75% Price Drop! DeepSeek's "Off-Peak Pricing" Strategy Puts Pressure on Competitors
 03/03 2025
03/03 2025
 712
712
AI is becoming more affordable, and that's great news.

DeepSeek continues to shake things up in the AI world.
As part of the officially designated "Open Source Week," DeepSeek has gradually open-sourced four projects this week, with the latest release being DualPipe on Thursday. DualPipe enables bidirectional parallelism for computation and communication. Simultaneously, DeepSeek has introduced a medium-sized event—off-peak pricing.
On Wednesday, February 26th, DeepSeek announced that starting that day, during the overnight idle period from 00:30 to 08:30 Beijing time, the DeepSeek Open Platform will launch an off-peak discount event. Just the day before, DeepSeek had resumed its official API recharge service.
Regarding discounts, DeepSeek is undeniably generous. According to the official announcement, DeepSeek API call prices will be significantly reduced during the overnight idle period: DeepSeek-V3 will be reduced to 50% of the original price, and DeepSeek-R1 will drop even lower, to 25% (a 75% reduction).
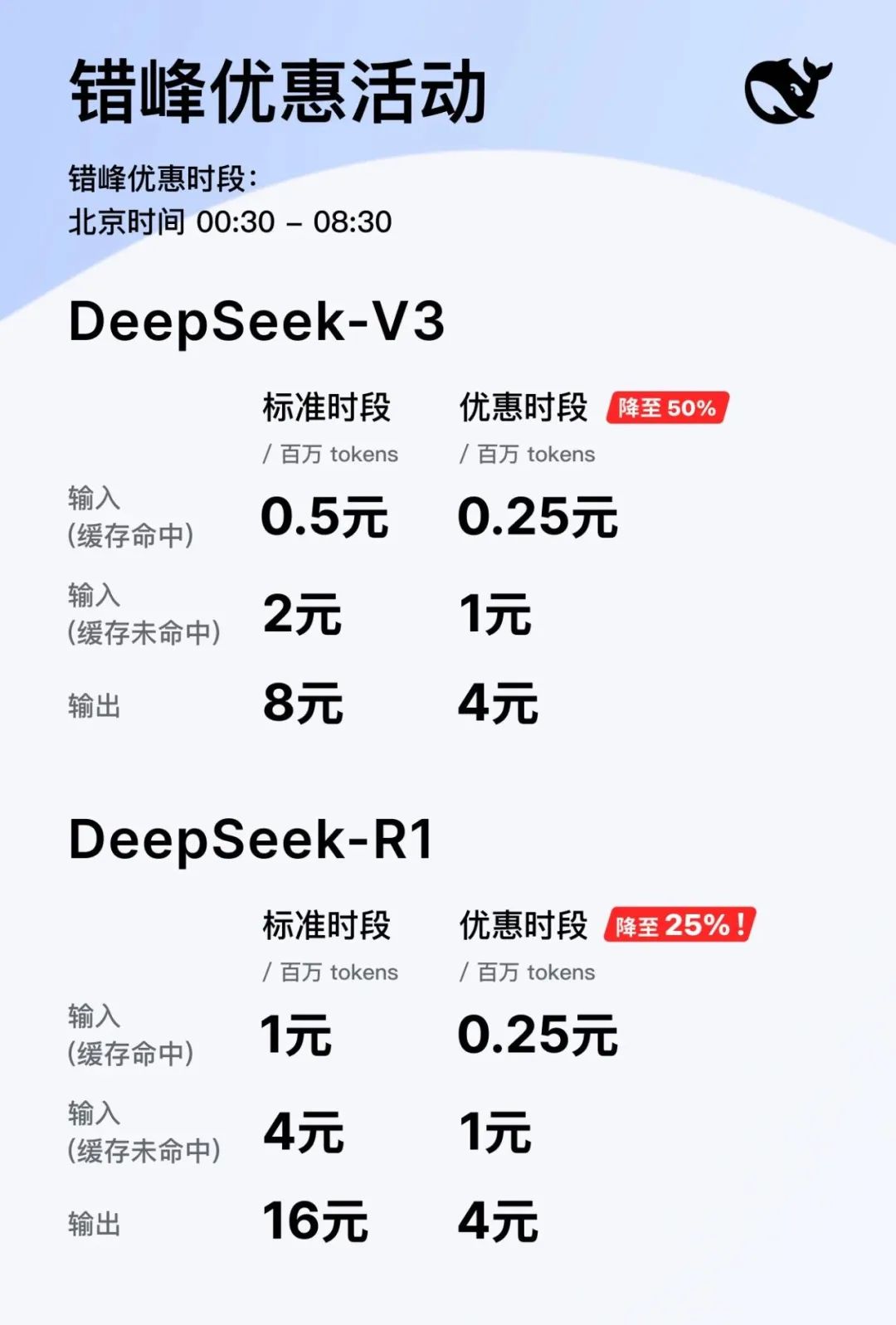
Image/ DeepSeek
The specific price adjustments are shown in the image, so I won't elaborate further. In short, it's like giving our brothers a "sweet deal."
