Price Adjustment! Evaluating the Cost-Effectiveness of Six Leading Global Models: DeepSeek's Reign Challenged
 02/13 2025
02/13 2025
 759
759

With the conclusion of the promotional period, the price of the DeepSeek-V3 API has risen.
On February 9, 2025, DeepSeek-V3 terminated the introductory pricing announced at launch, marking an increase from the original input price (cache hit/cache miss) of 0.1 yuan/1 yuan per million tokens and an output price of 2 yuan per million tokens:
The new input price is 0.5 yuan per million tokens (cache hit) and 2 yuan (cache miss), with an output price of 8 yuan.

Image/ DeepSeek
While there is a substantial increase compared to previous prices, particularly for cache hits and output prices, which are 4-5 times higher, the overall price of DeepSeek-V3 remains significantly lower than that of the current top closed-source large models, GPT-4o and Claude-3.5-Sonnet.
This price adjustment signifies that DeepSeek-V3 has transitioned from the "trial phase" into a new market phase. In the AI realm, changes in API pricing are indicative of broader shifts in the competitive landscape of the large model market, particularly for non-inference large models like DeepSeek-V3 and GPT-4o.
The API cost of large models directly influences their appeal in enterprise applications and developer ecosystems, particularly among mainstream large models. Prior to DeepSeek's launch of V3 and R1, OpenAI and Anthropic dominated with their high-end closed-ecosystem models, but DeepSeek-V3 quickly gained traction with its cost-effective API, becoming the preferred choice for developers.
However, the challenges facing DeepSeek-V3 are clearly intensifying—even the "hottest star" DeepSeek is facing competition.
It's not just that OpenAI and Anthropic are launching more price-competitive models; an increasing number of competitors are rapidly emerging. Notably, Google (Gemini), Alibaba (Tongyi Qianwen), and another "new generation" domestic large model, MiniMax, have each introduced new large models that rival DeepSeek-V3 and DeepSeek-R1 in performance and price.
