Exploring DeepSeek on My Computer: Average Generation, Yet Endless Fun
 02/08 2025
02/08 2025
 849
849
This Spring Festival, DeepSeek undoubtedly stole the spotlight as the most talked-about tech product.
Even elders, typically uninterested in tech news, inquired about DeepSeek. The last time an AI large model garnered such attention was OpenAI's ChatGPT.
Amidst its popularity, DeepSeek endured relentless cyberattacks, rendering its official website unable to generate content smoothly most of the time. Even after disabling online searches, the advanced DeepSeek-R1 model was unusable. Fortunately, with the support of Huawei and numerous other tech companies, third-party platforms gained access to DeepSeek's API, enabling stable online use.
However, these channels are inherently online-based. During the Spring Festival, I yearned for a more hands-on experience—deploying DeepSeek locally.
Thus, during the holiday, I embarked on this endeavor.
From slow downloads to intricate coding, building an "AI computer" is no walk in the park.
Deploying a local large model on your computer, whether DeepSeek or another, involves several steps. The challenge lies in sourcing the right resources and commands. It's crucial to note that while a local large model is a pre-trained product, it still demands a solid hardware foundation for optimal performance.
(Image courtesy of Ollama)
First, download the Ollama desktop application from its official website. This application serves as a "container" for the local large model. Besides DeepSeek, Ollama's official model library offers numerous open-source large models.
