Decoding DeepSeek's Innovations in One Comprehensive Article
 02/07 2025
02/07 2025
 548
548
Happy New Year, everyone!
During the Spring Festival, DeepSeek and its AI large models gained immense popularity. While praise abounds for DeepSeek and its models, few delve into the specifics of its innovations. Today, let's explore what sets DeepSeek apart.

Previously, it was widely believed that computing power was the cornerstone of AI development, with continuous stacking of computing power and GPUs being the norm. The rise of OpenAI not only benefited NVIDIA but also propelled anything AI-related into the limelight. Even the US restricted the sale of NVIDIA GPUs to curb China's AI progress.
Yet, amidst the computing power race, DeepSeek chose to focus on algorithm innovation. Let's delve into DeepSeek's innovations (please correct me if I'm wrong):
1. **DeepSeek-V2: A Breakthrough in Efficiency and Cost-Effectiveness**
DeepSeek-V2 marked DeepSeek's first significant breakthrough by forcing domestic large model vendors to lower their prices. How did it achieve such low prices?
To achieve efficient inference and cost-effective training, DeepSeek-V2 introduced two major innovations: the DeepSeekMoE architecture and Multi-head Latent Attention (MLA). These innovations address key bottlenecks in the Transformer architecture, paving the way for DeepSeek-V2's success.
What is MoE Architecture?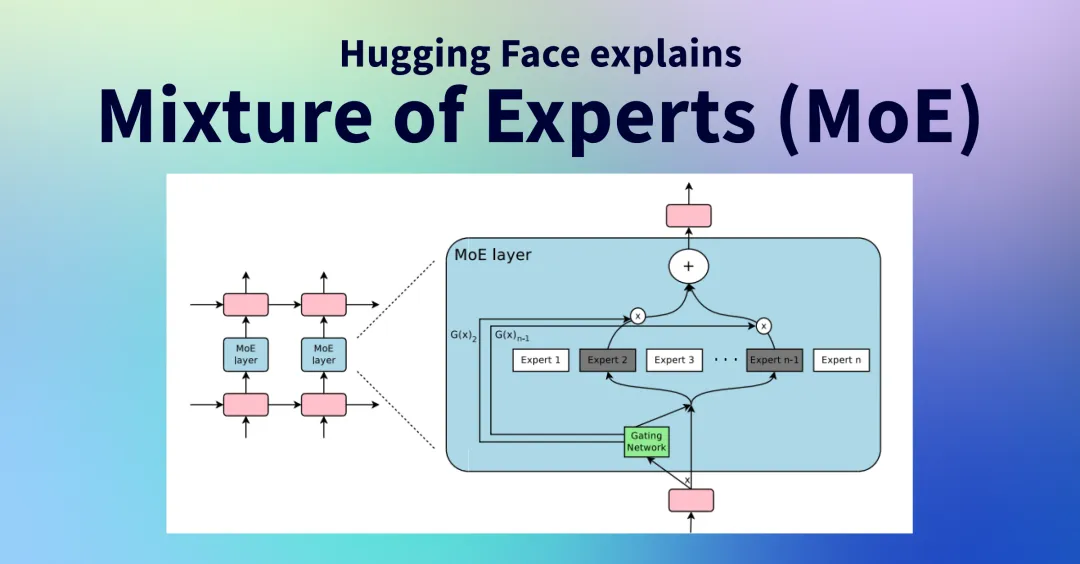
While dense large models are the mainstream abroad, DeepSeek-V2 abandoned this approach and adopted the Mixture of Experts (MoE) route. Dense models suffer from large parameter counts and high hardware consumption, leading to high prices. MoE, on the other hand, comprises multiple sub-models (experts), each specializing in processing a subset of the input space.
This approach transforms a dense large model into many sparse expert sub-models, achieving comparable capabilities through model aggregation. By switching to MoE, DeepSeek-V2 significantly reduces the number of activated parameters and enhances performance.
Think of it like this: traditional large models are like restaurants with a few top chefs skilled in all cuisines. When faced with complex dishes, they become overwhelmed. MoE models, however, hire more chefs, each specializing in different cuisines. The model intelligently assigns dishes to the most suitable chef, improving efficiency and reducing waste.
Someone might ask, if MoE is so good, why aren't foreign large models using it?
The main issue is load balance, leading to unstable training. Expert parallelism, where different experts are placed on different GPUs to accelerate training, can cause some experts to have more computations, leading to inefficient GPU utilization for others. DeepSeek-V2 introduced additional loss functions (device-level balance loss and communication balance loss) to allow the model to autonomously control the balance between devices during training, addressing this challenge.
