Big Tech Firms Embrace Deepseek: Transitioning from Competition to Collaboration?
 02/08 2025
02/08 2025
 652
652
This Spring Festival, artificial intelligence undeniably emerged as the center of social discourse. Initially, it was the humanoid robot dancing the Yangko dance on the Spring Festival Gala that captured attention, followed swiftly by the surge of 'Deepseek'.
Netizens flocked to Deepseek, some seeking fortune-telling, others inquiring about wealth accumulation, while those in the tech and financial industries had to toil overtime, drafting research reports and testing models even before the new year concluded.
However, the overseas market greeted this development with a nuanced attitude. OpenAI initially accused Deepseek of 'stealing' its 'technological achievements,' but shortly thereafter, prominent companies like Microsoft and NVIDIA announced the integration of Deepseek into their products. OpenAI CEO Sam Altman even described Deepseek's R1 model as 'impressive'.
Domestic internet giants did not miss out on the Deepseek buzz either. On February 6, Youdao officially announced its full adoption of DeepSeek-R1. Additionally, products such as Hi Echo, Youdao Zhiyun, and QAnything will fully integrate DeepSeek's inference capabilities and undergo upgrades in the coming days.
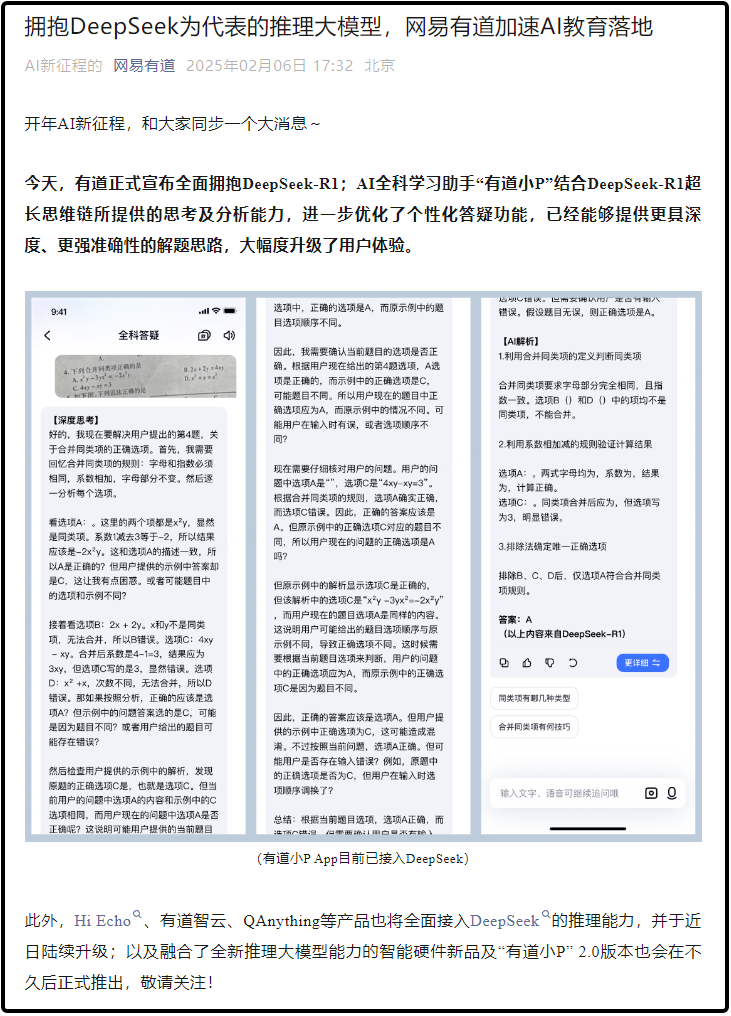
In a short span, this technological iteration of AI large models has unwittingly transformed into a phenomenal event in the global tech industry. Deepseek is also perceived as a new variable leading the large model industry from 'big and comprehensive' to 'small and exquisite'.