The Ollama desktop application lacks a control interface. To download a large model locally, locate the corresponding model code in Ollama's official model library, copy it into PowerShell (Win+R, type PowerShell, and hit Enter), and execute the model data pull and installation.
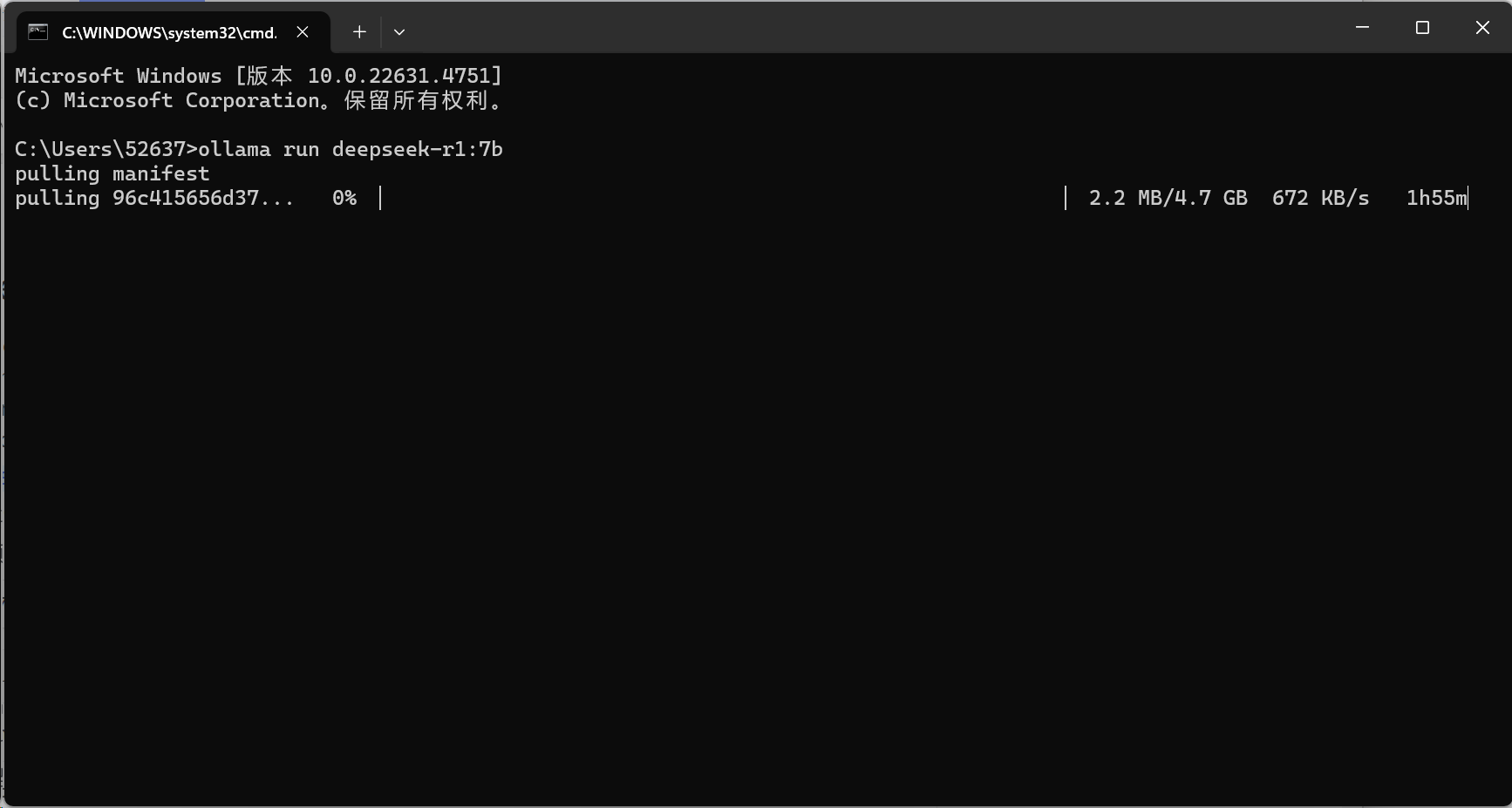
(Image courtesy of Leitech)
I chose the 7b version of the DeepSeek-R1 model, which boasts 7 billion parameters and occupies 4.7GB. Generally, the more parameters, the better, offering more accurate language understanding, higher-quality text generation, enhanced logical reasoning, and learning abilities, along with knowledge reserves and generalization capabilities. However, local large models rely on computer processing power, and individual needs vary, so "forcing" isn't advisable.
Running a model with 1.5B parameters requires at least a GPU with 4GB of video memory and 16GB of RAM. If these requirements aren't met, the CPU will handle calculations, straining the hardware and increasing processing time. The full-featured DeepSeek-R1 model has 671b parameters and a 404GB volume, demanding higher-spec computing hardware. For personal deployment, 1.5b-8b parameters are ideal.
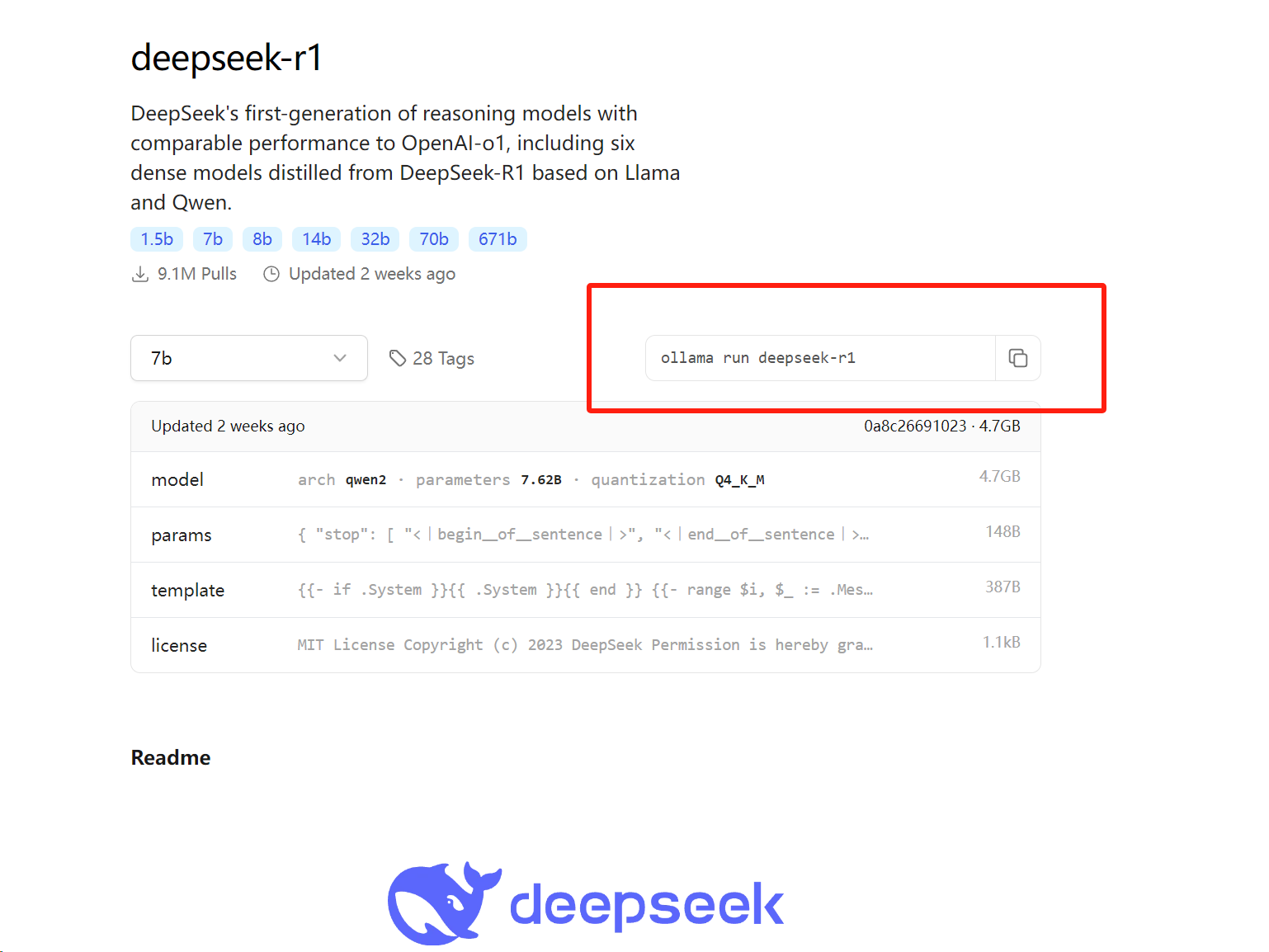
(Image courtesy of Leitech)
Once model data is pulled, the system automatically installs it. After completion, retrieve the newly downloaded DeepSeek-R1 model in PowerShell, enter your question, and send it. The local large model will process and generate a response.
At this point, DeepSeek-R1's local deployment is complete. Theoretically, this method can be used to deploy other large models on your computer.
However, opening PowerShell every time to activate the model isn't convenient for average users. Installing a more intuitive interface for DeepSeek-R1 is necessary. I chose to add an Open-WebUI component on Docker (the blue dolphin icon), allowing DeepSeek-R1 to interact via a browser interface and maintain context connections.
First, download and install the Docker desktop application following the default instructions (skip steps like account registration). Then, reopen PowerShell, copy and execute the following command. I've spared you the Github search:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
If using an NVIDIA GPU, use:
docker run -d -p 3000:8080 --gpus all --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:cuda
Downloading large model files and the Open WebUI component can be time-consuming, especially in suboptimal network conditions. The downloader might retry/switch lines frequently, leading to lost progress.
After installation, an Open-WebUI component appears in Docker. Start it, click the "3000:8080" link, and the system will redirect to a webpage.
(Image courtesy of Leitech)
Now, you have a genuine "AI computer" with a local AI large model.
I navigated the entire deployment process. The steps aren't complex; data pulling and installation are automated. The time-consuming parts involve sourcing command lines, installation resources, and pulling/installing components. Ollama and Docker are accessible via Baidu searches, and I've provided corresponding links above. Tech-savvy individuals can give it a shot.
