"Official Announcement of the New Open-Weight Model! OpenAI Finally Follows in DeepSeek's Footsteps."
 04/02 2025
04/02 2025
 516
516
After hinting at the launch of an open-weight model for over a month, OpenAI appears poised to fulfill its promise.
On April 1, OpenAI CEO Sam Altman publicly announced on social platform X (formerly Twitter) that OpenAI plans to release a potent open-weight large model with reasoning capabilities in the coming months.
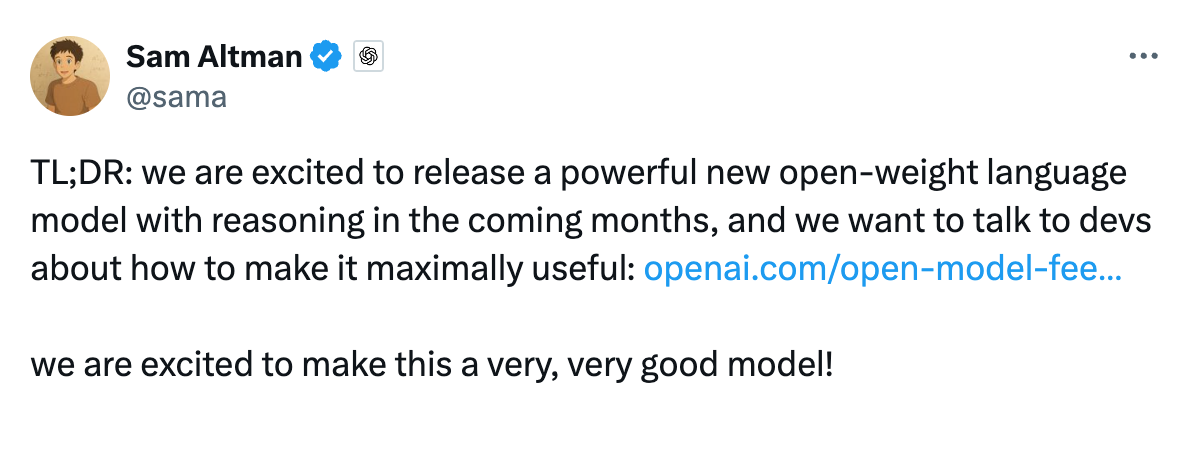
Image/ X
Will it be a reasoning model akin to DeepSeek-R1? Or a dialogue model integrated with reasoning capabilities? This remains to be seen. However, if all goes as planned, this new large model will mark OpenAI's first open-weight large model since GPT-2.
Upon the announcement, domestic and foreign technology media swiftly followed up, with numerous Chinese media outlets using headlines such as "OpenAI Announces/Will Soon Release an Open-Weight Model." Some industry observers also view this as a symbolic step for OpenAI to "return to open-source."
Image/ Google
After all, the open-source model community has become increasingly vibrant following the release of DeepSeek-V3/R1, making OpenAI's closed-source approach increasingly out of step.
However, upon closer inspection of Sam Altman's original statement, it becomes evident that he did not use the term "open-source"; instead, he employed the more cautious term "open-weight" as the prefix for the new model.
Can "open-weight" be equated with "open-source"? This has sparked discussions and even debates among netizens. Notably, "open-weight" refers to the public availability of parameters obtained after model training, allowing developers to deploy, test, and even fine-tune based on these weights. However, it does not encompass training data, does not come with complete training code, and does not guarantee unhindered usage.
This differs markedly from the "open-source" concept understood by many—that is, full transparency and free usage of code, data, and methods.
In this sense, "open-weight" seems more like a compromise: it retains core technological barriers while releasing some capabilities to the developer community. While it lowers barriers to model usage, it falls short of meeting the genuine needs for verifiability and reproducibility.
So, is OpenAI truly embracing open-source again, or is it redefining "openness" with ambiguous language? To some extent, the debate over "true open-source" versus "fake open-source" may be far more noteworthy than the model release itself.
From Alibaba's Qwen to DeepSeek: Is an "open-weight" model synonymous with an "open-source" model?
Fairly speaking, OpenAI's decision to adopt an "open-weight" approach for its new model is not surprising.
