Exploring Privacy Concerns in Seven Leading Large Models
 01/16 2025
01/16 2025
 588
588


"The rigorously controlled data acquisition practices of the internet social networking era have now become the norm in the age of AI. Is enhancing user experience a justification for compromising user privacy?"
@TechNewKnowledge original
In the era of AI, user inputs transcend mere personal privacy; they become stepping stones for the advancement of large models.
"Help me create a PPT," "Create a New Year's poster for me," "Summarize this document." With the proliferation of large models, leveraging AI tools to boost efficiency has become routine for white-collar workers, and even extends to ordering food and booking hotels.
However, this data collection and utilization method poses significant privacy risks. Many users overlook a critical issue in the digital age: lack of transparency. They are unaware of how AI tools gather, process, and store their data, and uncertain if it's being misused or leaked.
In March this year, OpenAI admitted vulnerabilities in ChatGPT, leading to the leakage of some users' chat histories. This incident sparked public concern over data security and personal privacy in large models. Besides the ChatGPT breach, Meta's AI model has also faced controversy over copyright infringement. In April, American writers' and artists' organizations accused Meta's AI model of stealing their works for training, violating their copyrights.
Similarly, China has seen similar incidents. Recently, iQIYI and MiniMax, one of the "six little tigers of large models," garnered attention due to a copyright dispute. iQIYI accused Hailuo AI of using its copyrighted material without permission for model training, marking the first infringement lawsuit by a video platform against an AI video large model in China.
These incidents underscore the importance of training data sources and copyright issues in large models, indicating that AI technology development must be grounded in user privacy protection.
To assess the current transparency of domestic large models' information disclosure, "TechNewKnowledge" selected seven mainstream large model products: Doubao, ERNIE Bot, Kimi, Tencent Kunyuan, Spark Large Model, Tongyi Qianwen, and Kuaishou Keling. Through evaluations of privacy policies, user agreements, product feature design experiences, and practical tests, we found many products lacking in this area. We also clearly saw the delicate balance between user data and AI products.
01
Ineffective Right to Withdraw
Firstly, "TechNewKnowledge" observed from the login pages that all seven domestic large model products adhere to the "standard" usage agreement and privacy policy of internet apps, with sections explaining how personal information is collected and used.
These products' statements are largely consistent: "To optimize and enhance service experience, we may improve services by incorporating user feedback on output content and usage issues. Using secure encryption and strict de-identification, we may analyze user inputs to AI, issued commands, AI responses, and product access/usage data for model training."
While using user data to train products and iterate for better user experience seems a virtuous cycle, users are concerned about their right to refuse or withdraw data from AI training.
After reviewing and testing these seven AI products, "TechNewKnowledge" found that only Doubao, iFLYTEK, Tongyi Qianwen, and Keling mention in their privacy terms the ability to "change the scope of authorized products to continue collecting personal information or withdraw authorization."
Doubao focuses on voice information withdrawal, stating, "If you do not want your voice input used for model training and optimization, you can withdraw authorization by turning off 'Settings' - 'Account Settings' - 'Improve Voice Service.' For other information, contact us via the provided details to request withdrawal." However, for other information, "TechNewKnowledge" received no response after contacting Doubao.

Source / (Doubao)
Similarly, Tongyi Qianwen allows withdrawing voice service authorization only, requiring users to contact officials for other information changes or withdrawal.

Source / (Tongyi Qianwen)
As a video and image generation platform, Keling emphasizes facial usage, stating it won't use facial pixel information for other purposes or share it with third parties. Cancellation requires emailing officials.

Source / (Keling)
Compared to Doubao, Tongyi Qianwen, and Keling, iFLYTEK Spark has stricter requirements. Users can change or withdraw personal information collection scope only by deactivating their account.