Take Google's Gemini 2.0 series, specifically the "medium cup" Gemini 2.0 Flash, which benchmarks GPT-4o, as an example. The price per million tokens is:
0.1 USD for input and 0.4 USD for output (approximately 0.73 yuan and 2.9 yuan, respectively).
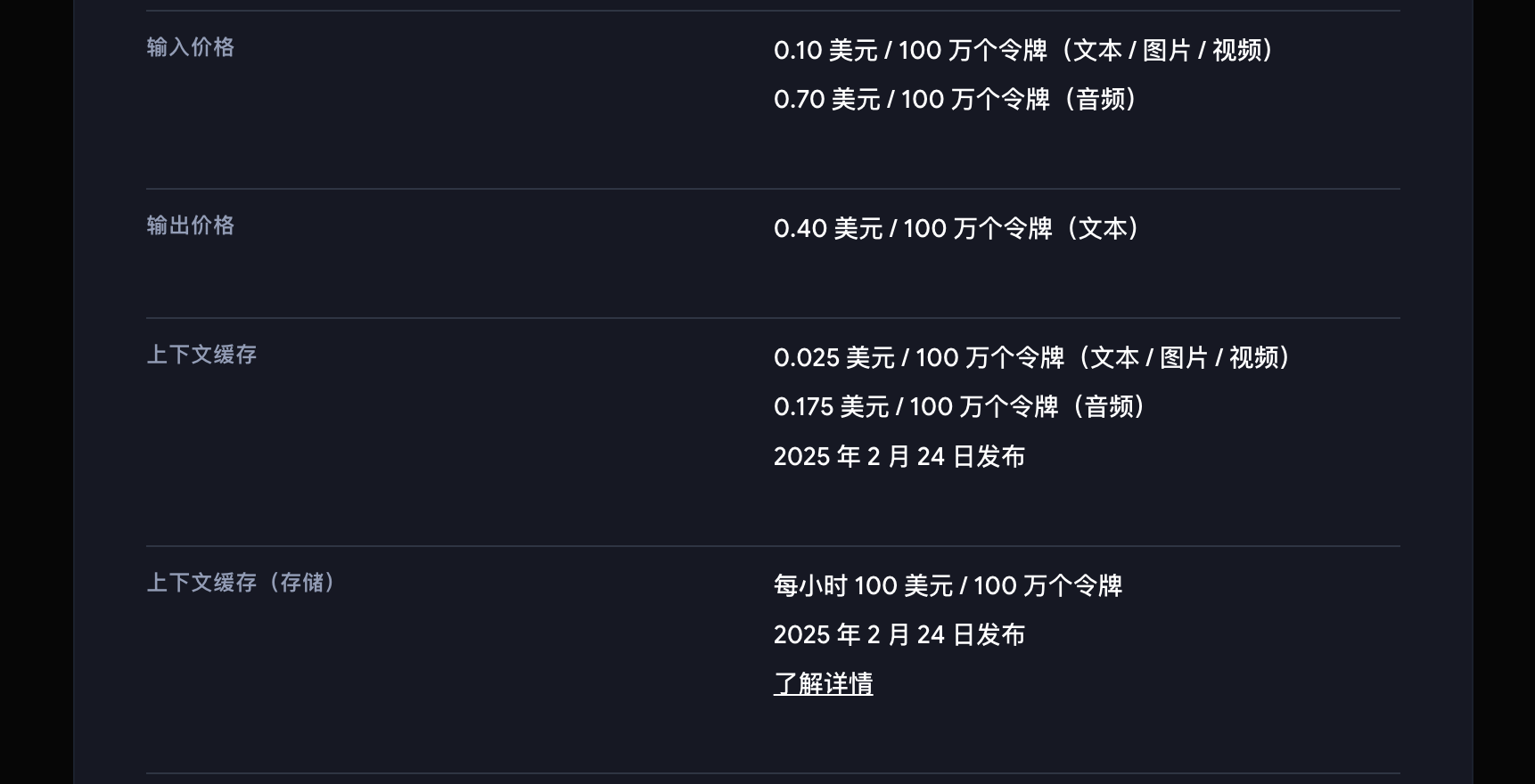
Gemini 2.0 Flash API price, Image/ Google
If DeepSeek-V3's defining feature was its "high performance + low price" to offer a "budget alternative," its price now appears less leading, with MiniMax and Google's new generation of large models closing the gap in cost and performance, threatening its competitive edge.
While DeepSeek has undeniably transformed the large model industry, with an increasing number of formidable competitors, is its cost-effectiveness still unmatched? Can DeepSeek-V3 maintain its once-legendary cost-effectiveness?
Global Six Major Model Comparison: DeepSeek's Cost-Effectiveness Advantage Diminishes
The global large model market is currently in a fierce competition, and it's insufficient to discuss performance or price in isolation. The key lies in the balance between performance and price, which is also the crux of current competition in the large model market.
Following DeepSeek's global impact, multiple heavyweights have emerged in the large model market, intensifying the API price war. To understand the current cost-effectiveness and competitive advantage of DeepSeek-V3, it's necessary to compare it with several large models of similar performance (alignment) among the latest generation of top large models:
- GPT-4o
- Claude-3.5-Sonnet
- Gemini-2.0-Flash
- Qwen2.5-Max
- MiniMax-Text-01
From the models aligned by each company, it's evident that they are heavily influenced by the two top closed-source models, GPT-4o and Claude-3.5-Sonnet. Not only did DeepSeek officially state that V3 aligns with GPT-4o in performance, but both Tongyi Qianwen (Qwen) and MiniMax also frequently use GPT-4o and Claude-3.5-Sonnet as benchmarks for comparison.
