2025 Autonomous Driving Set to "Take Off" with End-to-End Large Model 2.0 - VLA (Vision Language Action)
 12/23 2024
12/23 2024
 875
875
The race is fierce! The development of intelligent driving in China is progressing at breakneck speed. Following the initial battle for city-wide launches, the competition has shifted to point-to-point implementations, culminating in the Robotaxi market. In the realm of software technology, Huawei's recent announcement of its aggressive pursuit of end-to-end large models has escalated the battle for these models to a tense new phase.
So, what lies beyond end-to-end large models?
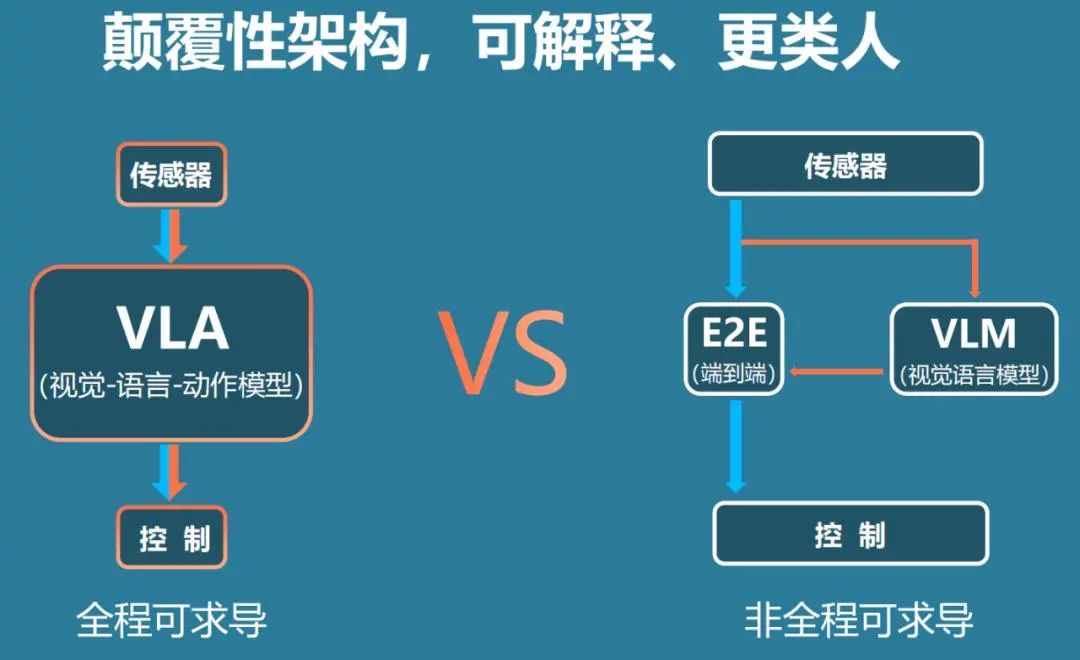
Recent signs suggest that VLA (Vision Language Action), building on VLM (Vision Language Model, detailed in our previous article "Evolution and Future Challenges of Intelligent Driving Technology: From Object Recognition to Large Models in Vehicles"), will be the focal point of comprehensive promotion and competition in the domestic autonomous driving industry in 2025. Companies are vying to develop end-to-end large model 2.0.

VLA's applications extend beyond autonomous driving to intelligent robots, the broader category of autonomous vehicles, and the foundation of embodied intelligence. This explains the current popularity of the humanoid robot industry. Embodied intelligence is gaining traction as robots pose less risk than cars; while car malfunctions can be life-threatening, robot malfunctions generally are not.

This article compiles relevant VLA papers and information on its development and application in the automotive industry, aiming to provide both informative and forward-looking insights.
What is the VLA Model?
What are the advantages of the VLA model?
What progress has been made with VLA in laboratories?
What challenges does the practical application of VLA face?
Which automakers are currently deploying VLA? Will VLA be the ultimate destination for autonomous driving?
What is the VLA Model
First, let's revisit the Vision Language Model (VLM), a machine learning model that processes visual information and natural language. It takes one or more images as input and generates a series of tokens, typically representing natural language text.
The magic of VLM lies in its training on internet image and text data, a repository of human wisdom. Like the sophons in "The Three-Body Problem," VLM absorbs the wisdom of human language and can understand and reason about image content.
The VLA model builds on VLM by utilizing robot or vehicle motion trajectory data to further train these existing VLMs, outputting text-encoded actions that can be used for robot or vehicle control.
These further-trained VLMs are known as Vision-Language-Action (VLA) models. By combining visual and language processing, VLA models can interpret complex instructions and execute actions in the physical world.