This isn't the only method for local large model deployment. For instance, Huawei's newly launched ModelEngine offers one-stop training optimization and one-click deployment, making it an enterprise-oriented development tool.
Offline use is convenient, but the generation ability lags behind the cloud version.
With numerous domestic AI large model applications and comprehensive web services, what's the significance of local deployment?
Two key points underpin local large model preparation: First, all model data and conversation records are stored offline, ensuring faster local reasoning and preventing sensitive content leakage. Additionally, large models can function without internet access, like on airplanes. Second, local deployment supports various open-source models, allowing users to expand and switch between them flexibly. They can also optimize and integrate tools based on their needs. In summary, local large models offer more operational freedom than online ones.
However, my deployment experience is limited, and many functions remain unclear. Here's a brief overview of my local large model experience.
I installed the DeepSeek-R1 7b model on a Mechrevo Boundless 14X laptop with 24GB of RAM and no dedicated graphics card, falling outside the recommended configuration for local large model deployment. Thus, the DeepSeek-R1 7b model requires more time and resources to generate content on this laptop.
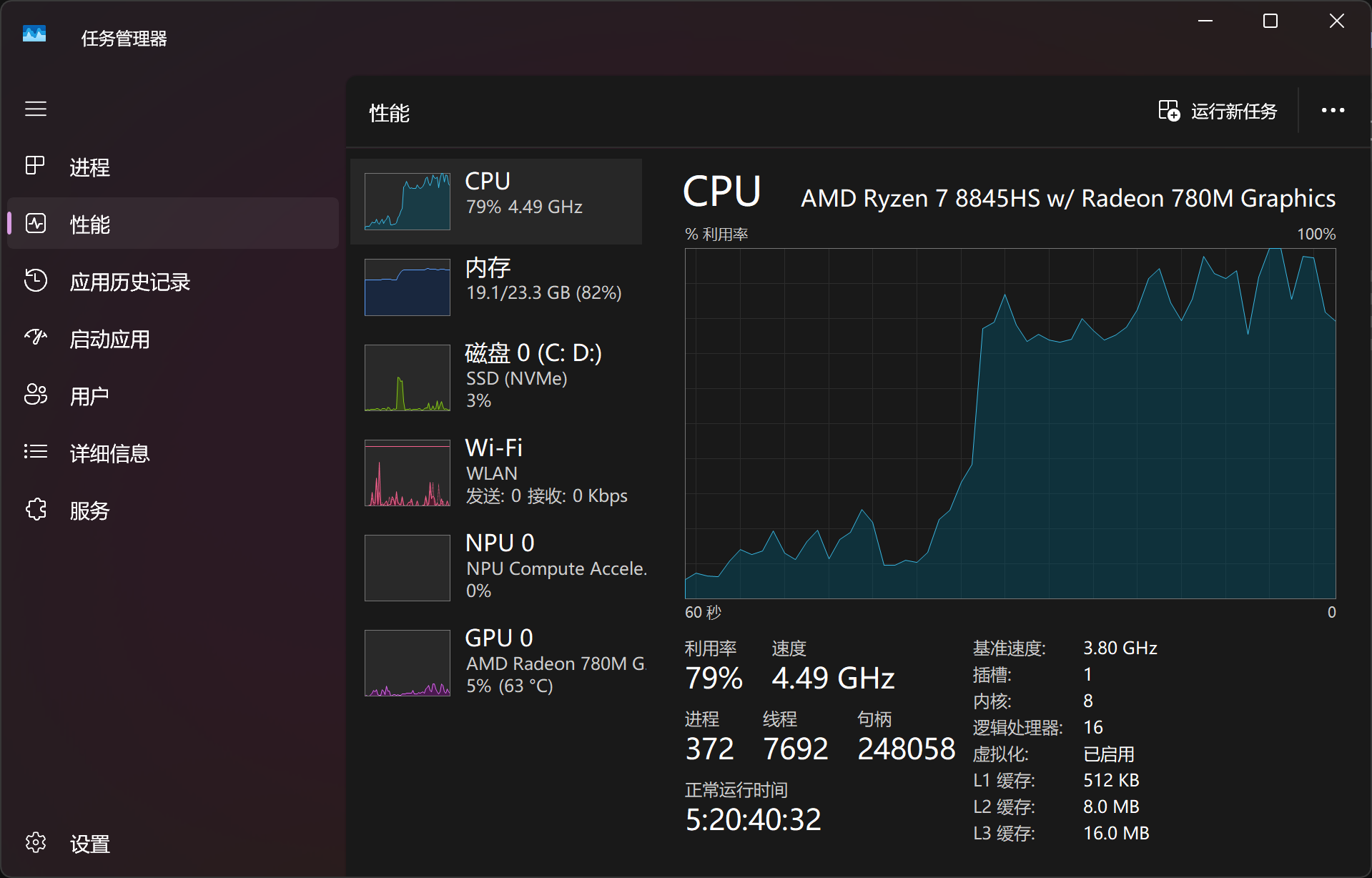
(Image courtesy of Leitech)
For questions like "bloating after meals," the model took 30 seconds to a minute to reach the answer generation stage. During this time, the laptop's load peaked, with the CPU and memory nearly fully utilized. Imagine the struggle of driving a local large model without a dedicated graphics card. Nonetheless, the answers provided some positive insights.

