DeepSeek's Challenge to Wall Street Sparks Widespread Ripple Effects
 02/07 2025
02/07 2025
 543
543
Preface:
Traditional AI training demands immense computing power, with NVIDIA's chips serving as the linchpin of this technological backbone.
However, the advent of DeepSeek has compelled the market to reassess, revealing that AI's computing power requirements are less colossal than initially anticipated.
Author | Fang Wensan
Image Source | Network
DeepSeek Paves New Paths for Large Models
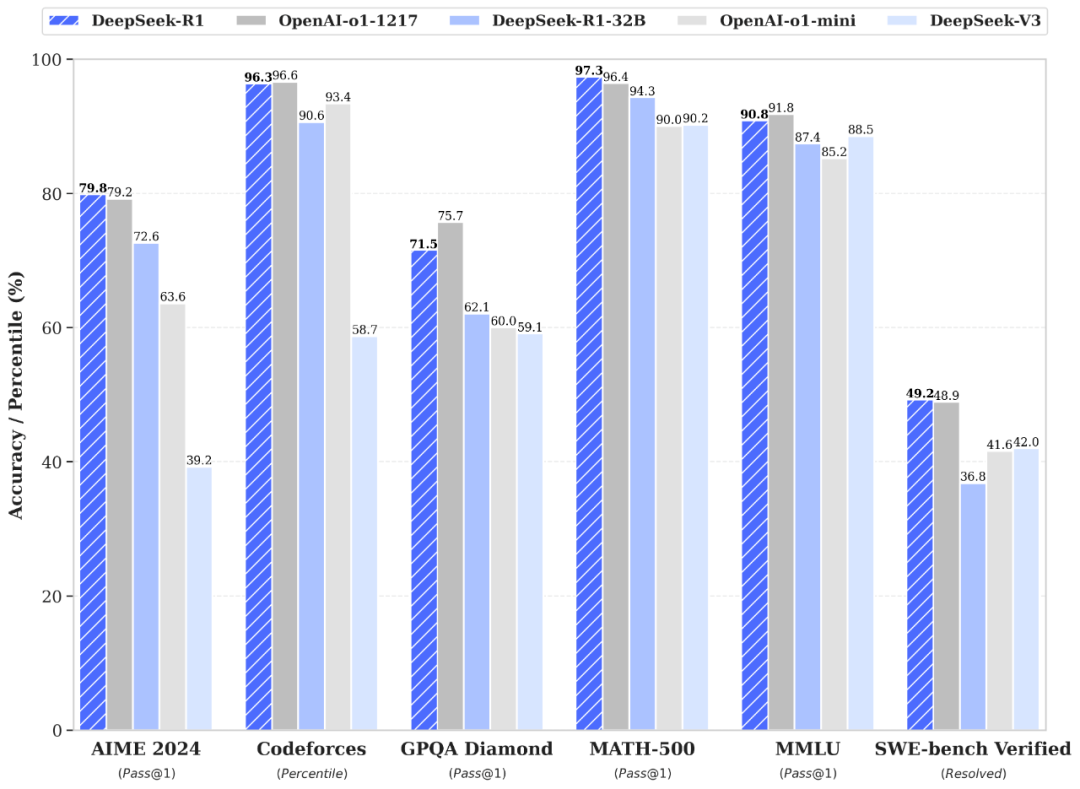
On January 20, 2024, DeepSeek Inc. unveiled the full version of its inference model, DeepSeek-R1.
This model achieves performance on par with OpenAI's GPT-4 at a fraction of the training cost, while being entirely free and open-source, stirring significant industry buzz.
Many developers express intent to leverage DeepSeek technology to overhaul their existing systems.
This trend propelled DeepSeek's mobile apps to swift popularity, soaring to the top of the U.S. Apple App Store's free app rankings within a month of their release, outpacing both ChatGPT and other popular apps.
