Has DeepSeek Lifted the 'Curse' of Large Models?
 02/10 2025
02/10 2025
 776
776
In the new year's global tech scene, DeepSeek has undeniably stolen the spotlight. Since its inception, it has sparked a chain reaction across the entire AI industry. The significant responses from both OpenAI and NVIDIA affirm that DeepSeek has executed a surprise attack with remarkable success.
Indeed, DeepSeek's initial performance has been nothing short of impressive. Data reveals that within five days of its launch, DeepSeek's daily active users surpassed those of ChatGPT, and within 20 days, it reached over 20 million daily active users, representing 23% of ChatGPT's user base. Currently, DeepSeek stands as the fastest-growing AI application globally.
While overseas AI players find it hard to believe, the domestic AI field is buzzing with excitement. Alibaba Cloud, Baidu Cloud, Tencent Cloud, and ByteDance's Volcano Engine have officially supported DeepSeek. Meanwhile, Baidu Kunlun Chip, Tianshu Intelligent Chip, and Moore Threads have successively announced their support for the DeepSeek model. This marks a significant step forward for domestic manufacturers in the global AI race.
Has DeepSeek's emergence broken some traditional 'curses' plaguing the stagnant large model industry? Many crucial details merit further investigation.
Is DeepSeek's popularity an 'accident'?
The controversies surrounding DeepSeek seem to converge on a single question: has it truly achieved a technological breakthrough in large models? Early skepticism arose when DeepSeek announced that its model training cost was only one-tenth of the industry average, with questions about whether this was achieved by significantly reducing model parameter size or relying on cheap computing power accumulated early by its parent company, Quantopian.
These doubts have a basis. On one hand, DeepSeek's 'radical' reduction in model parameter size is evident. On the other hand, Quantopian does possess substantial computing power. Reportedly, Quantopian is the only company besides BAT to reserve ten thousand A100 chips, and in 2023, reports revealed that no more than five enterprises in China had hoarded more than 10,000 GPUs.
However, it's worth noting that neither the reduction in model parameter size nor the controversy over computing power innovation detracts from the substantive significance of DeepSeek's 'miracle with little effort' approach. First, with only 150 million parameters (1.5B), DeepSeek-R1 surpassed large models like GPT-4 with a 79.8% success rate in mathematical benchmark tests. Secondly, lightweight models naturally excel in reasoning ability and performance, with lower training and operating costs. DeepSeek provides performance similar to GPT-4 at only one-fiftieth of the price, capturing a significant market share among small and medium-sized enterprises and individual developers.
Quantopian's contribution to DeepSeek is more of a natural outcome of the growth of domestic large models rather than an accidental capital play. Notably, Quantopian was one of the first domestic enterprises to enter the large model race. As early as 2017, Quantopian announced its goal to fully AI-ize investment strategies.
In 2019, Quantopian established an AI company, investing nearly 200 million yuan in its self-developed deep learning training platform 'Firefly One,' equipped with 1,100 GPUs. Two years later, investment in 'Firefly Two' increased to 1 billion yuan, equipped with about 10,000 NVIDIA A100 graphics cards.
In November 2023, DeepSeek's first open-source model, DeepSeek-Coder, was released. In other words, this DeepSeek, which has caused overseas tech giants to collectively break their defenses, is not an overnight product but a step that domestic AI vendors were bound to take sooner or later in their large model layout.