Source / (iFLYTEK Spark)
Notably, while Tencent Yuanbao's terms don't mention changing information authorization, the app has a "Voice Function Improvement Plan" switch.
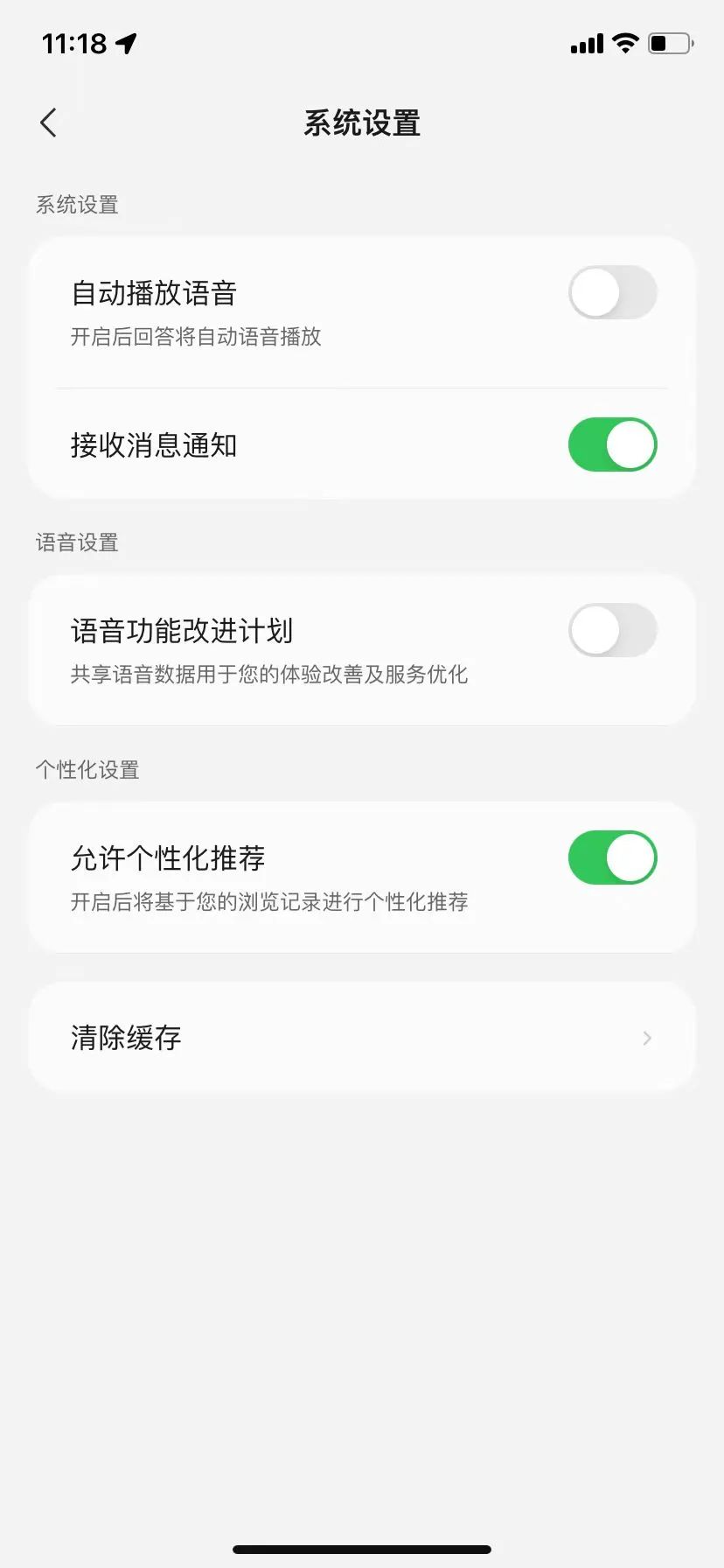
Source / (Tencent Yuanbao)
Kimi's privacy terms mention revoking third-party shared voiceprint information with in-app operations, but "TechNewKnowledge" couldn't find the change entry. No corresponding terms were found for other textual information.