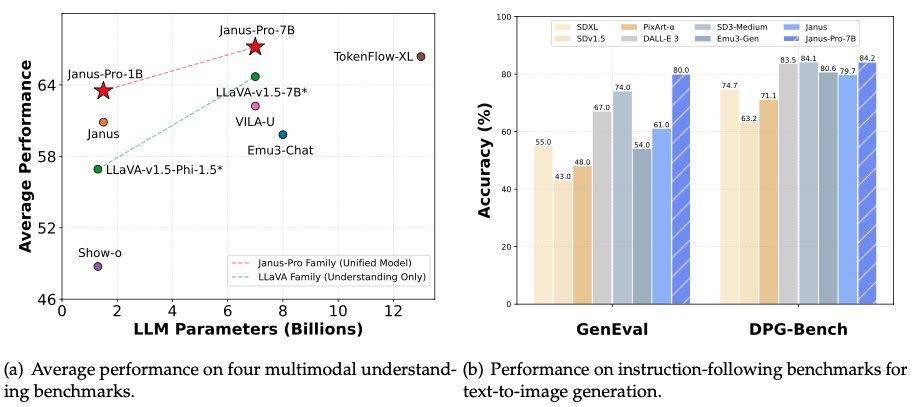
On January 28, 2025, DeepSeek further open-sourced its multimodal model, Janus-Pro-7B, claiming superiority over DALL-E 3 (by OpenAI) and Stable Diffusion in GenEval and DPG-Bench benchmarks.
Comparative analysis reveals that while DALL-E 3 boasts 12 billion parameters, Janus Pro's large model comprises just 7 billion parameters.
The release of R1 not only shattered the industry norm of tech giants monopolizing flagship open-source models but also overturned last year's consensus that general-purpose large models were evolving into a capital competition arena for large enterprises.
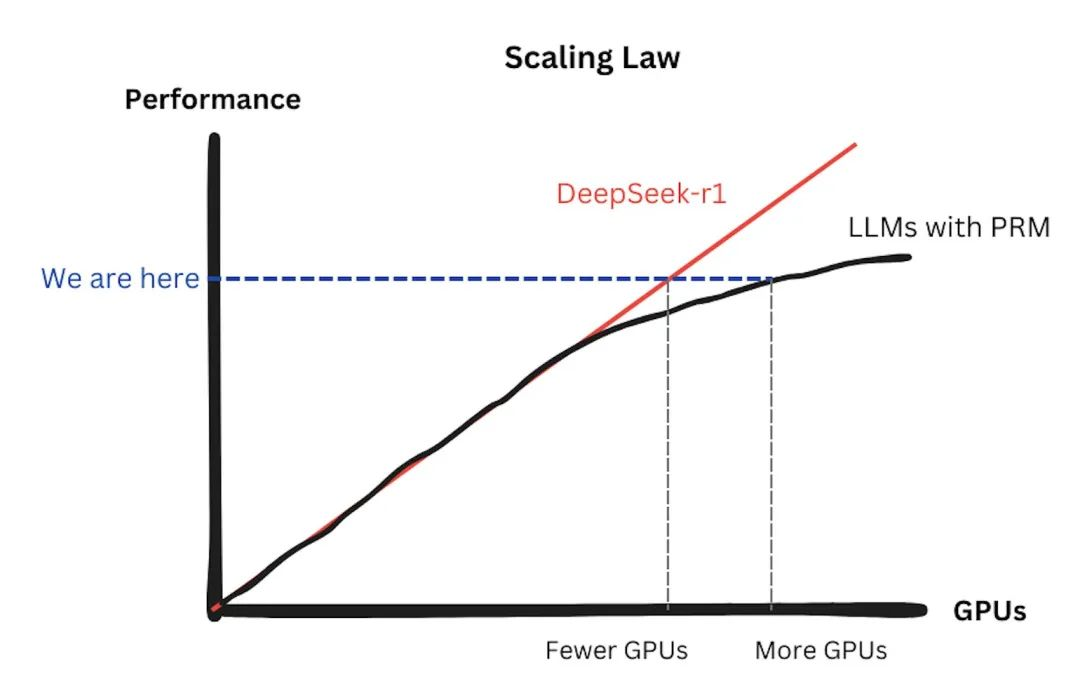
Hardware media Tom's Hardware published the year's most talked-about report: DeepSeek bypassed CUDA, opting instead for more fundamental programming languages for optimization.