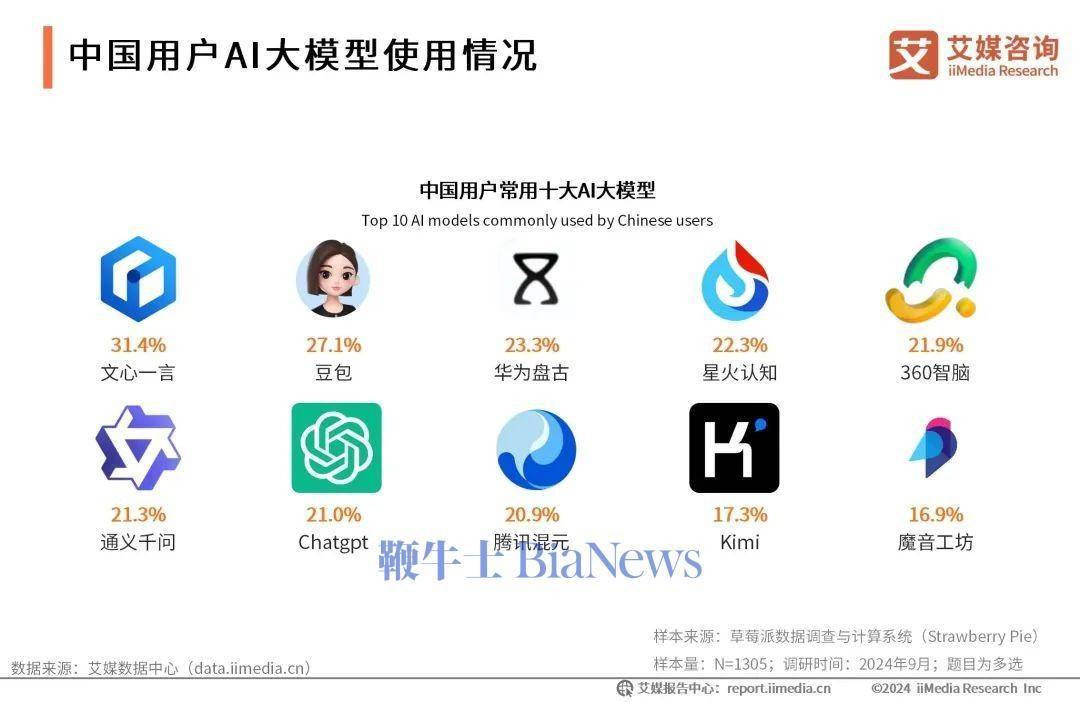
It is undeniable that China currently has the objective conditions to cultivate a 'DeepSeek.' Public data shows that a comprehensive AI system is emerging under the pursuit of various capital sources, with more than 4,500 domestic AI-related enterprises and a core industry scale of nearly 600 billion yuan.
Chips, algorithms, data, platforms, applications... The popularization rate of artificial intelligence represented by large models in China reaches 16.4%.
Of course, the risk of DeepSeek's technological path dependence always exists, adding a touch of uncertainty to its popularity, especially as 'data distillation technology' continues to face scrutiny. In fact, DeepSeek is not the first large model to use data distillation, and 'excessive distillation' is a major contradiction in the current AI race.
Multiple institutions from the Chinese Academy of Sciences and Peking University have pointed out that, except for Douban, Claude, and Gemini, most open/closed-source LLMs are overly distilled. Excessive reliance on distillation may lead to stagnation in basic research and reduce diversity among models. A professor from Shanghai Jiao Tong University also stated that distillation technology cannot solve the fundamental challenges in mathematical reasoning.
In short, these factors are compelling DeepSeek and even the entire domestic large model race to continue self-verification. Perhaps, a second 'DeepSeek' will emerge in China. Realistically, the inevitability of DeepSeek's success far outweighs its accidental nature.
Is the 'Era of Open Source' Coming?
Notably, compared to the debate over technology, DeepSeek has reignited intense discussions in the global tech circle about open source and closed source. Yann LeCun, Chief Scientist at Meta, even stated on social platforms that this is not China catching up to the US, but open source catching up to closed source.
Talking about open-source models, we must trace back to a source code leak incident at Meta in 2023. Meta seized the opportunity to release the open-source and commercially available version of LLama 2, immediately sparking an open-source craze in the large model race. Domestic enterprises such as Wudao, Baichuan Intelligence, and Alibaba Cloud have entered the field of open-source large models.
According to Kimi chat statistics, there were more than 10 open-source large model brands in 2024. In the first two months of 2025, in addition to the popular DeepSeek, countless participants have joined the open-source movement.
Reportedly, on January 15, MiniMax open-sourced two models: the basic language large model MiniMax-Text-01 and the visual multimodal large model MiniMax-VL-01. Simultaneously, NVIDIA open-sourced its world model, comprising three models: NVIDIA Cosmos Nano, Super, and Ultra. On January 16, Alibaba Cloud Tongyi also open-sourced a mathematical reasoning process reward model with a size of 7B.
From 2023 to 2025, after countless debates among AI talents, is the 'Era of Open Source' for large models finally upon us?