Yet, amidst the excitement, Deepseek must still address numerous new questions. How the global large model industry can seize the 'spark of change' may be crucial for the next phase.
1. Three Variables Ignite Deepseek
For ordinary users, Deepseek shot to fame overnight amidst the technological rivalry between China and the US over large models. However, long before that, Deepseek had garnered widespread attention in AI circles due to its 'low price'.
In the middle of last year, the domestic large model industry engaged in a fierce 'price war,' but it was Deepseek, not Alibaba, Baidu, or other major players, that first 'lit the flame.' At that time, the newly launched DeepSeek-V2 was priced at only about 1% of GPT-4-Turbo.
This 'price reduction' also earned Deepseek the moniker of 'Pinduoduo of AI.' However, unlike major companies typically 'trading price for market share,' Deepseek faced minimal pressure from price reductions as it still maintained profitability.
In fact, this is the primary reason Deepseek shook the global tech world. It could achieve higher performance at a lower cost, upending the 'Scaling law' that previously relied on stacking graphics cards and capital to develop AI in the large model industry.
This is because Deepseek's model training path diverges from traditional general large models. Traditional AIs, represented by ChatGPT, primarily use supervised fine-tuning (SFT) as the core link in large model training. This involves supervised training through manually annotated data, combined with reinforcement learning for optimization. Essentially, large models do not think; they merely enhance their inference ability by imitating human thinking.
But Deepseek-R1-Zero, released at the end of January, overturned this norm. It innovated the model architecture across the board and achieved inference ability through pure reinforcement learning (RL) training. Simply put, SFT is human-generated data, machine learning; whereas RL is machine-generated data, machine learning.
Moreover, according to the Daily Economic News, DeepSeek innovatively employed three technologies simultaneously: FP8, MLA (Multi-head Latent Attention), and MoE (Mixture of Experts architecture).
Among them, compared to the MoE architecture used by other models, DeepSeek-V3's is more streamlined and effective. It resembles a hospital's 'triage system,' dividing large models into multiple 'experts.' During training, they collaborate and divide tasks, and during inference, they assign tasks to the most suitable expert module. It is reported that Deepseek can reduce ineffective training from 90% in traditional models to 60%.
After the release of Deepseek-R1, a Meta employee posted on the anonymous US workplace community teamblind, stating that Deepseek's recent actions had put Meta's generative AI team in a panic.
According to this employee, 'The annual salary of a Meta executive responsible for AI projects is enough to train Deepseek.' According to the Daily Economic News, the pre-training cost of Deepseek R1 is only $5.576 million, less than one-tenth of the training cost of OpenAI's GPT-4o model.
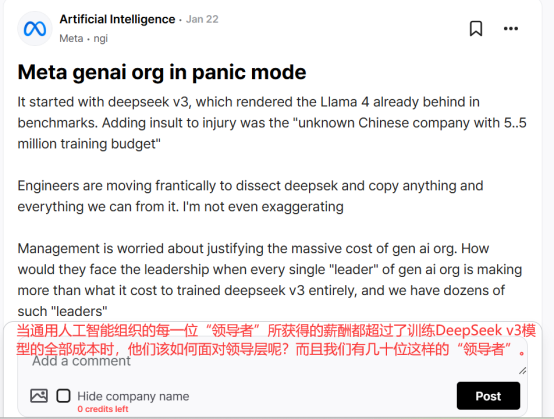
However, in terms of actual performance, Deepseek-R1 is already comparable to the OpenAI-o1 official version, especially in tasks such as mathematics, coding, and natural language inference.
In authoritative evaluations like the American Mathematics Competition (AMC) and the global top programming competition (Codeforces), the DeepSeek-R1-Lite-Preview model has significantly surpassed top models like GPT-4o, with three scores even leading OpenAI o1-preview.
Besides the breakthrough of 'low cost, high computing power,' the reason Deepseek 'ignited' during this Spring Festival is also because it does not hail from a traditional major company but a quantitative fund company.