The core technical divergence between DeepSeek R1 and OpenAI GPT-4 lies in its innovative training methods, such as the R1-Zero method, which directly applies reinforcement learning (RL) to the base model without relying on supervised fine-tuning (SFT) or labeled data.
According to DeepSeek's official technical documentation, the R1 model employs high-quality data generated by data distillation technology to enhance training efficiency.
Data distillation involves processing raw, complex data through algorithms and strategies to denoise, reduce dimensions, and refine it, yielding more refined and useful data.
This is the crux of DeepSeek's ability to match OpenAI GPT-4's performance with fewer parameters.
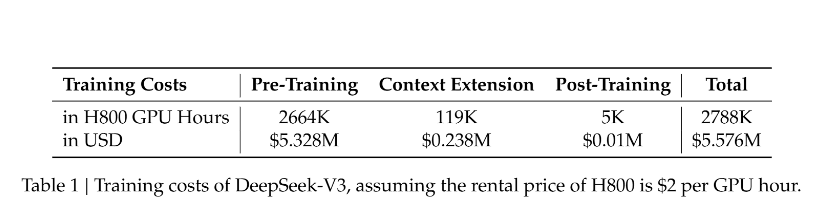
DeepSeek is not a conventional tech enterprise but has successfully developed highly innovative models with significantly lower GPU resources and costs compared to large American model companies.
The training cost of its R1 model is merely $5.6 million, an amount that doesn't even equate to the annual salary of any senior executive in Meta's GenAI team.
Behind QuantOpt's Investment Strategy
Liang Wenfeng, the controlling shareholder of two private equity firms with tens of billions in assets—Zhejiang Jiuzhang Asset Management Co., Ltd., and Ningbo QuantOpt Investment Management Partnership (Limited Partnership)—is also the founder of DeepSeek.
After graduating with a major in AI from Zhejiang University's Department of Electronic Engineering, Liang Wenfeng ventured into the fintech industry, not directly related to his field, and has focused on private equity funds and quantitative investment for years.
As a leading private equity firm in quantitative investment, QuantOpt has risen swiftly since its 2015 inception, becoming an industry leader with a management scale once exceeding 100 billion yuan.
As a private equity firm, QuantOpt generates profits through quantitative investment to ensure continuous operation and development, including financing DeepSeek's research and development.
In quantitative investment, the company utilizes advanced strategies combined with AI technology to analyze and model vast financial data, formulating precise investment decisions, and achieving remarkable performance.
In 2016, QuantOpt launched its first deep learning-based trading model, introducing GPUs into trading position calculations.
Since then, Liang Wenfeng has continually expanded the AI algorithm research team, deeply integrating AI into financial investment strategies, gradually replacing all traditional models.
By 2017, QuantOpt announced that its investment strategies were fully AI-driven.
By 2019, QuantOpt became China's first quantitative fund to raise over 100 billion yuan.
QuantOpt began hoarding GPUs in 2019, and by 2021, it was one of only a handful of Chinese enterprises with 10,000 GPUs, uniquely possessing 10,000 NVIDIA A100 chips.
With its growing GPU hoard, QuantOpt established a dedicated AI research company.
In 2019, it launched the Firefly One AI cluster, and in 2021, it invested 1 billion yuan in developing Firefly Two to provide computational support, demonstrating QuantOpt's technical foresight.
Before the U.S. imposed chip sanctions on China in 2022, QuantOpt had already procured NVIDIA chips on a large scale, laying a solid foundation for subsequent product launches.
In July 2023, Liang Wenfeng announced the official entry into the general AI API field, founding DeepSeek. Within just 10 months, by May 2024, DeepSeek had launched its version 2 model.
DeepSeek's establishment signifies QuantOpt's profound transformation from quantitative investment to AI technology.