One thing that can be confirmed is that compared to the closed-source model, the open-source model gains significant attention in a short time due to its openness. Public data shows that when 'LLama 2' was first released, there were over 6,000 results for it on the Hugging Face search model. Baichuan Intelligence revealed that the download volume of its two open-source large models exceeded 5 million in September of that year.
In fact, DeepSeek's rapid rise to fame is inseparable from its open-source model. February statistics show that countless enterprises have accessed the DeepSeek series of models, with cloud vendors, chip vendors, and application-end enterprises all participating in the excitement. In the current peak demand for AI, open-source large models seem to better promote AI ecologization.
However, whether to open source in the large model race remains debatable.
Although Mistral AI and xAI are both supporters of open source, their flagship models are currently closed. Most domestic manufacturers are essentially one hand closed source and one hand open source. Typical examples include Alibaba Cloud and Baichuan Intelligence, and even Li Yanhong was once a loyal supporter of the closed-source model.
The reason is not difficult to guess. On one hand, open-source AI companies are not favored by capital in the global tech field, while closed-source AI enterprises have more financing advantages. Statistics show that since 2020, global closed-source AI startups have completed $37.5 billion in funding, while open-source AI companies have only received $14.9 billion.
For AI enterprises that spend money like water, this gap is substantial.
On the other hand, the definition of open-source AI has become increasingly complex in the past two years. In October 2024, the Open Source Initiative released version 1.0 of the 'Definition of Open Source AI.' The new definition states that for an AI large model to be considered open source, three key points must be met: transparency of training data, complete code, and model parameters.
Based on this definition, DeepSeek has been questioned as not truly open source but merely catering to short-term popularity. Globally, a report in 'Nature' also pointed out that many tech giants claim their AI models are open source but are not fully transparent.
A few days ago, Altman, the co-founder of OpenAI, admitted for the first time that OpenAI's closed-source approach was 'a mistake.' Perhaps, following the popularity of DeepSeek, another 'verbal drama' in the AI world is about to unfold.
Will Large-Scale Computing Power Investment Soon Be 'Paused'?
Recently, many AI enterprises obsessed with hoarding computing power have been ridiculed due to the emergence of DeepSeek, and computing power suppliers like NVIDIA have seen significant hits to their stock prices. Frankly, DeepSeek has indeed brought new breakthroughs in certain aspects, especially in alleviating some anxiety regarding the 'monopoly curse.'
However, the demand for computing power in the global large model race still cannot be ignored, and even DeepSeek itself may not be able to pause its computing power investment.
It should be noted that DeepSeek currently only supports functions such as text Q&A, image reading, and document reading, and has not yet ventured into the generation of images, audio, and video. Even so, its servers are on the brink of collapse, and once the form is changed, the demand for computing power will explode, with a huge gap in computing power requirements between video generation models and language models.
Public data shows that the computing power requirements for training and inference of OpenAI's Sora video generation large model reach 4.5 times and nearly 400 times that of GPT-4, respectively. The leap from language to video is already significant, and with the birth of various super computing power scenarios, the necessity of computing power construction only increases.
Data shows that from 2010 to 2023, the demand for AI computing power increased by hundreds of thousands of times, far exceeding the growth rate of Moore's Law. Entering 2025, OpenAI released its first AI Agent product, Operator, which has the potential to ignite super computing power scenarios. This is crucial for determining whether computing power construction will continue.
Reportedly, the current development of large models is divided into five stages: L1 language ability, L2 logical ability, L3 ability to use tools, L4 self-learning ability, and L5 ability to explore scientific laws. The Agent is located at L3, the ability to use tools, and is simultaneously exploring L4 self-learning ability.
According to Gartner's prediction, by 2028, 15% of daily work decisions worldwide are expected to be made through Agentic AI. If the large model race continues as planned, from L1 to L5, global AI enterprises will pay even more attention to the construction of computing power.
What will the demand for computing power be at the L3 stage?
In a report in October 2024, Barclays Bank predicted that by 2026, if consumer AI applications can surpass 1 billion daily active users, and Agents have a penetration rate of more than 5% in enterprise businesses, at least 142B ExaFLOPs (about 150,000,000,000,000 P) of AI computing power will be required to generate 500 trillion tokens.
Even though the arrival of the super application stage is still far off, in the fiercely competitive market of the current large model race, no enterprise is willing to lag behind. Microsoft, Google, Amazon, Meta, ByteDance, Alibaba, Tencent, Baidu... These domestic and overseas AI giants are afraid of falling behind and continue to invest heavily in gambling on the future.
