Google Establishes a New Team to Simulate AI Models of the Physical World
 01/17 2025
01/17 2025
 750
750
Preface: Overcoming major obstacles, [World Models] are poised to revolutionize virtual world generation, robotics, and AI decision-making, forging new paths for AI integration with reality.
Author | Fang Wensan
Image Source | Network

Google Establishes a New Team to Simulate AI Models of the Physical World
At the dawn of 2025, Google unveiled its AI ambitions, signaling a pivotal year for the company's advancements in this field.
In January, Google announced the integration of the AI Studio project team and the Gemini API development team into the Google DeepMind department, following last year's merger of the Gemini chatbot team into DeepMind.
Under the leadership of 2024 Nobel Laureate in Chemistry, Demis Hassabis, Google's AI R&D efforts have now been fully consolidated within DeepMind.
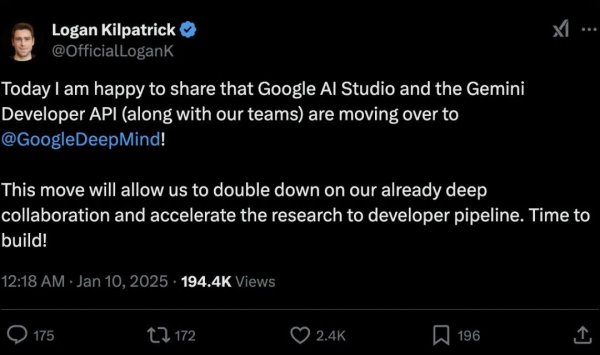
As Google deepens its integration of AI teams into DeepMind, the influence of Hassabis, a pioneer in game development, neuroscience, and AI, will grow significantly.
This marks the third consecutive integration of AI teams into DeepMind, following the consolidation of model R&D, basic research, and responsible AI teams.
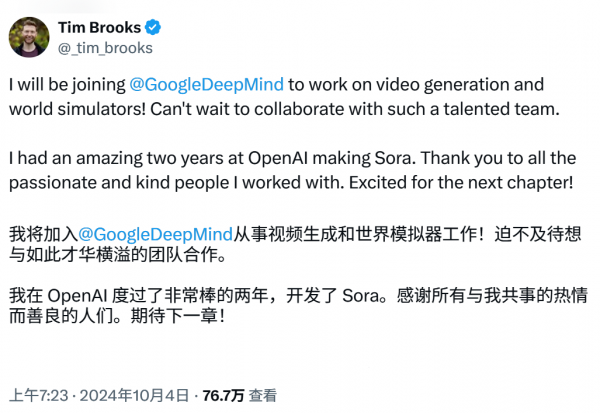
On January 6, Google officially announced the formation of a specialized team tasked with developing advanced large AI models capable of simulating the physical world, led by Tim Brooks, former co-head of OpenAI's video generation project, Sora.
Brooks stated, "Our ambition is to create a large generative model that can simulate the entire world."
According to job postings, the team will focus on solving [critical new problems] and pushing model performance to the [highest computational level].
This new team will collaborate closely with existing projects like Gemini, Veo, and Genie to enhance AI's capability to understand and simulate the real world.
Tim Brooks, co-leader of OpenAI's video generator Sora, joined Google's AI research arm, DeepMind, in October.
Brooks' new research team will focus on developing [real-time interactive generation] tools and exploring ways to integrate their models with existing multimodal models (e.g., Gemini).
With the goal of creating AI tools that can simulate real-world scenarios, Genie 2 aims to pave the way for Artificial General Intelligence (AGI) and steer a new direction in AI, leveraging cutting-edge technology for realistic simulations of complex physical environments with potential applications in gaming, film production, robot training, and beyond.
DeepMind believes that training AI on video and multimodal data is a crucial path to achieving AGI.
World Models will play a pivotal role in visual reasoning and simulation, planning for embodied agents, and real-time interactive entertainment.
The Positive Aspects of the Genie 2 Model for Constructing World Models
DeepMind has successfully integrated SIMA technology into the virtual world of Genie 2, a breakthrough expected to profoundly impact AI training methods and rapid prototyping in gaming.
The launch of Genie 2 underscores Google DeepMind's active participation and competitive stance in the realm of AI-constructed virtual worlds.
As a foundational AI tool, Genie 2 can transform a single image into an interactive 3D environment, supporting up to one minute of immersive interaction.
This technology excels across multiple dimensions, including motion control, counterfactual scenario generation, long-term memory, long video content creation, diverse environment simulation, 3D structure modeling, object interaction, complex character animation, NPC behavior, physical effects, smoke simulation, lighting effects, and rapid prototyping.
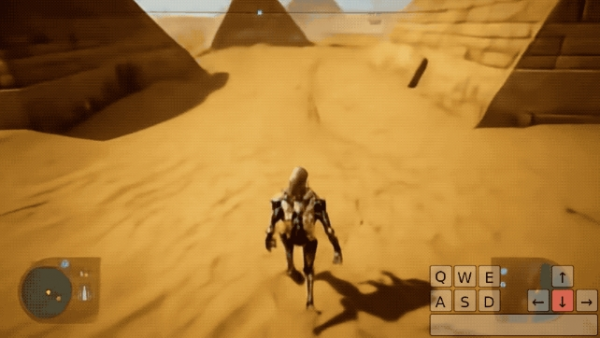
Genie 2's core function lies in training and evaluating embodied agents, generating evaluation tasks unencountered during training through the construction of diverse environments.
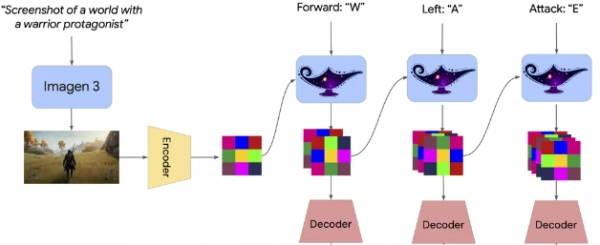
It operates by performing [pixel prediction] frame by frame and utilizing user-provided [guidance] to adjust the probability distribution for the next frame.
Genie 2 boasts the [emergent ability to construct a foundational world model], enabling it to create rich and diverse 3D worlds and simulate the outcomes of various actions (e.g., jumping, swimming) performed within these virtual worlds.
Genie 2 allows users to construct their ideal worlds through [text] descriptions, select preferred [renderings], and then enter these newly created worlds for [interaction] or have AI agents [train or evaluate] within them.
The model can construct interactive 3D environments from a single image, providing up to one minute of immersive gaming experiences, integrating advanced features such as physical simulation, lighting effects, and NPC behavior.
Google positions Genie 2 as a research and prototyping tool capable of rapidly building rich environments, simplifying AI evaluation even without specialized training.
Tech Giants Enter the World Model Competition
At CES 2025, Jensen Huang announced the launch of Cosmos World Foundation Models (Cosmos WFMs), designed to understand the physical world and predict/generate video content with [physical awareness].
In addition to NVIDIA, Google, and several startups are actively pursuing the development of World Models.
Li Feifei's World Labs has raised $230 million to build [large world models], while companies like Decart and Odyssey have also ventured into this field.
OpenAI's previously released Sora model can also be considered a [world model], capable of simulating behaviors such as a painter working on a canvas and rendering user interfaces and game worlds akin to Minecraft.
World Models are trained on vast amounts of image, audio, video, and text data to construct internal representations of how the world works and reason about the consequences of actions, enabling a deeper understanding and simulation of real-world laws.