Through DeepSeek, Liang Wenfeng has not only excelled in AI but also bolstered QuantOpt's technical support in quantitative investment.
As a leading domestic quantitative investment institution, QuantOpt has promoted domestic quantitative investment through machine learning and fully automated quantitative trading since its inception.
With the rapid rise of large AI models in China, there's a saying in the industry: in China, the institution with the most high-performance GPUs is not an AI company but QuantOpt.
QuantOpt, with robust financial resources and a generous approach, supports DeepSeek's model research. Its research insists on open-source code and isn't eager to commercialize findings.
According to DeepSeek insiders, Liang Wenfeng has personally invested in downstream AI application projects that may develop based on the DeepSeek model.
This indicates Liang Wenfeng's early planning to build a small DeepSeek ecosystem in the future.
Potential Impact on Tech Giants Like NVIDIA
American financial magazine Fortune issued a warning, stating that DeepSeek threatens NVIDIA's dominant position in AI.
As mentioned, DeepSeek has launched a new product series using less powerful yet cost-effective chips, pressuring NVIDIA.
Some believe this could prompt other tech giants to reduce NVIDIA premium product purchases.
Kate Lyman, Chief Market Analyst at AvaTrade, told Fortune magazine: [Investors are concerned about DeepSeek's ability to utilize weaker AI chips, potentially affecting NVIDIA's dominance in the AI hardware market, especially considering its valuation heavily relies on AI demand.]
Notably, Tom's Hardware reported that DeepSeek's AI breakthroughs bypassed NVIDIA's CUDA platform, opting for a PTX programming approach akin to assembly language, exacerbating industry concerns about NVIDIA's future.
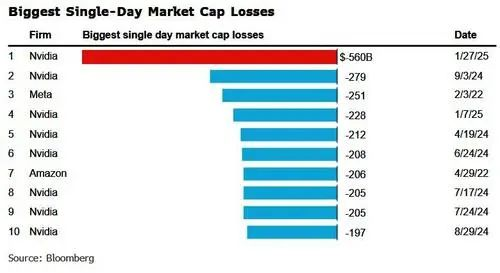
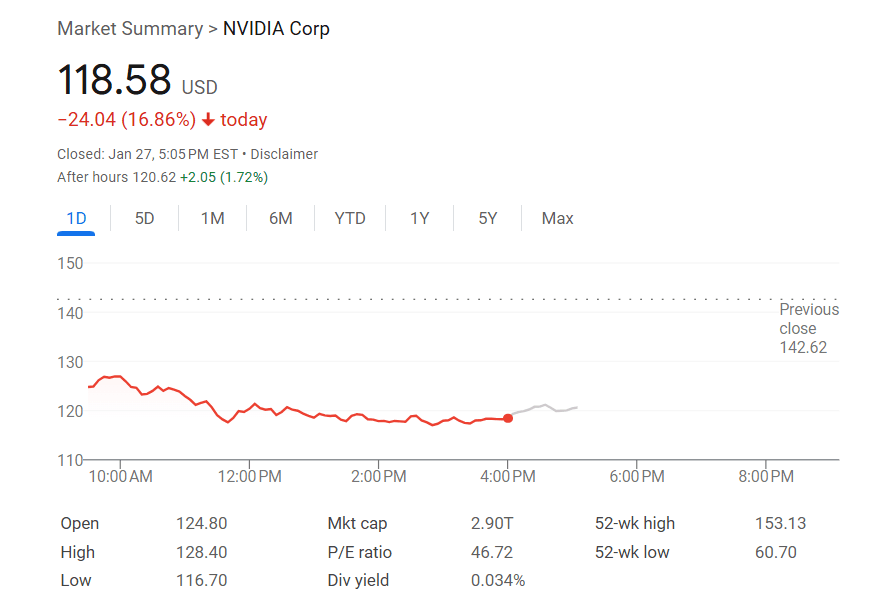
Due to DeepSeek's impact, U.S. chip giant NVIDIA's stock prices plummeted by about 17% on the day, with Broadcom's stock falling 17%, AMD's by 6%, and Microsoft's by 2%.