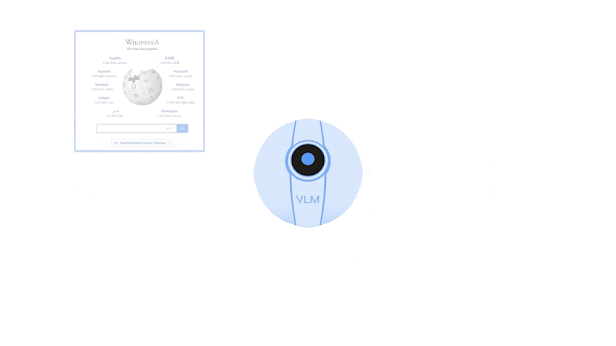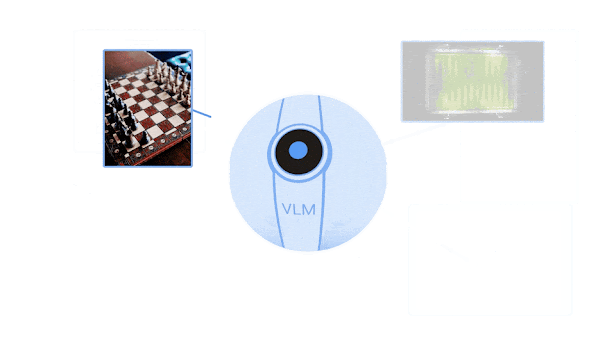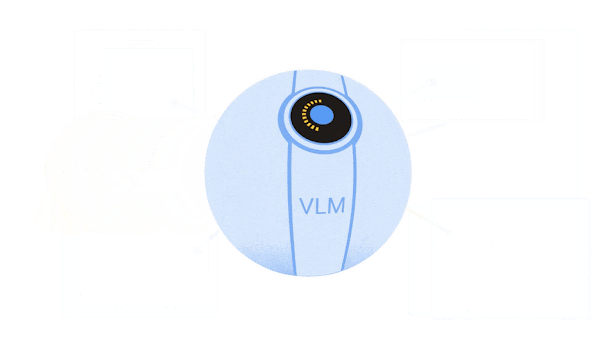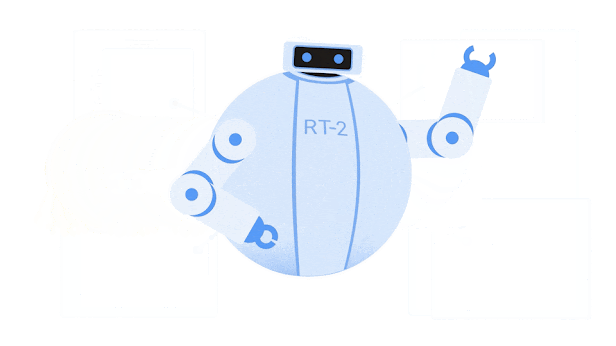
The above image of Google DeepMind's RT-2 provides a great visual explanation of VLA: VLA (RT-2) = VLM + robot motion data (RT-1).
What are the advantages of VLA? First, VLA is an end-to-end large model, so it has all the advantages of such models. Additionally, from vision to execution, it offers significant advantages in terms of reasonability and interpretability, as discussed in our previous article "Waymo's End-to-End Multimodal Algorithm EMMA Using a Large Model Similar to ChatGPT as the Core of Autonomous Driving Algorithms." Furthermore, it is versatile and can be adopted by all "intelligent machines" in the future. With fine-tuning, it can be applied to cars, flying devices, and any intelligent robots.
This is why we are seeing new forces entering various fields, including robots and aerial vehicles. They understand that general AI can be integrated into any mechanical device to turn it into an AI device, realizing physical AI (also called embodied intelligence, but I prefer the term physical AI) rather than just digital AI. VLA and other general models demonstrate continuous performance improvements in terms of data volume, computing resources, and model complexity. With human wisdom in natural language as the foundation, they can significantly reduce redundant data and computing resources while lowering model complexity.
What progress has been made with VLA in laboratories? Current AI advancements are primarily driven by innovative experiments conducted by renowned academic institutions and well-known companies. On July 28, 2023, Google DeepMind introduced RT-2, the world's first vision-language-action (VLA) model for robot control. RT-2 builds on Google's VLMs PaLI-X and PALM-E, which were fine-tuned using robot trajectory data collected by DeepMind during the development of the RT-1 model. This model outputs robot actions by representing them as text tokens. This unique approach enables the model to learn from natural language responses and robot actions, allowing it to perform various tasks.