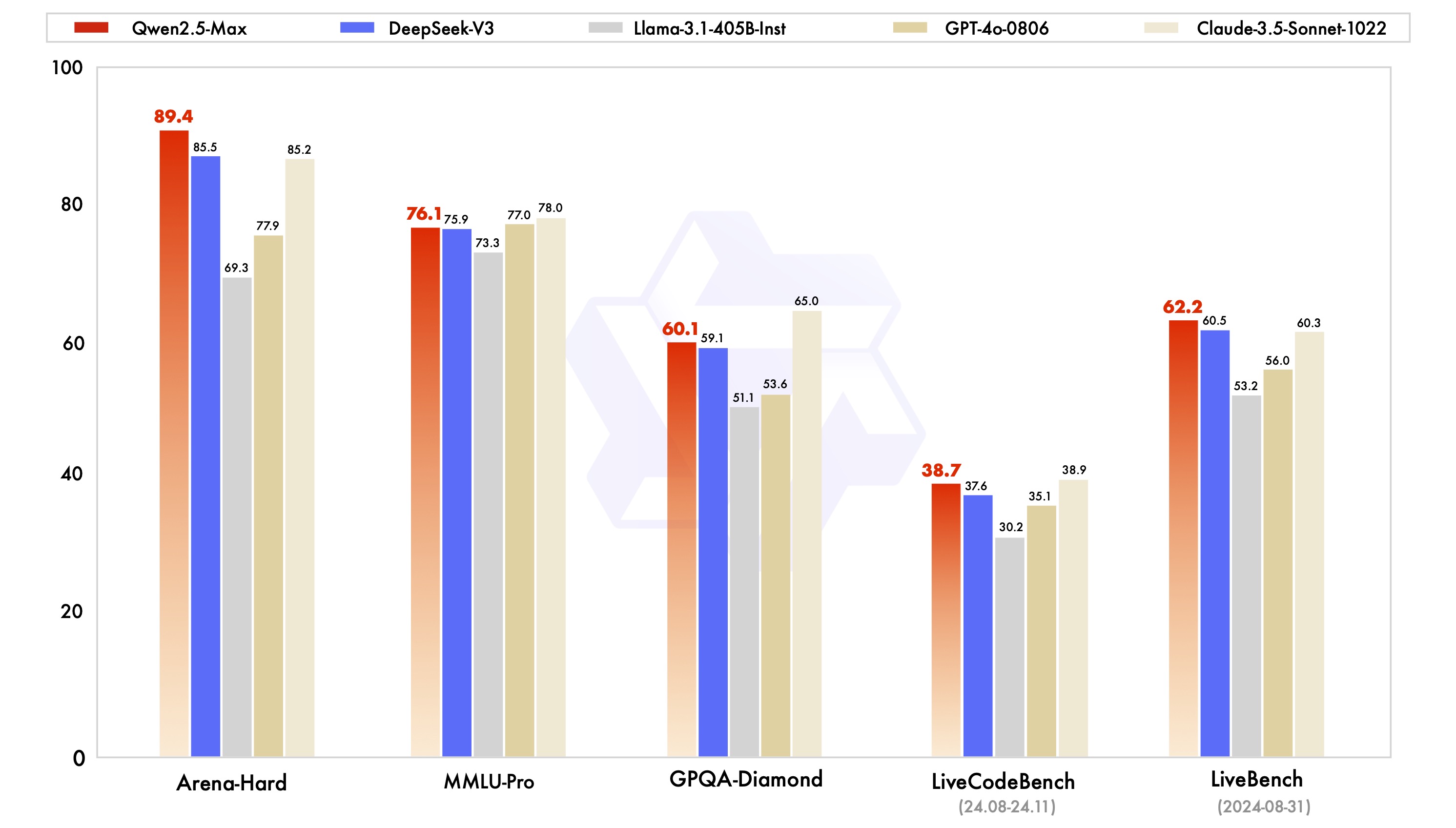
Qwen2.5-Max benchmark comparison chart, Image/ Alibaba
Furthermore, Google has largely caught up with the leading edge in the past two years. While Gemini-2.0-Pro benchmarks OpenAI-o1 and DeepSeek-R1, Gemini-2.0-Flash has once again surprised many. Alibaba also recently launched Qwen2.5-Max, claiming to surpass DeepSeek-V3, and MiniMax-Text-01, launched by domestic AI startup MiniMax, also shows strong competitive potential.