In fact, DeepSeek, Qwen (Alibaba), and LLaMA (Meta) are considered the "main forces" in the open-source model community. Although their open-source strategies have distinct emphases, their core commonality is the opening of weights, enabling external developers to directly deploy models and providing reasoning code, fine-tuning scripts, evaluation tools, etc.

DeepSeek press release, Image/ DeepSeek
This implies that developers can directly download the model for local deployment, fine-tuning, and reasoning services, which can be considered the minimum threshold for "open-source" large models.
From this perspective, OpenAI's announcement to release a new model using the "open-weight" approach aligns with the mainstream method in the current open-source model community. In fact, in terms of definition, it is not dissimilar from most large models currently labeled as "open-source" in the market.
However, despite all being open-weight, the actual degree of openness varies.
Take DeepSeek, for example. It has released models such as V2, V3, and R1, all of which have open weights and corresponding technical reports. Additionally, DeepSeek adopts the MIT open-source license, which imposes very few restrictions, allowing anyone to freely use, modify, distribute, and commercialize software or models. This is also one of the key reasons why many developers and vendors prefer to use DeepSeek models.
Alibaba's Qwen model, in addition to open weights, utilizes the equally permissive Apache 2.0 open-source license, permitting users to freely use, modify, and distribute code, including for commercial purposes, with only the requirement to retain original copyright and license notices. For developers, the Qwen series of models offers a relatively mature choice that balances performance and flexibility.

Alibaba's earlier QVQ-Max also adopts the Apache 2.0 license, Image/ Github
In contrast, while Meta's LLaMA also opens model parameters and reasoning scripts, its usage agreement includes more restrictions. Starting from LLaMA 2, Meta adopted a more permissive license (LLaMA 3.1 is even more open), but developers still need to apply for usage and cannot directly use it for certain commercial applications or release services. This has led to its high popularity in the open-source community but limited application scenarios.
In summary, although all three claim to be "open-source models," a closer examination of "open-source" across several dimensions—open weights, open code, open data, open training process, open usage rights—reveals that none are "fully open." They do not disclose complete training data nor provide reproducible training code. In other words, you can use their model, but you cannot rebuild it from scratch.
From this perspective, although the specific open-source strategy for OpenAI's upcoming model has yet to be announced, if it also opens model weights and reasoning code, supporting local deployment for developers, then, according to industry practice standards, it can be fully classified as an "open-source model" today.
OpenAI Returns to Open-Weight, and the New Model Will Be an o3-mini-Level Reasoning Model
While many believe that OpenAI began with open-source, in reality, at least during the GPT-2 era, OpenAI already had plans for a "closed-source route."
GPT-2 was released in early 2019, and OpenAI initially refused to release the code citing "risks of malicious use." However, amid public criticism that OpenAI was "exaggerating the risk," they released the full-fledged GPT-2 with 1.5 billion parameters at the end of 2019. Nonetheless, starting with GPT-3, OpenAI completely embarked on a closed-source path, no longer disclosing weights, code, or training data.
Therefore, this "re-opening" can be seen as a signal from OpenAI to the community. However, it must be clarified that, based on Sam Altman's use of the term "open-weight," OpenAI's new model will likely resemble today's DeepSeek, Qwen, and LLaMA: opening model weights and reasoning code but not including training data or complete training code.

Image/ OpenAI
Nevertheless, the specific open-source license adopted by OpenAI needs to be considered. If OpenAI's new model adopts the more mainstream Apache 2.0 open-source license, akin to the Qwen series, it may have minimal impact on most developers. Developers can still perform local deployment, reasoning services, and even fine-tuning and adaptation based on weights, despite the model's training remaining a "black box."
Another point worth anticipating is that Sam Altman hinted in February this year that OpenAI's open-weight model would be at either the "o3-mini level" or the "mobile side level." Combined with his recent tweet mentioning a "powerful new open-weight model with reasoning," it can be inferred that OpenAI has ultimately chosen an "o3-mini level" model to break the ice on its open-weight path.
