"Price Surge: GPT-4.5 Costs 277 Times More Than DeepSeek! Confidence Overwhelms Practicality."
 03/03 2025
03/03 2025
 648
648
"GPT-4.5 has undeniably made progress, yet the astronomical reasoning costs suggest OpenAI is grappling with challenges."
On February 28, Beijing time, OpenAI hosted a modest livestream event to officially unveil the long-anticipated GPT-4.5 (research preview). Notably absent was CEO Sam Altman, and officials emphasized that GPT-4.5 is not a cutting-edge model.
In contrast, the launch of GPT-4 two years ago was far more elaborate and imaginative. These signals hinted from the outset that OpenAI did not view GPT-4.5 as a landmark upgrade.
However, GPT-4.5 remains OpenAI's latest and most powerful chat model, boasting higher emotional intelligence (EQ) in its responses. Crucially, it offers a 24% increase in accuracy and a 24.7% reduction in hallucination rate compared to GPT-4o.
These enhancements are pivotal as these two aspects continue to pose significant issues in the utilization of many large models, including DeepSeek-R1.
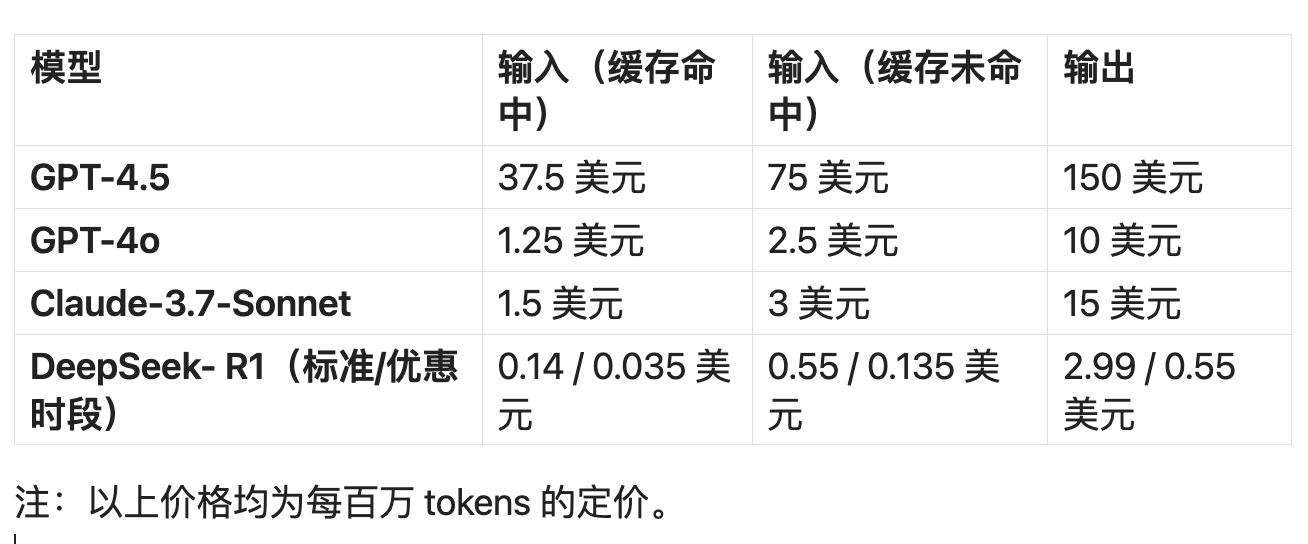
From this perspective alone, the livestream event was worth the "ticket price." However, evaluating the "ticket price" for using GPT-4.5 is another matter entirely:
Input (cache hit): $37.5 per million tokens;
Input (cache miss): $75 per million tokens;
Output: $150 per million tokens.
What does this mean? Considering the input price (cache miss) as an example, GPT-4.5's API pricing is 30 times that of GPT-4o, 277 times that of DeepSeek-V3 (priced in USD), and 136 times that of DeepSeek-R1 (priced in USD). Even compared to DeepSeek's off-peak pricing, GPT-4.5 is 555 times more expensive.
Image/Lei Technology
It's difficult to fathom how many developers can afford or are willing to utilize GPT-4.5 with such astronomical pricing.
Relatively speaking, ChatGPT membership might offer the most cost-effective access to GPT-4.5. Currently, Pro users can already experience GPT-4.5 (research preview), with team users and Plus users gaining access next week, alongside educational and enterprise users.
It's crucial to emphasize that GPT-4.5 is not a reasoning model.
