Navigating the Hallucination Wilderness: The RAG Off-road Race for Large Models
 01/29 2025
01/29 2025
 749
749

In early 2025, the competition within the realm of large models remains fierce, with short sprints focused on cost advantages and token invocation volume, and long-distance races emphasizing slow thinking and large model reasoning abilities. However, amidst these 'classic events,' we must also pay attention to another ongoing competition that holds critical importance for the future of the large model industry—the RAG Off-road Race.
RAG stands for Retrieval-Augmented Generation. As its name implies, RAG combines the generative capabilities of large language models with the information retrieval abilities of search engines, becoming a staple feature of mainstream large models.

The term "off-road race" is used to describe RAG because the most frequently questioned issue with large models is the occurrence of hallucinations—obvious errors in the generated content. These hallucinations serve as towering mountains blocking the evolutionary path of large models.
The strategic value of RAG lies in its role as a core solution to overcome these hallucinations. In other words, the winner of the RAG Off-road Race will address the core pain points of large models and usher AI into a new era.
Let's embark on the RAG track for large models and explore where this off-road race will take AI.

Recall the first time you encountered a large language model. When you initially tried chatting with one, besides being amazed, did you sense something was amiss?
This discomfort likely stems from three issues with large models:
1. Nonsensical content. During conversations, we often find that large models say things that obviously do not align with common sense, such as 'Lin Daiyu's brother is Lin Chong' or 'Lu Zhishen is a French literary figure.' This is due to the operating principle of LLM models, which can lead them to generate content solely for the sake of generation, regardless of the accuracy of the information. This is the widely criticized hallucination of large models. The industry generally believes that without eliminating hallucinations, large models will remain toys rather than tools.
2. Outdated information. Another issue with large models is their slow knowledge base updates, making it impossible for them to answer questions about recent news and real-time hot topics. However, the main problems we face in work and life are time-sensitive, significantly reducing the practical value of large models.

3. Lack of evidence. In another scenario, a large model provides answers, but we cannot ascertain the authenticity and reliability of these answers. Since we know hallucinations exist, we may doubt the answers provided by AIGC. We would prefer if large models could annotate the source of each piece of information, like a research paper, thereby reducing the cost of verification.
These issues can be collectively referred to as the 'Wilderness of Hallucinations.' The best way to traverse this wilderness is to integrate the understanding and generation capabilities of large models with the information retrieval of search engines.
Information retrieval can provide large models with timely information and indicate the source of each piece of information. With the support of the information base brought by retrieval, large models can avoid generating 'nonsense.'
Retrieval is the method, and generation is the goal. Through high-quality retrieval systems, large models have the potential to overcome hallucinations, their biggest challenge.
Thus, RAG technology emerged.

On the RAG track, the quality of retrieval significantly impacts the final generated output of the model. For instance, Baidu's accumulation in the field of Chinese search has resulted in advancements in corpus, semantic understanding, and knowledge graphs. These advancements help improve the quality of Chinese RAG, enabling faster implementation of RAG technology in Chinese large models. In the search engine domain, Baidu has built an extensive knowledge base and real-time data system, with a focus on vertical domains requiring professional retrieval.
In fact, bringing the accumulation from the search domain to the large model domain in a timely manner is not easy. As we all know, search results for humans are not suitable for large models to read and understand. To achieve high-quality RAG, it is necessary to find an architectural solution that can efficiently support both search business scenarios and large model generation scenarios.
Baidu first proposed retrieval augmentation when it launched ERNIE Bot in March 2023. As large models have evolved, retrieval augmentation has become an industry consensus. Baidu's retrieval augmentation integrates large model capabilities with search systems, constructing a 'understand-retrieve-generate' collaborative optimization technology that enhances model technology and application effectiveness. Simply put, in the understanding phase, the large model understands user needs and disassembles knowledge points. In the retrieval phase, search ranking is optimized for large models, and the heterogeneous information returned by the search is uniformly represented and sent to the large model. In the generation phase, information from different sources is comprehensively evaluated, and based on the large model's logical reasoning ability, issues such as information conflicts are resolved, thereby generating answers with high accuracy and timeliness.
In this way, RAG has become a core differentiated technology path for Baidu's ERNIE Bot. It can be said that retrieval augmentation has become a hallmark of ERNIE Bot.
Let's ask a random question and test it out.
Today, most mainstream large models offer RAG experiences, such as informing users how many webpages the model has accessed and where the retrieved information comes from. However, there is still a significant gap in this off-road race. To determine the ranking, simply ask each large model the same question.
For example, as the Spring Festival approaches, temple fairs are an essential part of Beijing's celebrations. With many temple fairs during the Spring Festival in Beijing, friends will surely want to know which one suits them best and what their operating hours are.
Therefore, I asked 'Which Beijing Spring Festival temple fair is more recommended? What are their operating hours?' to Baidu's ERNIE Bot, Doubao, Kimi, DeepSeek, etc. Here, we used the paid version of ERNIE Bot, ERNIE Bot 4.0 Turbo.
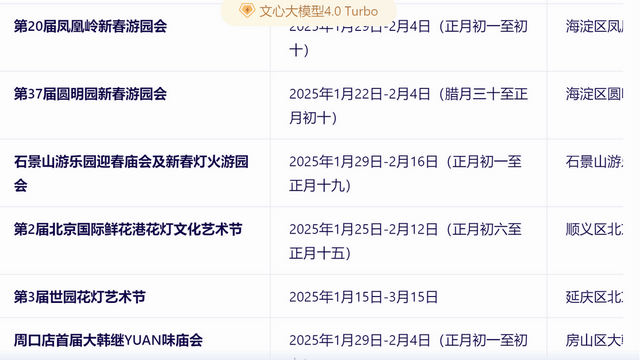
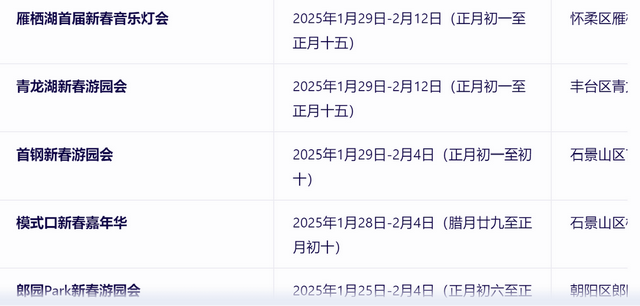
ERNIE Bot's answer is as follows. First, it combines retrieved information to recommend dozens of Beijing Spring Festival temple fairs and lists the location, time, and other information for each one.