(Image courtesy of Leitech)
More intriguing than the answers was DeepSeek's anthropomorphic reasoning process. Few AI assistants exhibit such human-like thinking. Regardless of answer accuracy, its human-like reasoning piques many users' interest.
If the same question is posed to the web version of DeepSeek-R1 with deep reasoning enabled, it directly shows "server busy." Intense access has indeed plagued DeepSeek. In such cases, local deployment, while not powerful, at least ensures accessibility.
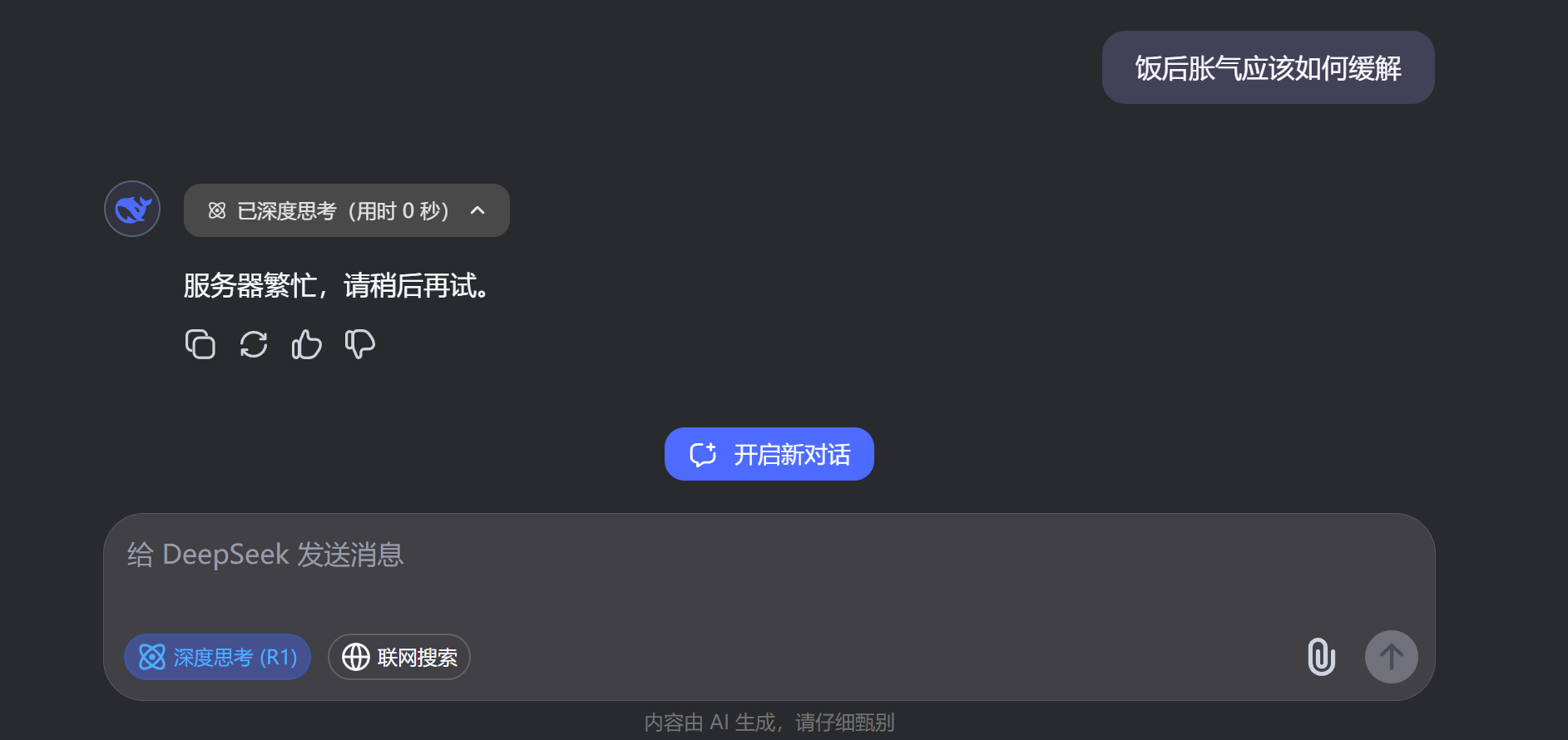
(Image courtesy of DeepSeek)
Changing the question, I asked a classic probability problem to the local DeepSeek-R1 7b. The web version was continuously busy, and the local version seemed confused, listing various scenarios before rejecting them. It even mixed in the previous "bloating after meals" question, creating a comical scene.

(Image courtesy of Leitech)
The local DeepSeek didn't provide an answer after over ten minutes of continuous output. Considering time constraints, I stopped the generation. It's evident that math problems are too complex for the 7b parameter DeepSeek-R1. Even online large models might struggle, let alone local ones. Moreover, during high-parameter local large model reasoning, the computer's load pressure is maximized.
From an open-source perspective, local large models offer better scalability and playability than traditional online models. However, deploying them isn't easy. Exploring more features requires tech-savvy users.
Is local DeepSeek deployment just for fun?
So, is a local large model worth it for everyone? My answer is no.