It's worth mentioning that unlike the "discounted experience period" at the initial launch of DeepSeek-V3, which had a clear time limit, this off-peak discount only has a "time period restriction" and no "duration limit." In other words, we can consider the off-peak discount as a long-term strategy:
"Off-Peak Pricing."
Another point worth noting is that not only do the two models share the same discount period, but their prices after the discount are also identical:
Input (cache hit) is 0.25 yuan / million tokens;
Input (cache miss) is 1 yuan / million tokens;
Output is 4 yuan / million tokens.
This may be a deliberate move by DeepSeek.
Inference models have become a consensus among large model vendors. By aligning pricing during discount periods, DeepSeek can reduce developers' cost concerns when using DeepSeek-R1, blurring the boundaries between the two models and encouraging developers to flexibly call either model based on their needs.
This is similar to Claude 3.7 Sonnet, the world's first hybrid inference model launched by Anthropic a few days ago, which combines the advantages of "quick answers" from traditional models and "advanced reasoning" from inference models to achieve more flexible computation and a more suitable AI experience.
Image/ Claude
However, the core change in DeepSeek's latest adjustment is the adoption of the "off-peak pricing" strategy. The "obvious" advantages of this strategy are likely to trigger follow-up actions from other large models such as Doubao and Tongyi Qianwen, and could even spark another price war among large models:
Just like the price war that erupted after the release of DeepSeek-V2 in early 2024.
DeepSeek-R1 Price Slashing! Cheaper than Doubao and Others?
It's worth noting that DeepSeek-V3 has already experienced a price drop before. LeiTech previously reported the end of the "discounted experience period" for DeepSeek-V3 earlier this month. Before that, the all-time discount price was even cheaper than the current off-peak price:
Input (cache hit) was 0.1 yuan / million tokens;
Input (cache miss) was 1 yuan / million tokens;
Output was 2 yuan / million tokens.

It ended in early February, Image/ DeepSeek
But unlike DeepSeek-V3, DeepSeek-R1 has not had any price changes since its launch, with input (cache hit) at 1 yuan / million tokens, input (cache miss) at 4 yuan / million tokens, and output at 16 yuan / million tokens.
Relatively speaking, this makes the 75% off "off-peak discount" for DeepSeek-R1 even more surprising.
First, in terms of capabilities, there's no need to emphasize the performance of DeepSeek-R1 today. Whether it's the innovation of the chain-of-thought at the product level or the extreme cost efficiency achieved at the engineering level, DeepSeek-R1 has become the most successful model to date.
On this basis, price reductions are undoubtedly one of the most powerful strategies to lower developers' calling costs and thresholds, indirectly promoting better AI experiences to more AI applications (through integration with DeepSeek).