But that's not all. ERNIE Bot then provides a summary.


As can be seen, ERNIE Bot understood my question about 'the most recommended' and provided numerous options while mainly recommending the Dongyue Temple Fair, Ditan Temple Fair, Niangniang Temple Fair, and Shijingshan Amusement Park Temple Fair, along with corresponding reasons for the recommendations. It achieved a balance between comprehensive information and personalized recommendations.
When asking the same question to Doubao, the answer is also quite good but lacks completeness in content.

Doubao's answer categorizes which temple fair each type of enthusiast should visit, providing information on a total of seven temple fairs. However, it's worth noting that Doubao's answer is not detailed enough in terms of the number of temple fairs and the introduction of each temple fair's characteristics. Additionally, Doubao does not provide a summary, which does not meet the question's demand for 'which is the most recommended.'
Asking the same question to Kimi presents a different scenario.

For some reason, Kimi's answer only mentions the Chandian Temple Fair and does not mention any other temple fairs. While this does meet the demand for 'the most recommended,' it is overly one-sided and arbitrary, failing to provide users with a complete understanding of Beijing's Spring Festival temple fairs.
Asking the same question to the recently popular DeepSeek R1 large model reveals that it can also perform deep online retrieval with RAG and provides a thinking process, ultimately recommending information on 10 temple fairs.


The only slight drawback is that it ultimately only provides basic information on a few temple fairs, failing to respond to the question of which temple fair is 'most recommended.' Additionally, its thinking process is somewhat lengthy, and the reading experience could be improved.
It is evident that for the timely and practical question of 'which temple fair to visit during the Spring Festival this year,' the answers provided by several large models are generally acceptable but still have differences. Behind this lies the disparity in RAG technological capabilities.
In terms of RAG capabilities alone, ERNIE Bot excels in retrieval augmentation, especially for question-and-answer-type demands like the above. Additionally, we can see that ERNIE Bot utilizes table tools to structure and present the results. Overall, ERNIE Bot performs well in deep thinking and tool invocation.
It is clear that retrieval augmentation has a significant impact on the practicality and user experience of large models.

The continuation of the RAG Off-road Race may bring new surprises to the entire digital world.
For example, RAG could be:
1. A new engine for search engines. Allowing large models to understand information retrieval will also inversely bring new development momentum to search engines, better satisfying users' fuzzy searches, question-based searches, and multimodal searches.
2. A new fulcrum for large language models. Large models must not only generate content but also generate credible, reliable, and real-time content. To achieve these goals, RAG is a proven core direction.

3. A ticket to the future. Pre-trained large models are just the beginning of the story, and the climax lies in the endless possibilities of creating AI-native applications. The convergence and fusion of understanding, generation, and retrieval—these core digital intelligence capabilities—may truly reveal the underlying logic and future form of AI-native applications.
The value of basic models is demonstrated through applications. Many people are curious about what the core carrier of AI-native applications should be in this era.
Perhaps, the combination of understanding, retrieval, and generation is the direction.
Or perhaps, the answer lies at the end of the RAG Off-road Race.

-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