In addition, what DeepSeek is most celebrated for is bypassing the 'chip hurdle.' However, as the cornerstone of the computing power industry, under the same investment, high-quality computing power infrastructure often provides higher computing power efficiency and commercial returns. 'Ten Trends in the Computing Power Industry in 2025' mentioned that taking GPT-4 as an example, its performance can vary significantly under different hardware configurations. Comparing the performance of GPT-4 driven by different hardware configurations such as H100 and GB200, the profitability of using the GB200 Scale-Up 64 configuration is six times that of the H100 Scale-Up 8 configuration.
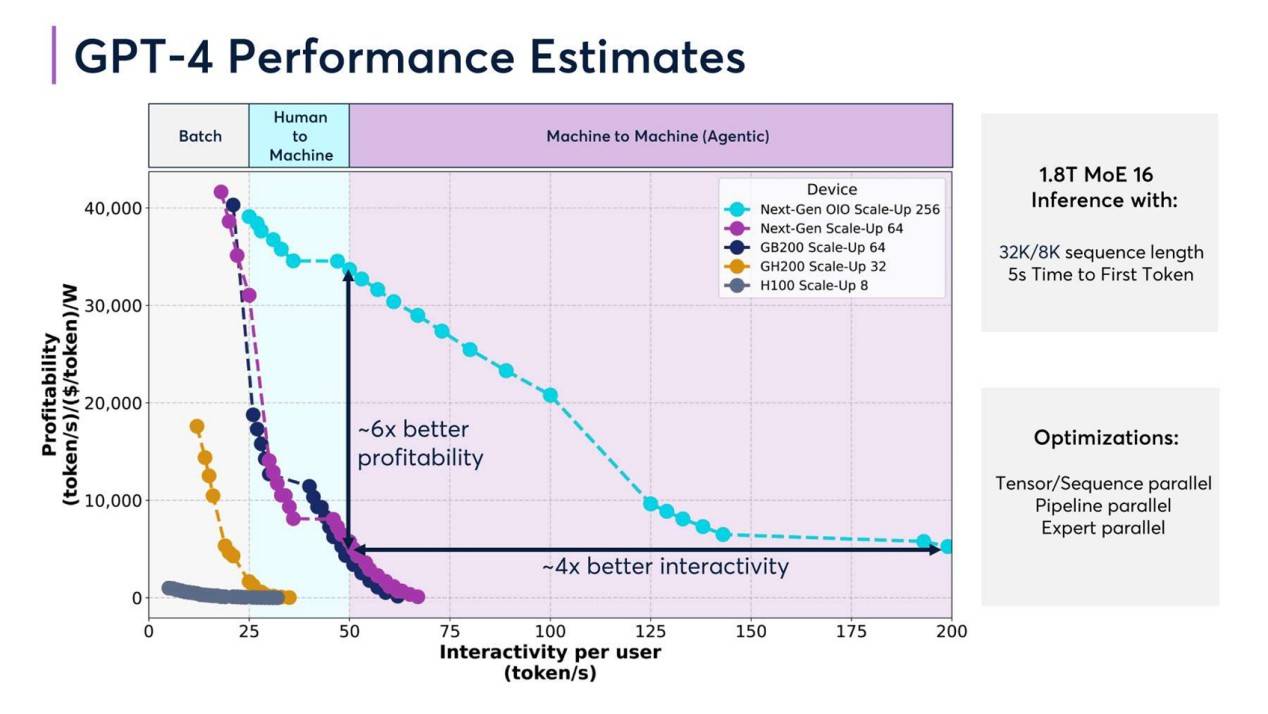
DeepSeek's frequently crashing servers may suggest that the 'chip pursuit' game in the large model race has not ended in the computing power competition. Reportedly, in 2025, NVIDIA's next-generation GPU GB300 may see multiple key hardware specification changes, and the domestic AI chip localization process is also progressing rapidly.
Various signs indicate that the arduous computing power construction cannot be stopped for the time being and is instead becoming more competitive.
Dao Zong You Li, formerly known as Waidaodao, is a new media outlet in the internet and tech circle. This article is original and any form of reprint without retaining the author's relevant information is prohibited.
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