In fact, DeepSeek's prices during standard periods are already cheaper than many large models from other vendors, and during discount periods, DeepSeek is even cheaper than many mainstream large models:
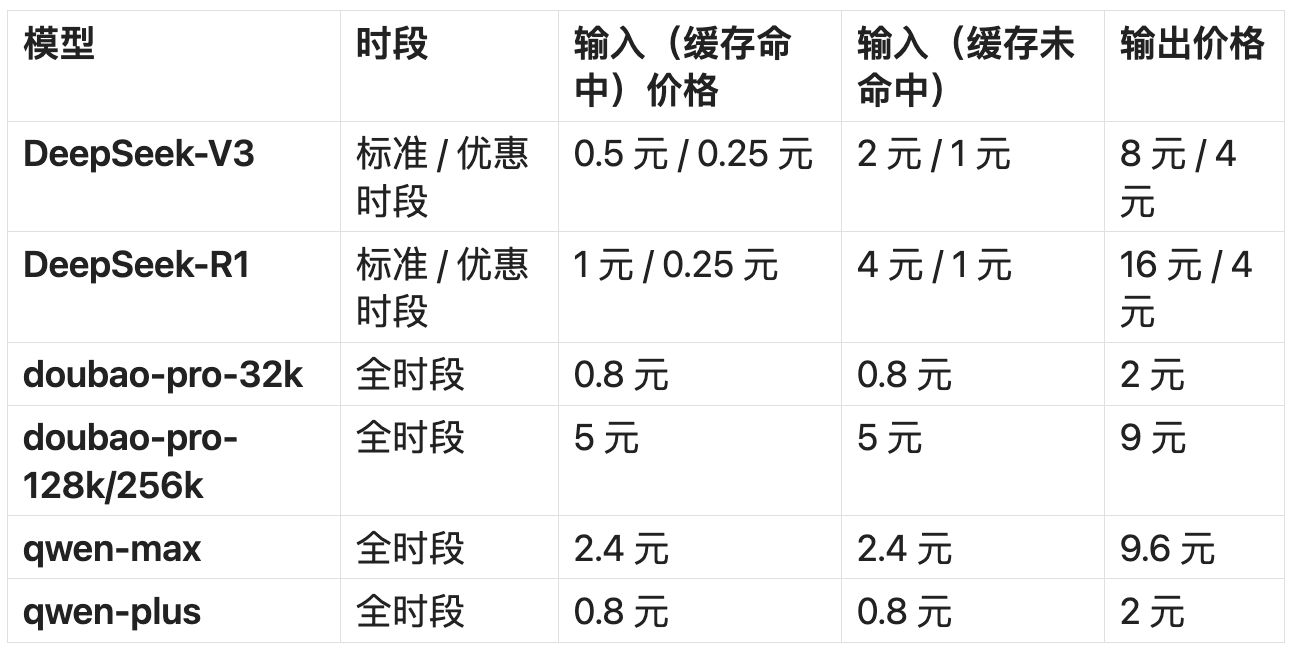
Unit is per million tokens, Image/ LeiTech
Taking Doubao's general model under ByteDance as an example, the prices displayed on the Volcano Engine platform are: doubao-pro-32k, input is 0.8 yuan / million tokens, output is 2 yuan / million tokens; doubao-pro-128k / doubao-pro-256k, input is 5 yuan / million tokens, output is 9 yuan / million tokens.
We can even see that the price of deepseek-r1-distill-qwen-32b (distilled version) on Volcano Engine is: input 1.5 yuan / million tokens, output 6 yuan / million tokens.