American United Energy's stock fell by 21%, while Vistra's stock plunged by 29%.
QuantOpt, a quantitative investment-focused company, has long recognized the potential bubble in AI computing power demand.
Traditional AI training demands immense computing power, with NVIDIA chips as the core.
However, DeepSeek's emergence has shown that AI's computing power requirements are less than expected.
DeepSeek's open-source aim is to prove that AI actually requires just one-tenth of the original computing power.
This further heightens the risk of NVIDIA's stock price decline.
If DeepSeek falls short of expectations or market reaction is underwhelming, NVIDIA's stock price may not fall and might even rise.
From a technical competition standpoint, if DeepSeek's low-cost, high-efficiency path is widely adopted, it could reduce reliance on NVIDIA's high-end GPUs, theoretically motivating QuantOpt to short-sell NVIDIA for profit.
However, QuantOpt has previously hoarded tens of thousands of NVIDIA A100 and H800 chips, crucial for its research, and has a cooperative relationship with NVIDIA, presenting contradictions in short-selling.
While there's no clear evidence of QuantOpt short-selling NVIDIA, DeepSeek's technological breakthroughs' potential impact on NVIDIA's market position has garnered widespread attention.
According to Securities Times China, Morgan Stanley's latest report significantly reduced its 2025 expected shipments of NVIDIA's GB200 from 30,000-35,000 units to 20,000-25,000 units, with the most pessimistic forecast at less than 20,000 units.
This downward adjustment could impact the GB200 supply chain market by $30-35 billion, pressuring related supply chains and the semiconductor industry.
Morgan Stanley noted market disputes over large language model (LLM) efficiency, like differences between DeepSeek and Microsoft, expected to continue in 2025, complicating stock value reassessments.
Furthermore, based on cyclical patterns, cloud computing's capital expenditure growth rate may slow to single digits in Q4 2025.
However, Morgan Stanley predicts this growth cycle might continue into H1 2025 if historical patterns repeat.
As the market nears the cycle's peak, the year-on-year growth rate is expected to slow to single digits in Q4 2025.
Investors' overly optimistic GB200 supply chain stock growth expectations may negatively impact high-P/E cloud computing stocks.
Conclusion: The Path of Technological Innovation is Expected to Have an Impact
①AI startups' operating models will transform: AI enterprises reliant on costly GPU clusters may face bankruptcy due to cost disadvantages.
This will increase second-hand GPU supply, with small and medium-sized AI enterprises preferring cheaper, lower-end GPUs.
②Hardware demand will undergo structural changes: Since last year, training-focused computing power demand has shifted towards inference.
This trend is expected to continue, with many small and medium-sized AI enterprises adopting open-source models like DeepSeek instead of training base models.
Additionally, NVIDIA's training market dominance will face reassessment.
Some references: Geek Park: "DeepSeek Pulls Off Another Combo: Just Released a Multimodal Model Surpassing DALL-E3", LetterRank: "DeepSeek Overturns Two Mountains", Quantum Bit: "[DeepSeek Even Bypassed CUDA], Engineers Ask: Is NVIDIA's Moat Still There?", Meta Finance: "About QuantOpt Private Equity: When AI Algorithms Enter the Quantitative World, Painlessly [Winning Without Doing Much]?", Private Equity Ranking Network: "How is the Performance of the Billion-Dollar Private Equity Tycoon Behind DeepSeek?", Economic Observer: "Lei Jun is Even Poaching Talent, This Company Wants to Hide 1% of AI Geniuses", Semiconductor Industry Observer: "The Chip Behind the DeepSeek Miracle Sounds the Alarm for NVIDIA", Shell Finance: "The Rise of DeepSeek, the Plunge of NVIDIA", Wall Street Journal: "Is DeepSeek the Strongest Domestic Weapon? NVIDIA Lost Nearly 4.3 Trillion", Jiazi Guangnian: "NVIDIA's Market Value Evaporation Sets a Record, What Does the AI Computing Power Revolution Initiated by DeepSeek Mean?"
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