RT-2 impresses with its generalization ability. It demonstrates significantly improved performance with new objects, backgrounds, and environments. It can interpret commands not present in the robot's training data and perform basic reasoning based on user commands. This reasoning ability stems from the chain-of-thought reasoning capability of the underlying language model. Examples of the model's reasoning ability include figuring out which object to pick up as a makeshift hammer (e.g., a rock) or which drink is best for a tired person (e.g., an energy drink). This level of generalization is a significant advancement in the field of robot control. While RT-2 is not open-source, it has inspired current intelligent robot development and given the industry confidence. Its emergence has spurred innovation.
Another notable model is OpenVLA, initiated by a team from Stanford University, the University of California, Berkeley, Google DeepMind, and the Toyota Research Institute. It is a vision-language-action model built on LLM/VLM for embodied robots and behavioral learning (the base model uses the Prismatic VLM of Llama-7B, DINOv2, and SigLIP). Instead of using image captioning or visual question answering, OpenVLA generates action tokens based on camera images and natural language instructions for controlling robots. Action tokens are discrete token IDs retained from the text tokenizer vocabulary, mapped to continuous values, and normalized according to each robot's range of motion.
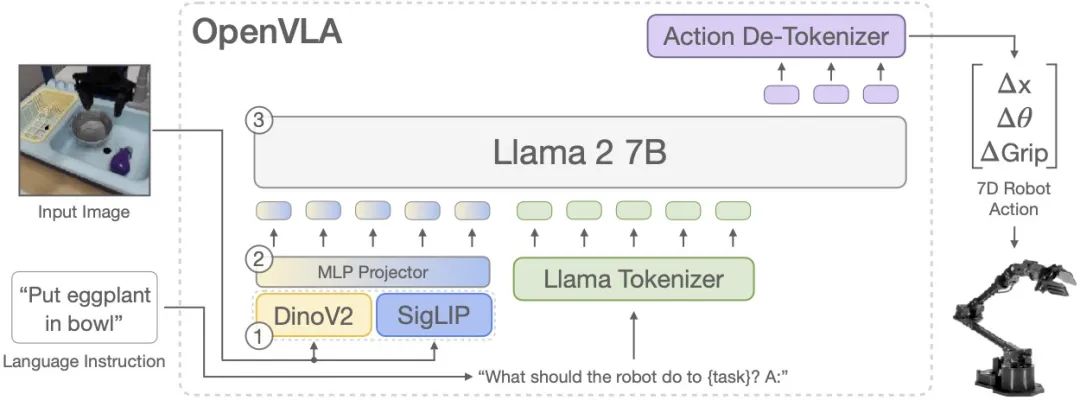
OpenVLA is trained by fine-tuning the pre-trained Prismatic-7B VLM. The model consists of three key elements: a fusion vision encoder (also called ViT or Vision Transformer), composed of SigLIP and DinoV2 backbones, where DinoV2 enhances spatial understanding by mapping image inputs to multiple "image patch embeddings," essentially encoding vision into language. The MLP Projector takes the output embeddings from the vision encoder and maps them to the input space of the large language model, serving as an intermediary between encoded language and the large language model. Llama 2 7B serves as the backbone of the language model, predicting tokenized output actions based on the mapped information. These tokens are decoded into continuous output actions that can be directly executed on robots.
OpenVLA is open-source, and many companies are likely researching based on it to explore VLA applications and commercial implementations. The above two models have had a significant impact. Besides VLA, there are other models such as Umass's 3D-VLA and Midea Group's Tiny-VLA.
What challenges does the practical application of VLA face? Despite its advantages, VLA cannot be immediately applied in daily life and commerce. Both RT-2 and OpenVLA, like other large models, have billions of parameters.
Due to their size, they require significant edge computing power. Taking OpenVLA's 7B parameter model as an example, the inference process is slow, requiring extensive pre-training on vast amounts of robot data, which complicates practical deployment. Therefore, the computational cost of running large VLA models in real-time is high, necessitating more research to optimize inference speed. Additionally, there are currently limited open-source VLM models available for fine-tuning. Future research should focus on developing technologies for higher-frequency control and making more VLM models available for training VLA models.
Physical AI must interact with the human world, necessitating real-time, high-frequency, and precise movements. While robots may require lower response times, generally available systems need to operate at 30-50 Hz. Intelligent car chassis, on the other hand, typically respond at 100 Hz. Thus, there is still a long way to go. Lastly, a challenge in applying VLA is matching language descriptions with driving behavior or robot actions during training.