The reason for selecting these six models for comparison is that their performance has reached the same tier. While each has different focuses, they all offer exceptional performance in various scenarios. Lei Technology has also compiled the latest API pricing for these six models:
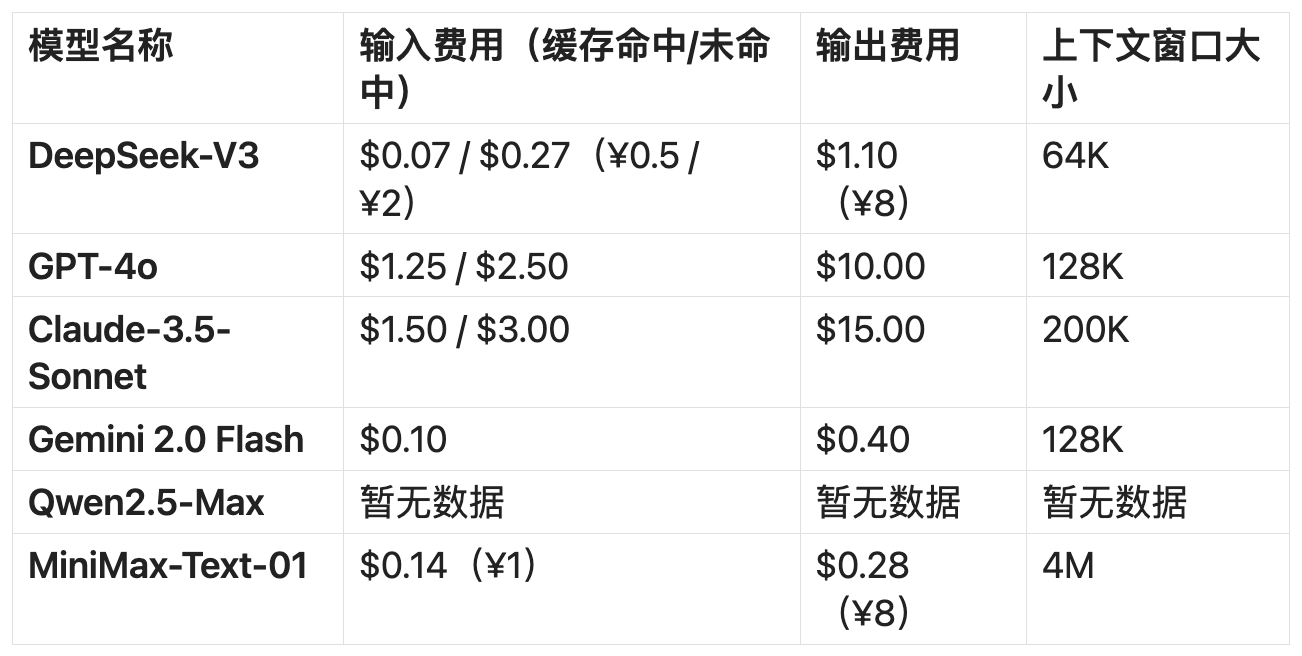
(Unit: per million tokens, data source: official website) Image/ Lei Technology
From a simple price comparison, DeepSeek-V3 remains one of the cheapest high-performance large models, but its cost-effectiveness is no longer exclusive.
GPT-4o and Claude 3.5-Sonnet are still the most expensive models, with prices nearly 10 times higher than DeepSeek-V3, but their advantages in multimodal capabilities, generalization, and overall capabilities persist, making them hard to ignore for many developers.
For instance, MiniMax-Text-01, the "game-changer" in the new round of large models, boasts the lowest output price and the longest context window, not limited to text. MiniMax has also released a separate visual multimodal model, MiniMax-VL-01.
Hailuo AI is a service under MiniMax, Image/ MiniMax
Gemini 2.0 Flash, positioned as the "mid-range flagship" in the series, has an input price of only 0.1 USD, slightly more expensive than DeepSeek-V3, but its output price is cheaper at only 0.4 USD, making its cost-effectiveness very close to that of DeepSeek. It also leverages Google's powerful search and content ecosystem.