The concept of World Models stems from the mental models formed by the human brain, integrating abstract sensory information into concrete understandings of the surrounding world, forming [models] that aid in predicting and perceiving the world.
World Models distinguish themselves by attempting to transcend mere data and simulate human subconscious reasoning.
For instance, a baseball batter decides how to swing the bat within a fraction of a second, instinctively predicting the ball's trajectory.
This subconscious reasoning ability is considered crucial for achieving human-level intelligence.
The significance of [World Models] lies in their ability to enable complex reasoning and planning, driving the development of generative video technology.
Meta's Chief AI Scientist Yann LeCun believes that World Models may play a role in complex prediction and planning in both digital and physical domains in the future.
For example, given a messy room (initial state) and a tidy room (goal state), World Models can reason through a series of cleaning actions rather than operating solely based on observed patterns.
With these capabilities, [World Models] have broad applications in industries such as film and television, gaming, autonomous driving, and robotics.

Conclusion:
Future World Models may generate 3D worlds on demand for gaming, virtual photography, and other purposes, significantly reducing development costs and time.
Over the past year, AI technology has continued to make breakthroughs in multiple directions, with World Models emerging as the next frontier.
While it may take several years for mature [World Models] to materialize, this technology has already demonstrated immense potential.
References:
- DeepTech: "Google Adjusts AI Team Again, Nobel Laureate Hassabis Leads R&D"
- Quantum Bit: "Sora Core Author at the Helm, Google's New World Model Team Recruiting Globally"
- Media No.1: "Google DeepMind's [World Model] May Be a Breakthrough for AGI"
- AI Technology Camp: "Former Sora Leader Leading the Creation of [Real-World Simulator], Stirring Up the AI Field Again"
- Tencent Technology: "Li Feifei's World Generation Model Under Hot Discussion: Can It Really Construct the Physical World?"
- AI Tinkering: "DeepMind Releases the "GPT Moment" of World Models, Genie2 May Disrupt the Gaming Industry"
- Hard AI: "[World Models] - The Next [Battleground] for AI, with NVIDIA and Google Both Entering the Field"
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





