NVIDIA Unveils New AI Audio Model Fugatto
 11/26 2024
11/26 2024
 557
557
Compiled/Qianfang Intelligence
NVIDIA has recently launched a new AI audio model named Fugatto (full name: Foundational Generative Audio Transformer Opus 1). This model can not only generate music and sound effects based on text prompts but also modify and transform existing audio to create unprecedented sound combinations.

Image Source: NVIDIA
According to NVIDIA, Fugatto boasts several unique capabilities, such as converting piano music into vocals, adjusting accents and emotions in speech, and even creating surreal sound effects like a 'screaming saxophone' or 'barking trumpet.' The model employs innovative ComposableART technology, which combines audio features generated separately during training to produce entirely new sound effects.
On the technical front, the research team used approximately 20 million audio samples from various global open-source datasets for training, resulting in a large-scale model with 2.5 billion parameters. The project was collaboratively developed by researchers from India, Brazil, China, Jordan, South Korea, and other countries. This diverse team composition enables the model to excel in handling multiple languages and accents.
Bryan Catanzaro, Vice President of Applied Deep Learning Research at NVIDIA, stated that generative AI technology will bring new creative possibilities to musicians, gamers, and creators in general. However, considering the potential risks associated with generative technology, NVIDIA currently has no plans to release this technology externally.
-
![]()
Computing Power Race (Part 1): How GPUs Transform into the New Oil of the AI Era
-
![]()
The 'Money-Burning War' Among Sino-US Tech Giants Erupts Again: Who Has Calculated the Costs of AI Investment?
-
![]()
Eleven Years of Internet Firms' Spring Festival Gala Marketing: 18 Billion Yuan in Giveaways, Yet the Era of WeChat Red Packet Excitement Fades
-
![]()
Kuaishou Joins the 'Battle': What's the Allure of Spring Festival Gala Red Packets?
-
![]()
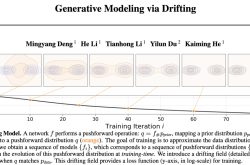
Disruptive Breakthrough! He Kaiming's Team Introduces 'Drifting Models' to Revolutionize Generative Paradigms: Achieving Record-Breaking Results with One-Step Inference
-
![]()
$630 Billion AI Arms Race: How Will Tech Giants Transition from Burning Money to Generating Profits by 2026?
-
![]()
AI Sanguosha: Qianwen 'Copies' Doubao, Yuanbao 'Pastes' WeChat
-
![]()
Qwen’s Meteoric Rise: A Strategic Triumph for Alibaba in Recent Years