As for Qwen2.5-Max, the official website only shows the pricing of the Qwen-Max model, which is 2.4 yuan for input and 9.6 yuan for output (1.60 USD for input and 6.40 USD for output), and does not explicitly state the pricing of Qwen2.5-Max, which may be subject to strategy adjustments, so we will continue to monitor it.
DeepSeek-V3 is still the cheapest, but it's no longer the "default" choice
API price is the initial hurdle for developers evaluating large models, but it's not the sole deciding factor. As competitors gradually close the price gap, can DeepSeek-V3 maintain its market appeal?
Once upon a time, developers often faced the trade-off of "performance vs. cost" when choosing large models. GPT-4o is undoubtedly the most powerful model, but with input and output prices of $2.50 and $10 per million tokens, respectively, it deters many startup teams. Claude 3.5-Sonnet is even more expensive, and while it excels in long-text reasoning, its API prices of $LM3". for0 a0 while/$,1 particularly5 with.00 are unaffordable for ordinary companies.
In contrast, DeepSeek-V3's ultra-low-price strategy made it the "most cost-effective high-end L stable competitiveness in code, mathematical reasoning, and Chinese tasks.

Image/ DeepSeek
But the market has evolved.
As a domestic, open-source, and free large model, MiniMax-Text-01 not only offers an ultra-long context window of 4M tokens but also directly challenges DeepSeek-V3's market positioning with an API price of 1 yuan for input and 8 yuan for output. For applications requiring long text processing, such as legal consultation, contract analysis, and long content summarization, MiniMax becomes a more appealing choice.
In overseas markets, DeepSeek-V3 also faces the threat of Gemini 2.0 Flash. Not only is Google's API pricing very close to that of DeepSeek when viewed comprehensively (0.10 USD for input and 0.40 USD for output), but Google's ecosystem integration capabilities (direct access to Google Search, integration with Gmail, YouTube, Google Drive) are also strong enough to make it the first choice for many enterprises.
In this scenario, how will developers make decisions?
For startup teams that are highly cost-sensitive, DeepSeek-V3 may still be a viable option. Its input price is not only significantly lower than that of GPT-4o and Claude but even cheaper than Gemini 2.0 Flash. If your application primarily involves standard dialogue, code generation, and Chinese processing tasks, DeepSeek-V3 remains the most cost-effective LLM.
However, if your application requires ultra-long contexts, cross-platform ecosystem integration, or higher generalization capabilities, then Gemini 2.0 Flash may be a better fit. The main issue with DeepSeek-V3 is that its cost-effectiveness advantage is no longer "unique." It's still inexpensive, but it's no longer the sole low-priced and high-performance option.
From a developer's perspective, DeepSeek-V3 is still worth using, but it's no longer the optimal solution that can be chosen without hesitation.
Beyond maintaining cost-effectiveness, DeepSeek also needs to prioritize stability
If the AI price war is a protracted battle, then this adjustment by DeepSeek-V3 may have just ignited the real competition. However, it must be noted that user choices may still differ.
Many people's first encounter with DeepSeek-V3 (or R1) was not through the API but through the services provided on the official DeepSeek webpage or APP: free and offering the ability to experience top-tier global AI anytime. However, in reality, this free experience is often marred by "server busy" prompts, greatly detracting from the user experience.
Too busy, Image/ Lei Technology
Especially during peak hours, DeepSeek-V3 (or R1) often fails to respond normally and cannot even complete basic dialogue tasks. In contrast, while OpenAI's ChatGPT Plus subscription is paid, its high stability makes many users, including myself, still willing to pay for a "smooth experience."
This may also be a critical issue for the current "hottest star," DeepSeek. Either by expanding infrastructure or introducing a paid subscription "threshold," it will be challenging to address this problem otherwise.
Source: Lei Technology
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