Source / (Kimi Privacy Terms)
It's evident from mainstream large model applications that companies prioritize user voiceprint management. Doubao, Tongyi Qianwen, etc., allow independent authorization cancellation and basic interaction authorizations like location, camera, and microphone can be independently closed. However, withdrawing "fed" data isn't smooth for all companies.
Overseas large models have similar practices regarding the "user data exit AI training mechanism." Google's Gemini terms stipulate, "If you don't want us to review future conversations or use them to improve machine learning, turn off Gemini app activity recording."
Gemini also mentions that deleting app activity records won't delete reviewed or annotated conversation content (like language, device type, location, or feedback) saved separately and not associated with your Google account. These are retained for up to three years.
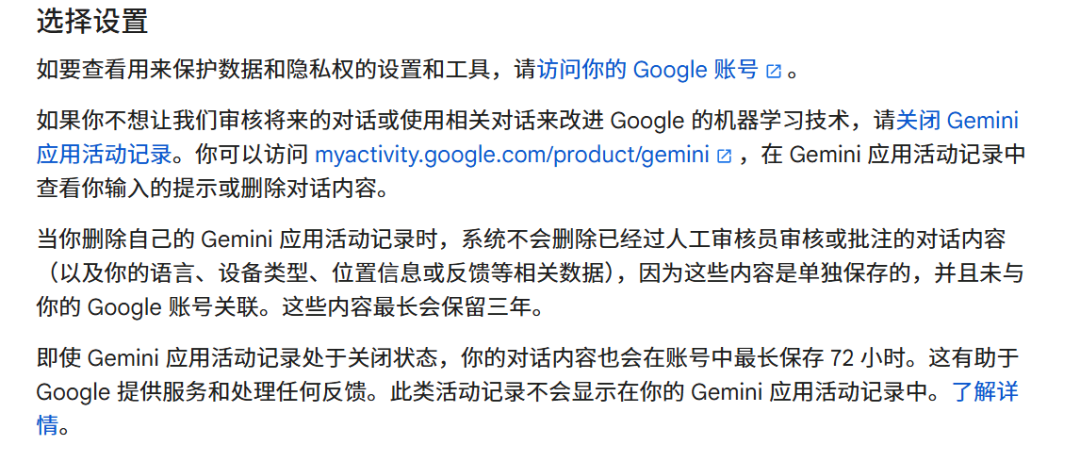
Source / (Gemini Terms)
ChatGPT's rules are somewhat ambiguous, stating users may restrict personal data processing. In practice, Plus users can disable training data, but free users' data is collected by default. Users need to email officials to opt out.

Source / (ChatGPT Terms)
These large model products' terms show that collecting user input is common. However, for private biometric information like voiceprints and faces, only some multimodal platforms show performance.
This isn't due to lack of experience, especially for internet giants. For example, WeChat's privacy terms detail data collection scenarios, purposes, and scope, even promising "not to collect chat records." Similarly, Douyin's privacy terms have detailed usage descriptions for almost all user-uploaded information.

Source / (Douyin Privacy Terms)
The rigorously controlled data acquisition of the internet social networking era is now the norm in AI. User inputs are freely obtained by large model manufacturers under the guise of "training corpora." User data is no longer treated as strict personal privacy but as a "stepping stone" for model progress.
Besides user data, training corpora transparency is crucial for large model experiments. Whether these corpora are reasonable and legal, constitute infringement, or pose usage risks are all concerns. With these questions, we delved into and evaluated these seven large model products, and the results were surprising.
02
Hidden Dangers in "Feeding" Training Corpora
High-quality corpora are vital for large model training, beyond computational power. However, these corpora often contain copyright-protected texts, images, and videos, and unauthorized use constitutes infringement.
After testing, "TechNewKnowledge" found none of the seven large model products mentioned specific training data sources or disclosed copyrighted data in their agreements.