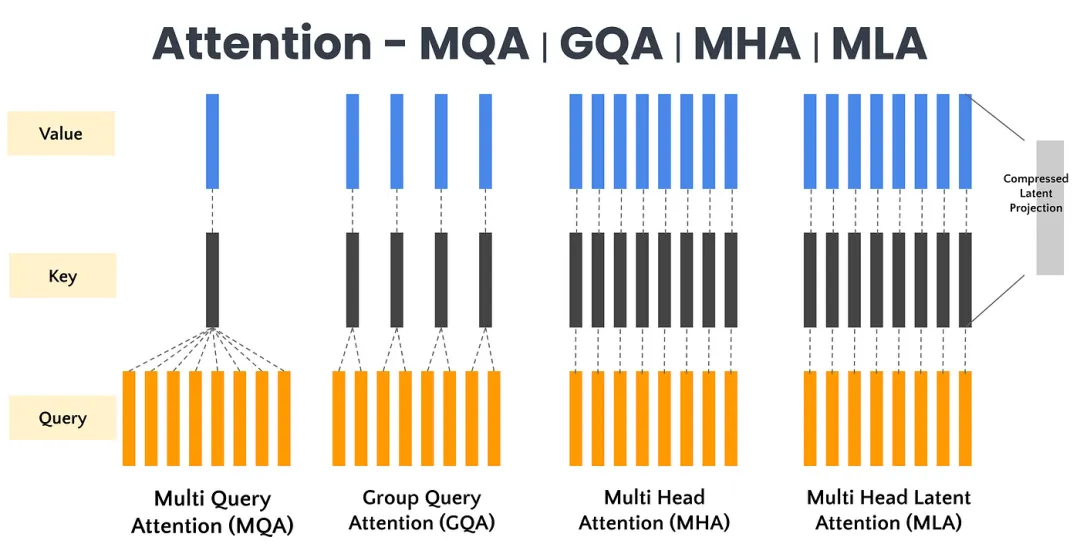
Another key innovation is MLA (Multi-Head Latent Attention).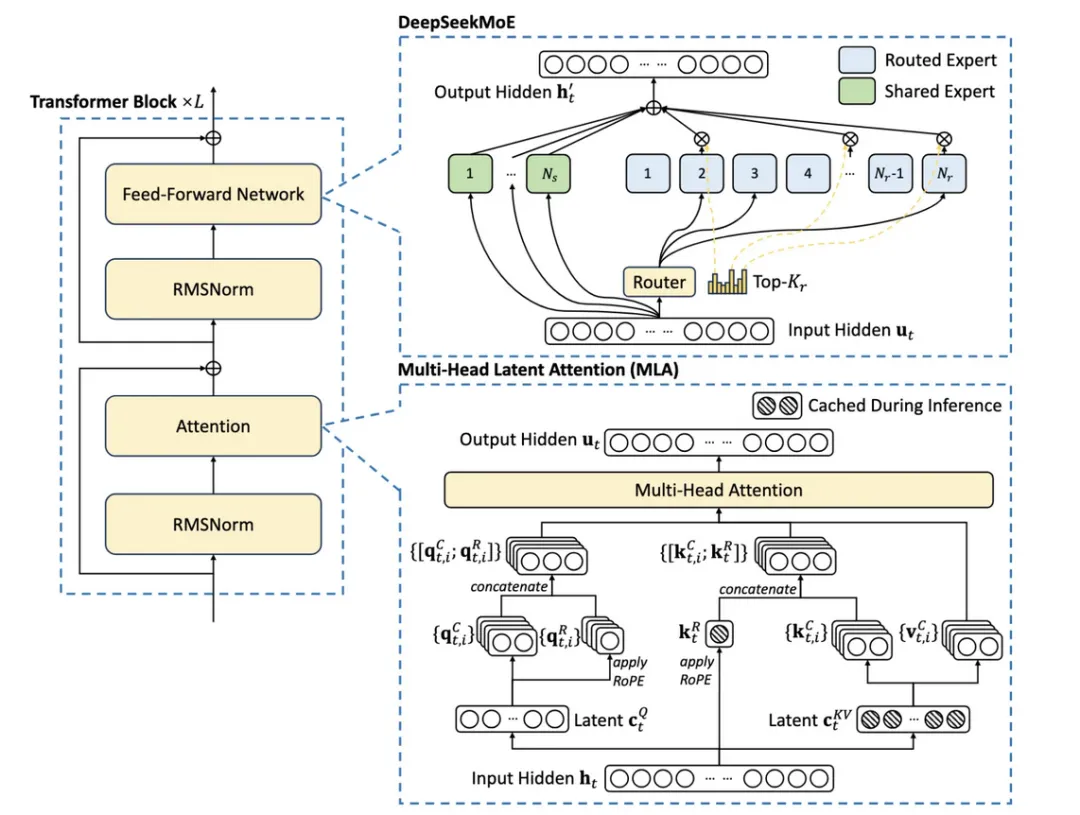
In large models, each token (roughly a word) is generated, and each token is only related to previous tokens. Without optimization, generating each token requires processing all previous tokens, leading to inefficiency. The kv-cache technique, a common optimization, stores matrices computed during previous generations for reuse. However, this requires additional video memory, especially for long contexts.