Since OpenAI introduced the o1 model, large models have diverged into a path known as "reasoning models," including OpenAI o1/o3 and DeepSeek R1. GPT-4.5, however, is a pre-trained large model on a non-reasoning path, akin to OpenAI's current flagship model GPT-4o or DeepSeek V3.
Nonetheless, OpenAI has stated that reasoning will be a core capability of future models, and the parallel progression of pre-training and reasoning paths, complementing each other, will be a trend in large models. In fact, Sam Altman previously clarified that OpenAI's two series of models will eventually:
Merge into one.
"IQ improvements are modest, but EQ is higher and hallucinations are fewer"
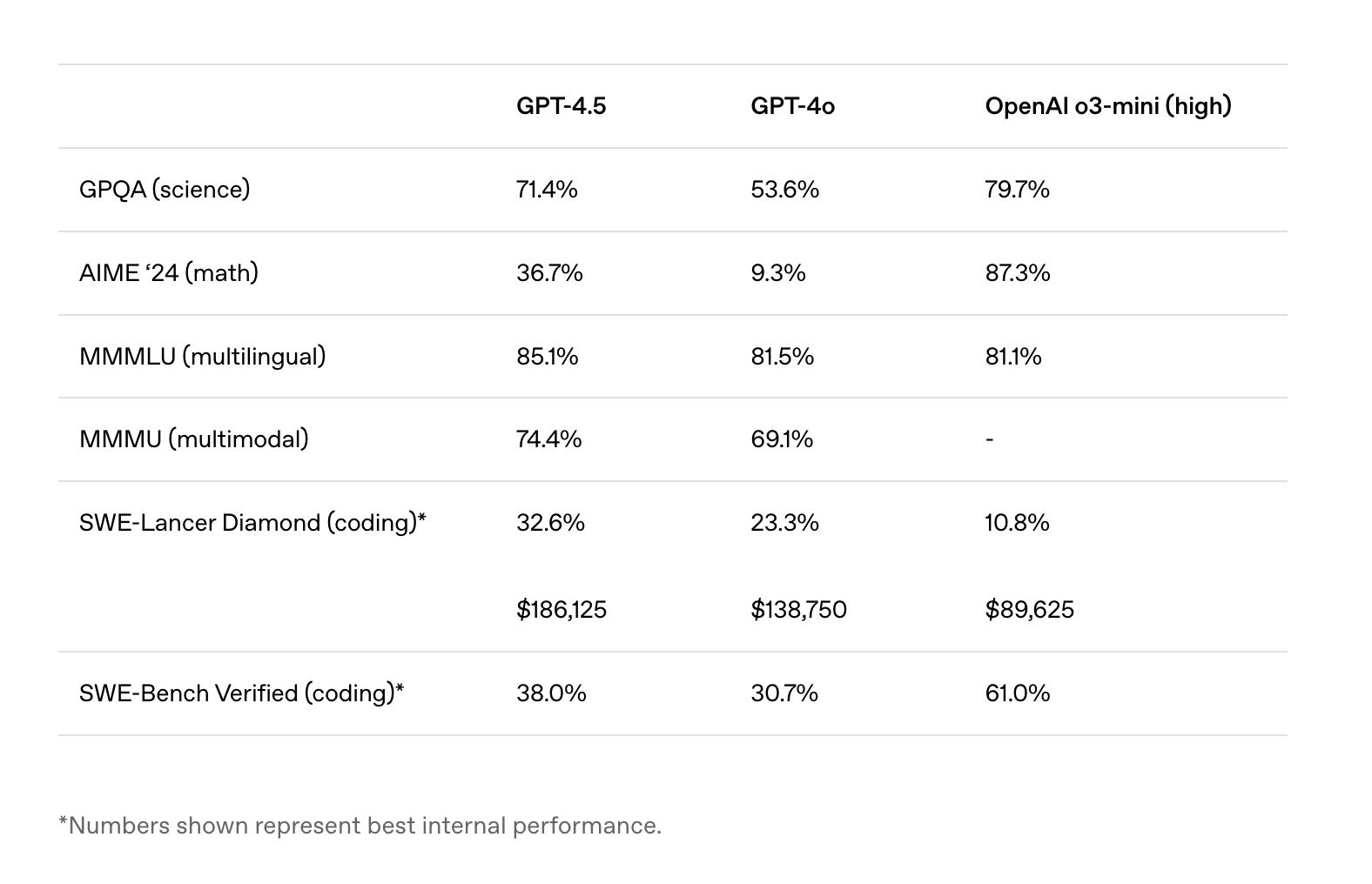
If we consider the "IQ" typically benchmarked among large models, GPT-4.5's advancements are not substantial.