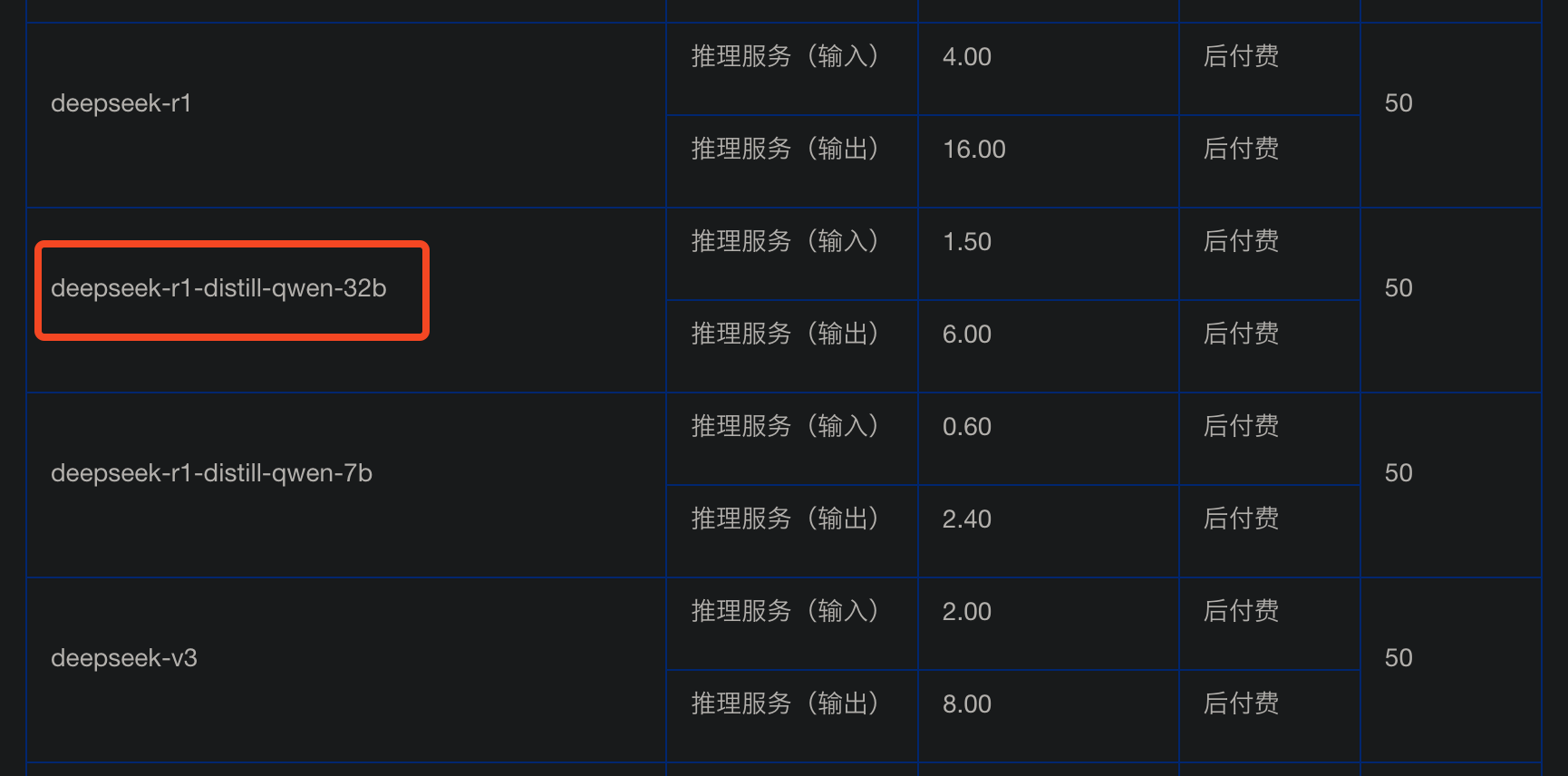
In other words, the price of the official full-featured version of DeepSeek-R1 during discount periods is even cheaper than the 32b distilled version.
This is only in China. DeepSeek-R1/V3 has also launched the same operating strategy overseas, with significant price reductions of 50% and 75%, and the discount period directly corresponds to 00:30 to 08:30 Beijing time. This means that users in London can enjoy DeepSeek's official discount period prices from 16:30 to 00:30 London time, and users in New York can enjoy them from 11:30 to 19:30 New York time.
In other words, DeepSeek has even stronger appeal for developers targeting overseas user markets, equivalent to enjoying discount period prices during peak hours.
The off-peak discount is very attractive, so how will Doubao and others respond?
Off-peak pricing itself is not uncommon, such as the off-peak electricity pricing we are most familiar with, where there can be a significant price difference for electricity use at different times.