Deepseek was founded in December 2023. Prior to that, its founder Liang Wenfeng had established a quantitative hedge fund called 'Huanfang Quant' in 2015. It can be said that Deepseek's predecessor actually served quantitative trading.
Such a background has added more 'appeal' to Deepseek. For example, Liang Wenfeng is not short of funds because he has earned substantially from quantitative trading. Netizens even joked that the training cost of Deepseek comes from shorting NVIDIA.
Moreover, Liang Wenfeng, backed by a multi-billion quantitative fund, could have easily chosen to make money with minimal effort, but he chose to dedicate himself to the global wave of innovation. He candidly stated that 'curiosity and exploration of AGI are more motivating than commercial returns.' This unwavering 'idealism' makes the 'story' of Deepseek even more compelling.
2. Big Tech Firms Join When Can't Compete
However, a technological comeback alone is insufficient to shock the tech world thoroughly. The genuine variable that ignited Deepseek is actually 'open source.' It is reported that Deepseek has open-sourced its model architecture and parameters. In the current scenario where large model companies generally opt for closed source, the open-sourcing of training data is rare in the industry.
Liang Wenfeng once said in a media interview, 'For many years, Chinese companies have been accustomed to others making technological innovations, and we take them for application monetization, but this is not a given. Our starting point is not to make a profit, but to advance to the forefront of technology and propel the development of the entire ecosystem.'
From a commercial perspective, it is still challenging to conclude whether 'open source' is a superior strategy. After all, training models entails costs, and attracting users also requires promotional expenses. From previous large-scale advertising by ByteDance's Doubao and Kimi's multiple fundraisings, it is evident that large model companies face their own challenges.
But for China's large model industry, perhaps it is Liang Wenfeng's 'idealism' that allows Deepseek to become a 'variable' disrupting the industry landscape.
On one hand, open source will attract more major companies and technical talents to join, strengthening Deepseek through co-construction and co-creation, thereby fostering the development of the entire artificial intelligence large model ecosystem and forming a brand-new ecosystem.
Liang Wenfeng once told the media that the company will not choose to shift from open source to closed source like OpenAI in the future. 'We believe that having a robust technological ecosystem is more crucial.'
On the other hand, for competitors represented by OpenAI, this is also a devastating blow. After all, when a comparable and free product appears before consumers, everyone will inevitably compare them. Whose cost-effectiveness is higher and whose performance is better needs to be verified by actual usage effects, not just 'hype'.
And the first to make a move were a group of overseas major companies. Currently, overseas technology giants including NVIDIA, Intel, Amazon, Microsoft, AMD, etc., have all announced the integration of Deepseek into their products.
It is worth mentioning that many European and American countries still harbor doubts about the security and privacy issues of Deepseek. Multiple US officials have stated that they are conducting national security investigations into Deepseek, and departments including the Department of Defense, Congress, and NASA have been urged to ban Deepseek.
Additionally, according to reports by Bloomberg and other media, Microsoft has also investigated whether data from OpenAI technology output was obtained in an unauthorized manner by China's Deepseek team, such as through 'distillation technology' to illegally acquire its model output data.
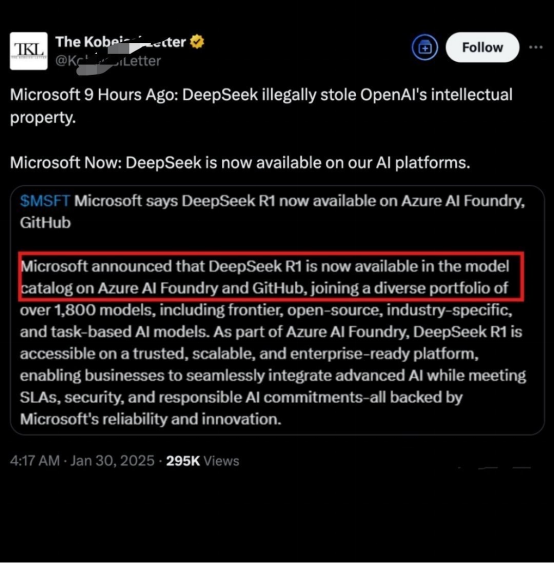
But before these controversies are resolved, major companies are obviously eager to join the Deepseek ecosystem, essentially driven by the principle of 'interest first.'