Image/OpenAI
While GPT-4.5 scores have improved on benchmarks like MMMLU (language understanding) and MMMU (multimodal) compared to GPT-4o, the increase is approximately 5%, far inferior to the reasoning model o3-mini (high) on benchmarks such as GPQA (science) and AIME '24 (data).
However, let's set aside benchmark scores and underlying technological iterations to focus on GPT-4.5's more "perceptible" upgrades demonstrated during the livestream. It's evident that GPT-4.5 better understands human needs and intentions in conversations.
In one instance, the host told GPT-4.5, "My friend stood me up again, and I want to send a text message scolding him," but GPT-4.5 did not directly provide an angry text message. Instead, it captured the user's emotion and offered more constructive messages. In contrast, GPT-4o mostly "simply" executed the command and provided an angry text message.

Translation for reference only, Image/OpenAI
Another example is when GPT-4.5 was told, "I'm going through a tough time after failing an exam," other models would immediately offer possible "solutions," while GPT-4.5 proactively comforted and inquired about the user, asking if they actually wanted to discuss the problem or needed a distraction.
In numerous examples, GPT-4.5's improvement in "EQ" is evident; it behaves more like a "person" than a "machine".
In internal testing, OpenAI found that compared to conversations with GPT-4o, testers generally believed that interactions with GPT-4.5 were closer to human communication and more natural. However, the data gap between the two is not significant. GPT-4.5 has a slight edge in creative intelligence and daily inquiries, with a 63.2% win rate in professional inquiries.
Yet, more concerning than EQ might be the reduction in hallucinations. In the "simple but challenging" SimpleQA commonsense question-and-answer test, GPT-4.5's rate of fabricating answers or hallucinating was about 37%, compared to nearly 60% for the GPT-4o model.
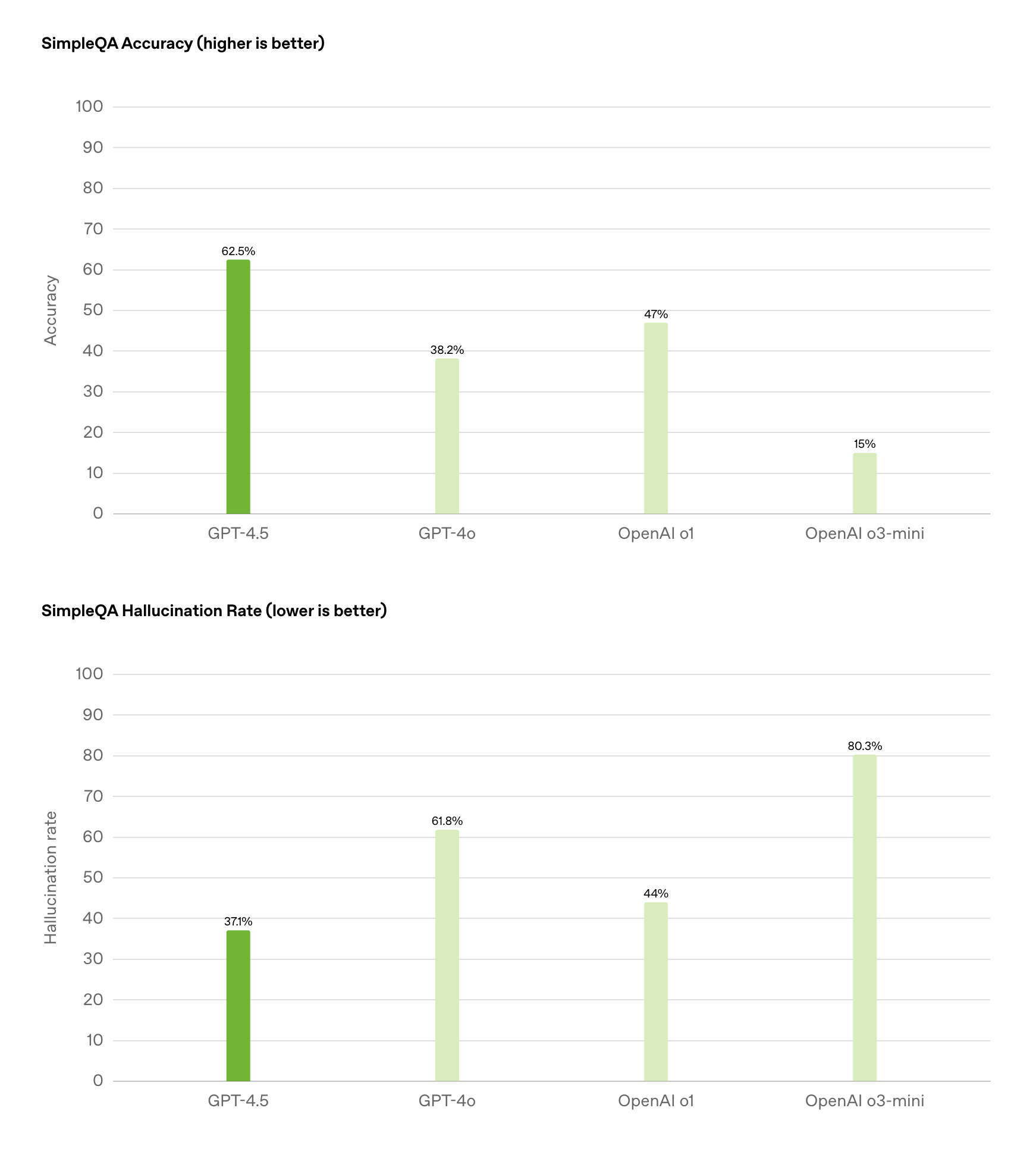
Top: Accuracy, Bottom: Hallucination Rate, Image/OpenAI
It's worth noting that GPT-4o is already considered one of the models with fewer hallucinations, generally believed to be superior to DeepSeek-V3, let alone DeepSeek-R1, which has more severe hallucination issues.
