional manual labels, ensuring scalability in the data generation process.
What are the limitations of current EMMA?If it's so great, why not implement it directly in vehicles? The Waymo team points out that their current model can only process a limited number of image frames at a time (up to 4 frames). Those familiar with autonomous driving know that safety-critical scenarios may even require more frames to determine the scene accurately. This limits its ability to capture the long-term dependencies necessary for driving tasks. Effective autonomous driving requires not only real-time decision-making but also reasoning over extended periods to predict and respond to changing scenarios. Therefore, such algorithms must address the issue of long-term memory.
Moreover, currently, there are no automotive onboard computing chips capable of running large models with so many parameters. Our previous article "Qualcomm's Next-Generation Smart Car Chips - Snapdragon Cockpit Elite and Ride Elite" introduced Qualcomm's next-generation smart car chips, capable of running large language models with up to billions of parameters. Recently, XPeng's AI Day revealed that its new Turing chip can run models with up to 30 billion parameters, but it's unclear when it will be integrated into vehicles. Current large language models have parameters in the tens of billions.

Furthermore, as computing power increases, the entire computing system, from cache to bandwidth to thermal management, must keep pace, requiring current onboard computing platforms to keep up.Meanwhile, another critical issue is real-time performance. While a slight delay of a few seconds is acceptable for large models used in ChatGPT conversations or Midjourny drawings, affecting life safety, milliseconds matter in automotive applications, directly related to safety. In summary, current large language models need to be distilled to reduce parameters while ensuring a certain level of accuracy for implementation. Therefore, this method must optimize the model or distill it into a more compact version suitable for real-time deployment while ensuring performance and safety are not compromised. Additionally, the current model can directly predict driving signals without relying on intermediate outputs (like object detection or road map estimation). This approach poses challenges during real-time verification and post-analysis. Although the Waymo team has demonstrated that the model can generate interpretable outputs such as object and road map predictions, and driving decisions can be explained through chain-of-thought reasoning, these outputs do not always align perfectly with actual driving signals, indicating that the interpretability may sometimes be flawed.
Finally, the current models primarily rely on pre-trained multimodal large language models (MLLMs), which typically do not include LiDAR or radar inputs, making the deployment of redundant multi-sensor solutions in vehicles a significant challenge. To deploy such large models in vehicles, engineering challenges that need to be addressed include: powerful computing chips capable of supporting local LLM models with parameters ranging up to tens of billions or even hundreds of billions. After distillation and optimization, the parameters can be reduced, making the large model suitable for deployment in vehicles, suitable for real-time deployment, while ensuring no sacrifice in performance and safety. This somewhat aligns with the theory of Xiaopeng Motors' cloud-based large model and vehicle-end small model.
Support LLM models with long-term memory and reduce latency. Generalize and integrate sensors such as LiDAR and radar effectively.
Solving these engineering challenges paves the way for vehicle engineering. What impact does this have on current intelligent driving and even the automotive industry? Firstly, Waymo's release of the end-to-end multimodal autonomous driving model EMMA adds another reassurance to the era of intelligent driving. Current AI-based end-to-end solutions theoretically enable autonomous driving, and the next step is engineering implementation. It is certain to help humans achieve autonomous driving, and it won't be too far off. Additionally, general artificial intelligence will become the engine of intelligent driving. The classification of intelligent vehicles can be achieved through model parameters and computing power, similar to how engine displacement determines vehicle class and performance in the era of fuel vehicles. For automakers, if they want to win in the era of intelligent vehicles, they may need to expand their ambitions and create a sufficiently large group that covers the manufacturing of vehicles, robots, and other AI-based products. It may be necessary to independently research and develop general artificial intelligence and leverage AI to empower the entire automotive and machinery projects, increasing the added value of the automotive machinery manufacturing industry. Alternatively, general artificial intelligence can be used to create differentiated products to achieve competition. Ultimately, general artificial intelligence may take over repetitive mental labor from humans, just as machinery now replaces physical labor.
*Reproduction and excerpts are strictly prohibited without permission - Reference Materials:
EMMA: End-to-End Multimodal Model for Autonomous Driving - waymo
Could Foundation Models really resolve End-to-end Autonomy? Hongyang Li
The Next Frontier in Embodied AI: Autonomous Driving CUED Guest Lecture – 25 April 2024
introduce autonomous vehicles - NVIDIA
GAIA-1: A Generative World Model for Autonomous Driving - wayve
-
![]()
AI Hardware Competition Among Tech Giants: Integration of Software and Hardware is Easy, but Capturing the Ecosystem Entry Point is Tough
-
![]()
Why Doubao: The Latest Starter with the Lowest Cost Became the Hottest AI
-
![]()
Red Packets for Large Models Go Viral, Computing Power Leasing Emerges as the Biggest Winner
-
![]()
Established for Just Six Months, This Optical Enterprise Secures Tens of Millions in Funding: What’s Its Secret?
-
![]()
Computing Power Race (Part 1): How GPUs Transform into the New Oil of the AI Era
-
![]()
The 'Money-Burning War' Among Sino-US Tech Giants Erupts Again: Who Has Calculated the Costs of AI Investment?
-
![]()
Eleven Years of Internet Firms' Spring Festival Gala Marketing: 18 Billion Yuan in Giveaways, Yet the Era of WeChat Red Packet Excitement Fades
-
![]()
Kuaishou Joins the 'Battle': What's the Allure of Spring Festival Gala Red Packets?