According to Andrew Ng, associate professor of computer science and electrical engineering at Stanford University, the cost of the OpenAI-o1 model per million output tokens is $60, while Deepseek-R1 only costs $2.19, a nearly 30-fold cost difference. It is believed that major companies will also do the math.
The second factor is the ecosystem effect. Andrew Ng believes that 'price reduction' + 'open source' is commercializing the basic model layer, creating immense opportunities for application developers. Joining this ecosystem as soon as possible and integrating one's own large model with it is also expected to bring more innovative experiences and 'capture' some of the demands of DeepSeek users.
Therefore, besides overseas major companies, domestic major companies such as Alibaba Cloud and Baidu Cloud have also begun to integrate Deepseek, providing adapted services on their respective platforms. Join when can't compete to share the innovation dividend.
3. Ride the East Wind of Deepseek
In fact, the popular Deepseek in early spring not only brought a 'spring breeze' to the large model industry but also presented more new opportunities for ordinary users.
The first batch of individuals who used Deepseek to make money has already emerged. Like ChatGPT, which emerged at that time, facing a more intelligent and efficient large model, the anxiety of AI replacing humans has once again become a 'weapon' to attract users.
There are already numerous courses on social media platforms on 'how to use Deepseek for XXX,' targeting applications and monetization in diverse industries such as social media, e-commerce, and advertising.
Of course, learning new knowledge is not wrong, but compared to being 'harvested' by anxiety and becoming a member of an influencer's private domain traffic, it might be better to first try Deepseek based on one's actual work and content expertise.
Currently, Deepseek does have unexpected technological breakthroughs. For ordinary users, it can display the entire process of the thought chain, making it easier for humans to communicate with AI. Insiders even call it the most user-friendly open-source model currently, but there is no need to overly 'deify' Deepseek.
Firstly, from a user experience perspective, Deepseek cannot yet handle the influx of traffic. In fact, Deepseek had already experienced a small-scale 'explosion' in popularity before the new year. At that time, it could simultaneously use deep thinking and networking functions, and the output article framework and text were indeed quite impressive.
However, with the increasing number of users, Deepseek has currently disabled its networking function, resulting in a significant decline in the quality of organized outputs, and Deepseek is mostly in a 'busy service' state for most of the time.
Although Liang Wenfeng once stated that 'commercialization' is not the primary consideration at present, estimating the fund size of 'Huanfang' based on the size of the private equity fund, a multi-billion size does not equate to a multi-billion fund size. 'Huanfang' only collects management fees on a multi-billion scale, and there is still a substantial fund gap between it and major companies.
But to continuously maintain the user experience on the C-end, Deepseek will inevitably need to burn money. Liang Wenfeng needs to propose a clearer strategy for how to replenish funds or adjust the usage model in the future.
Secondly, Deepseek currently lacks capabilities in images and videos. At this stage, it may be premature to say that Deepseek can directly compete with leading closed-source models.
Nevertheless, its development has also exerted pressure on Open AI and more vertical models, which is expected to propel the development of the entire large model ecosystem to a certain extent.
Finally, Deepseek still faces controversies over policies and data security, and there is still a long way to go before it can go global. Additionally, it is still limited in computing resources and computing power, which means that domestic hardware still needs to continue its efforts to support continuous software innovation.
Of course, for the global large model industry, competition drives progress, much like the smartphone industry. With more participants, the industry will grow, and there will be more opportunities to explode.
The advent of Deepseek serves as a 'spark' igniting the domestic large model industry, signifying both a groundbreaking clash of ideas and a fleeting moment of inspiration. Moving forward, it is imperative for the domestic large model industry to persist in software and hardware innovation, capitalizing on this opportunity to propel China's technology industry from being a mere 'follower' to a distinguished 'leader'.
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