In terms of current generation ability, local large models can't match online ones. The parameter scale and computing power gap is significant, especially compared to formal large model companies' computing clusters. Local large models are ideal for tech-savvy computer users who enjoy tinkering. Deep exploration can offer functional conveniences, especially since local large models operate at the system level, better integrating with hardware.
For average users, deployment is challenging. Large model supporting facilities aren't as mature as anticipated. The Ollama website is entirely in English, and Docker lacks Chinese support. The deployment threshold is high. I deployed a local DeepSeek model for fun. With an average generation time starting at 20 seconds, offline usage is convenient, but for general generation needs, the experience lags behind online models.
Features like file analysis and online data collection require user tinkering. My current DeepSeek deployment is just the beginning. Additionally, deleting large model data involves specific steps; otherwise, it will occupy system disk space.

(Mockup image)
In my opinion, DeepSeek's open-source path aims to enhance market influence, secure a market position, and attract industry players to establish a comprehensive service system. Ollama and other domestic large model platforms' early access to DeepSeek's API are direct results of open sourcing.
Imagine DeepSeek's applications and penetration across industries, fueled by its immense popularity. The need for personal local deployment will simplify, and users won't need to bother with tasks like opening PowerShell or coding.
Regarding DeepSeek's future, I can't predict it yet. High industry focus has more advantages than disadvantages. Unstable services are short-term issues. Increasing market share, reaching average users, and penetrating various devices will render local deployment obsolete.
Source: Leitech
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