A major obstacle to applying VLA models to autonomous driving is the lack of large-scale datasets that effectively combine visual data with language descriptions and driving behavior. Existing datasets often lack sufficient scale and comprehensive annotations, especially for language, which often requires laborious manual effort. This limits the development and evaluation of robust VLA models capable of handling the complexity of real-world driving. These are issues currently faced by VLA engineering that need to be addressed.
Which automakers are currently deploying VLA? Accurately speaking, there are currently very few, if any, applications of VLA, but many automakers and autonomous driving companies are in the process of deploying it.
As mentioned in our previous article "Waymo's End-to-End Multimodal Algorithm EMMA Using a Large Model Similar to ChatGPT as the Core of Autonomous Driving Algorithms," EMMA, developed and tested by Waymo's internal team, is an example of VLA in the making. Wayve, a foreign startup primarily funded by Microsoft and SoftBank, provides L4 software algorithms. Its test fleet has expanded from Europe to North America, and it has reached a cooperation agreement with Uber, potentially entering the Uber platform in the future. From the beginning, Wayve has adopted a general AI approach to autonomous driving, initially using LLM and later VLM. Currently, there are rumors that it is adopting a VLA-like model.
In China, AutoX announced last month its plan to use VLA, developing on NVIDIA's Thor chip. However, Thor's mass production has been delayed until the middle of next year, with high-performance Thor expected by the end of the year. Therefore, it is likely that VLA will gain significant attention in China by the middle of next year, intensifying competition.
Another example is Lixiang One, which, as discussed in our previous article "Evolution and Future Challenges of Intelligent Driving Technology: From Object Recognition to Large Models in Vehicles," began promoting VLM in the first half of the year. Now that its intelligent driving system already uses VLM, it is undoubtedly moving towards VLA. XPeng has not yet released information on this front, but given its product layout across robots, cars, and flying vehicles, it is likely betting on AI. Failing to adopt a general AI approach would be a strategic misstep, so it is plausible that XPeng is either in research or planning stages regarding VLA.
Huawei is a special case with its closed-loop system and Chinese characteristics. Its MDC with 200 TOPs obviously excels in standardized, small-model algorithms and vehicle motion control. However, recently, it seems to have recognized that end-to-end solutions are the future. This month's developments indicate its aggressive pursuit of one-stage end-to-end solutions, suggesting that its adoption of VLA may not be far off.
As for NIO, which held its NIO Day yesterday and announced numerous products (though I wasn't invited, so I'll point out an issue playfully), NIO has always been a brand I admire for its vision and style. However, it seems to be straying from the path of new forces by reverting to traditional automotive practices. While preparing on the hardware front, it currently lacks relevant information on intelligent driving software.
Will VLA be the ultimate destination for autonomous driving? It's hard to say. The direction of using AI in autonomous driving is set, but AI is advancing rapidly. The transition from using CNN for object recognition to Transformer BEV for constructing spatio-temporal relationships took only a few years, but the evolution from end-to-end large models to VLM using general AI happened within a year. So, will the future see a significant development in spatial AI, moving from textual LLM to visual VLM? AI is still a rapidly developing field, and anything is possible!
*Unauthorized reproduction and excerpting are strictly prohibited - References:
2024_Kira_ECCV_FOCUS.pdf -
Google deepmind RT-2 .pdf - Anthony Brohan, Noah Brown, et al
OPEN VLA .pdf - Moo Jin Kim∗,1 Karl Pertsch∗, et al
2024-IB-Introduction-Embodied-AI-Wayve.pdf
-
![]()
139 Institutions Conduct Research as Robotec Promptly Secures a Major Order Worth 129 Million Yuan!
-
![]()
Zeiss Boosts Investment to Expand 25,000-sqm Optical Plant, Elevating Its Exclusive EUV Optical Manufacturing Capabilities!
-
![]()
SAIC’s Four Key Divisions See Leadership Overhaul: Lu Xiao Moves to Passenger Cars, Xu Ping Takes Charge of GM, Wu Yun Leads Volkswagen
-
![]()
Nearly a Year On, Traffickers Still Reap Tens of Thousands by Selling Zeekr 9X in Russia
-
![]()
Apple’s New Business Model: Pay $39 a Month, But at What Cost to Your Wallet?
-
![]()
Tencent Places Its Bets on WorkBuddy: The Next Frontier in AI-Driven Office Solutions, Vying for the Smart Gateway
-
![]()
Apple Reclaims Global Market Cap Crown: Is a Strong Device the True Path for AI?
-
![]()
Apple Regains Global Market Cap Leadership: Are Smart Devices the Future of AI?