MLA addresses this by compressing key-value pairs into a latent vector through low-rank joint compression, significantly reducing cache capacity and computational complexity. This ingenious idea, conceived by a researcher on a whim, took several months to implement.
Using the restaurant analogy again, traditional models are like restaurants with many waiters handling orders, serving dishes, and cleaning independently. This can lead to inefficiencies. MLA technology allows waiters to share a smart tablet, synchronizing orders and statuses in real-time, improving efficiency and quality.
2. **DeepSeek-V3: Extending the Frontier with Multi-Token Prediction**
Released in December 2024, DeepSeek-V3 garnered significant attention. Like DeepSeek-V2, it employs MoE architecture and MLA technology but introduces the Multi-Token Prediction (MTP) mechanism.
Traditional large models (LLMs) have a decoder-based structure, generating sequences token-by-token during training and inference. This memory-intensive process often becomes a bottleneck. To address this, the industry has adopted various optimization methods.
DeepSeek-V3's MTP mechanism establishes interconnections between multiple simultaneously generated tokens, improving data utilization and pre-planning for better generation results. It's like waiters suggesting desserts and drinks immediately after the main course, enhancing the overall service experience.
Besides architectural upgrades, DeepSeek-V3's low costs are attributed to optimized training methods. While most large models use BF16 precision training, DeepSeek-V3 natively uses FP-8 precision, about 1.6 times more efficient. Extensive optimization of underlying operations stabilizes FP8 training, contributing to DeepSeek-V3's extremely low costs.
3. **DeepSeek-R1: A Paradigm Shift with Reinforcement Learning**
Released in January 2025, DeepSeek-R1's innovation lies in its paradigm shift from supervised finetuning (SFT) to Reinforcement Learning (RL).
RL involves letting the model interact with the environment and scoring the results to train the model. Unlike previous RLHF methods, R1's RL method (Group Relative Policy Optimization, GRPO) does not require a massive human annotation database. The model generates by itself and is checked for correctness at the end.
This RL method, applied to V3, endows the new model with reasoning ability. As training steps increase, the model's Chain-of-Thought (CoT) grows, and it starts to self-reflect during reasoning. R1-Zero, trained purely through RL, initially had no Go knowledge but eventually surpassed humans through exploration. However, its CoT was imperfect, so DeepSeek used it to generate "cold start samples" and performed SFT on V3 to obtain a preliminary reasoning model. Further application of GRPO-based RL and dataset merging resulted in R1.
R1 proves that a sufficiently capable base model (like V3) can learn to reason on its own during RL. This astonished the foreign AI community, suggesting that AGI is closer than we thought.
4. **Model Innovation: Focusing on Vertical Scenarios**
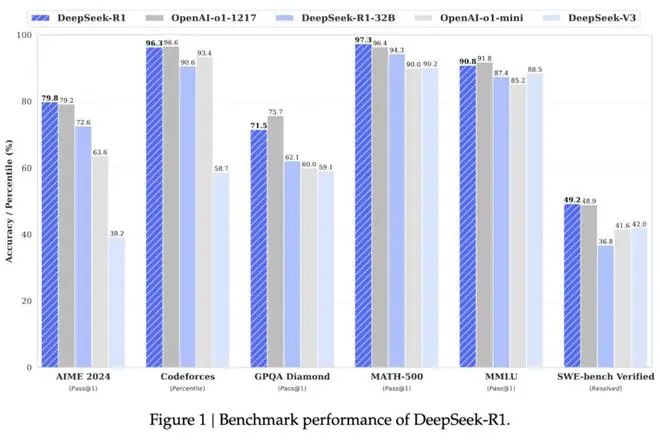
According to DeepSeek's benchmark data, DeepSeek-R1, which extensively uses reinforcement learning, rivals OpenAI o1's official version in math, code, and natural language reasoning tasks at just 3% of the price. This doesn't mean DeepSeek-R1 surpasses OpenAI o1, which prioritizes "general intelligence." Instead, DeepSeek chooses to focus on vertical scenarios, aiming for superior performance in specific areas before gradually improving others.
In the author's opinion, China's large model enterprises don't need to focus solely on "all-around large models." They can choose vertical scenarios for targeted growth, avoiding the computing power race and building data moats to break through in sub-fields.
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