"The price is 277 times that of DeepSeek! It's absurd"
After GPT-4.5's release, MIT Technology Review interviewed a large model service company for business clients. Its co-founder and CTO Waseem Alshikh stated that GPT-4.5 has great potential for specific use cases like writing and brainstorming but overall only makes interactions smoother:
"It's not a revolution."
This generally explains GPT-4.5's upgrade positioning, which can be considered at most a half-generation upgrade. Moreover, OpenAI invested more training computing power, resulting in exorbitantly high reasoning costs.
Although the training cost of GPT-4.5 was not disclosed, Sam Altman clearly stated on X (formerly Twitter) that GPT-4.5 is a giant, expensive model, requiring tens of thousands more GPUs next week to develop it for Plus and more users.

Translation for reference only, Image/X
Meanwhile, as shown in previous data, GPT-4.5's API pricing shocked everyone, being not only more expensive than its own flagship large model but also 25 times more expensive than the recently launched Claude-3.7-Sonnet, the world's first hybrid reasoning model. This is especially notable compared to the "price killer" DeepSeek, which just announced off-peak pricing.
"Frankly, I'm shocked. How do they justify this pricing?" asked a Hacker News user. "If they have some amazing capabilities that make a 30-fold price increase reasonable, why not show them?"

Hacker News user comment, Image/Lei Technology
We may not know the full story behind it, but we do know that GPT-4.5 underwent training changes, with the core introduction of "Scaling unsupervised learning" to enhance the accuracy and intuition of the world model. This is a key innovation behind GPT-4.5's improvements in EQ and hallucinations.
Moreover, unsupervised learning allows the model to learn language patterns and knowledge from vast amounts of unlabeled data, using derivative data from smaller models to train larger and more powerful models. In a sense, this is also one of GPT-4.5's greatest contributions, proving the possibility of training large models using smaller models, rather than just distilling small models from large ones.
However, regardless, GPT-4.5's training and reasoning costs are indeed unacceptable. Let's look forward to the surprises that DeepSeek-R2, rumored to be released ahead of schedule, will bring.

Image/DeepSeek
Postscript
Earlier this year in January, Sam Altman penned a "six-word story" on X: "near the singularity; unclear which side." Simply put, it translates to "The singularity is near; it's unclear which side we're on."
Subsequently, the nuclear-level impacts brought by DeepSeek-V3 and R1 forced Sam Altman to admit that OpenAI's closed-source strategy was "on the wrong side." Consequently, everyone began turning to DeepSeek, which offers strong performance and high cost-effectiveness, including new generations of highly cost-effective large models like Gemini.
But returning to the model itself, GPT-4.5 is actually quite good, with a larger knowledge base, enhanced creativity, and a more natural conversation style. It also does not require waiting for AI to execute detailed step-by-step logic like the o series models. Honestly, many around me are already tired of the lengthy thinking process of DeepSeek-R1.
More specifically, GPT-4.5 might excel at creative and nuanced tasks, such as writing and solving practical problems. More importantly, it may produce fewer hallucinations and have stronger versatility.
At least, ChatGPT subscribers might have one more reason to renew their subscriptions, and we don't have to consider OpenAI's costs. Take myself as an example; I canceled ChatGPT Plus a few days ago due to dissatisfaction with the stability of the responses. But after reading this, I feel I need to experience it next week before deciding whether to renew.
Source: Lei Technology
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