To avoid electricity shortages during peak hours and idle electricity during off-peak hours, China has set up peak and off-peak electricity prices to encourage users to use electricity during off-peak hours through peak-to-valley price differences, thereby maximizing the allocation of grid resources while helping users save electricity costs and tapping into more economic and ecological benefits.
In fact, DeepSeek officials also mentioned a similar statement in the press release, stating that the launch of the off-peak discount event is to: "encourage users to make full use of this period and enjoy a more economical and smoother service experience."

From the developer's perspective, this off-peak pricing strategy is beneficial with few drawbacks. From the perspective of large model vendors and cloud computing platforms, it is also more advantageous than disadvantageous, as it can maximize the utilization of server resources.
Therefore, it should be considered a matter of course for large models to adopt the off-peak pricing strategy, with only slight adjustments in specific strategies, such as addressing different time zones (different user markets) mentioned earlier.
However, will DeepSeek's move trigger a chain reaction in the industry, or even replicate the large model price war of a year ago? Perhaps it remains to be seen.
Many AI enthusiasts may remember that in early May 2024, the relatively unknown DeepSeek released the second-generation MoE large model DeepSeek-V2, which introduced the Multi-head Latent Attention (MLA) mechanism for the first time. With 236 billion parameters and 21 billion active parameters per token, it could be considered the strongest open-source MoE model at that time.

Abstract of DeepSeek V2 technical paper, Image/ LeiTech
But more importantly, the price of DeepSeek-V2 was: input 1 yuan / million tokens, output 2 yuan / million tokens.
It may not seem impressive now, but this price was only nearly 1% of that of ChatGPT's main model GPT-4 Turbo at the time, directly outperforming many large models both domestically and internationally in terms of cost-effectiveness. This made many people remember this large model vendor named "DeepSeek (Deep Search)" and dubbed it the "Pinduoduo of the AI world".
What was even more impressive was that after DeepSeek-V2, a price war among China's large models was triggered. Major companies such as ByteDance, Tencent, Baidu, and Alibaba all lowered their prices. Tongyi Qianwen's main model Qwen-Long, which is comparable to GPT-4, even saw its API input price drop from 20 yuan / million tokens to 0.5 yuan / million tokens.
The "off-peak pricing" strategy may be difficult to promote alone, but considering the series of capabilities DeepSeek has demonstrated during Open Source Week, such as breakthroughs in long contexts and improvements in chip utilization efficiency, it may not be the "new beginning" of another round of large model price wars.
Final Thoughts
DeepSeek is undoubtedly the biggest catalyst in the AI industry this year, forcing industry leader OpenAI to make many responses. According to multiple media reports, OpenAI recently plans to launch the "long-awaited" GPT-4.5.
Of course, the pursuit and even surpassing of other large model vendors are also forcing DeepSeek to accelerate its pace. The latest Reuters report points out that the new generation of R2 inference model is indeed coming, and DeepSeek originally planned to launch it in May but has recently considered launching it earlier.
These changes are driving the iteration and progress of AI, and are also transforming the world today.
Source: LeiTech
-
![]()
Hardware is the skeleton, AI is the soul, and data integrates the two
-
![]()
China’s AI Industry: A Unified Pivot Towards Monetization?
-
![]()
New Progress! Infineon Completes Acquisition of ams OSRAM's Non-Optical Sensor Business
-
![]()
35 Million Bet on an Optical Future! Tengjing Technology Makes a Move in AR
-
![]()
Why World Models Get Stuck on Construction Roads in Autonomous Driving Applications
-
Alibaba Initiates Cultural Transformation: Is Jack Ma Making a Strategic Comeback?
-
Tianfeng Heads to Hong Kong for IPO with RMB 3.8 Billion in Funds: Xingyu's Cross-Border Foray into Embodied AI Faces Uncertain Future
-
![]()
Mengshi Auto’s High-End Aspirations Dashed: Huawei Partnership Fails to Revive Sales, New Model’s Entry Price Dips Below 300,000 Yuan