The reason for not disclosing training corpora is simple. Improper data use can lead to copyright disputes, and there are no regulations on AI companies' legal use of copyrighted products for training corpora. Additionally, it might relate to corporate competition. Disclosing training corpora is like a food company revealing raw materials, enabling competitors to replicate and improve products.
Most model policy agreements mention using user-large model interaction data for model and service optimization, research, brand promotion, marketing, user research, etc.
Frankly, due to user data quality issues, insufficient scenario depth, and marginal effects, it's hard to enhance model capabilities and may even incur additional data cleaning costs. However, user data still holds value. They're no longer key to improving model capabilities but a new way for enterprises to gain commercial benefits. By analyzing user conversations, enterprises can understand user behavior, explore monetization scenarios, customize business functions, and even share information with advertisers, aligning with large model usage rules.
However, real-time processing data is uploaded and stored in the cloud. While most large models mention using encryption, anonymization, and other industry-standard means to protect personal information, there are still concerns about their actual effectiveness.
For instance, if user inputs become datasets, information leakage risks arise when others ask related questions later. Additionally, if the cloud or product is attacked, original information can still be restored through correlation or analysis technology, posing a hidden danger.
The European Data Protection Board (EDPB) has recently released guidelines on the handling of personal data by AI models. These guidelines underscore that the anonymity of AI models cannot be merely declared; rather, it must be rigorously verified through technical means and continuous monitoring. Moreover, companies are urged to not only justify the necessity of their data processing activities but also to employ methods that minimize intrusion into personal privacy during this process.

Hence, when large model companies collect data under the guise of "enhancing model performance," we must scrutinize whether this is genuinely necessary for model advancement or merely a pretext for data misuse for commercial gain.
03
Gray Areas in Data Security
Beyond conventional large model applications, the privacy risks posed by agents and edge AI applications are more intricate.
In contrast to AI tools like chatbots, agents and edge AI necessitate more detailed and valuable personal information for their operation. Traditionally, mobile phones primarily gathered user device and application data, log information, and underlying permission details. However, in edge AI scenarios and current technical methods predominantly based on screen reading and recording, beyond these comprehensive information permissions, terminal agents often access screen recording files themselves and can further analyze the model to extract sensitive information such as identity, location, and payment details.
For instance, in a scenario demonstrated by Honor at a previous press conference, AI applications silently read and recorded information like location, payment details, and preferences, heightening the risk of personal privacy breaches.

As previously analyzed by the Tencent Research Institute, in the mobile internet ecosystem, apps directly serving consumers are generally considered data controllers and bear corresponding responsibilities for privacy protection and data security in scenarios like e-commerce, social networking, and travel. However, when edge AI agents perform specific tasks leveraging app service capabilities, the boundaries of data security responsibility between terminal manufacturers and app service providers become blurred.
Manufacturers often cite the provision of enhanced services as justification. However, from an industry-wide perspective, this is not a valid excuse. Apple Intelligence, for instance, has explicitly stated that its cloud does not store user data and employs various technical safeguards to prevent any organization, including Apple itself, from accessing user data, thereby earning user trust.
Undeniably, there are numerous pressing issues regarding the transparency of current mainstream large models. Whether it's the difficulty in withdrawing user data, the lack of transparency in training corpus sources, or the complex privacy risks posed by agents and edge AI, these issues continually erode user trust in large models.
As a pivotal force driving the digitization process, enhancing the transparency of large models is imperative. This not only concerns the security of user personal information and privacy protection but is also crucial for the healthy and sustainable development of the entire large model industry.
Moving forward, we anticipate that major model vendors will proactively respond by optimizing product design and privacy policies. With a more open and transparent approach, they should clearly articulate the origin and flow of data to users, enabling them to confidently embrace large model technology. Simultaneously, regulatory authorities must expedite the improvement of relevant laws and regulations, clarify data usage norms and responsibility boundaries, and foster an innovative, safe, and orderly development environment for the large model industry, enabling these models to truly become powerful tools that benefit humanity.
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