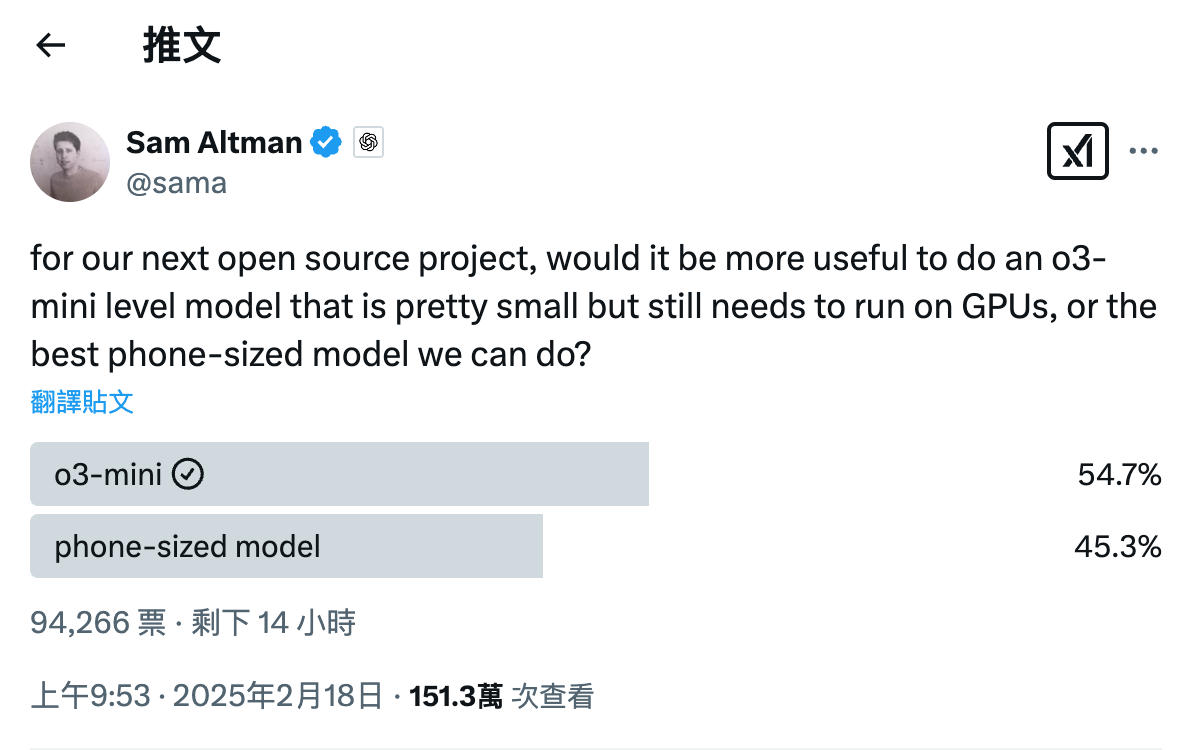
Image/ X
This is understandable. Today, reasoning capability is a consensus in the development of large models and a focal point of external attention. If OpenAI aims to return to the open-source community through an "open-weight" model or solidify its industry position, launching an "o3-mini level" open-weight model is a more effective choice.
Of course, OpenAI has already started organizing developer preview events in San Francisco, Europe, and the Asia-Pacific region, inviting developers to try out the model prototype in advance and collect feedback. Perhaps in the coming period, we will hear and see more news about OpenAI's open-weight new model.
Postscript
For OpenAI, the significance of this return to the open-weight community extends far beyond the release of a model.
Over the past two years, the open-source model ecosystem has flourished rapidly without OpenAI's participation. Meta, Mistral, Qwen, DeepSeek have taken turns to build models and ecosystems, gradually forming a large-scale open-source model ecosystem.
Especially after DeepSeek-V3/R1, an increasing number of hardware and software vendors have joined the open-source model ecosystem, completely abandoning the path of independently training large models and focusing instead on model fine-tuning and application deployment.
For OpenAI, this undoubtedly poses a potential "threat," akin to the threat posed by the Android (open-source) ecosystem to iOS in the past. It is not difficult to understand why Sam Altman would admit that "OpenAI's closed-source strategy is on the wrong side."
Yet, OpenAI remains OpenAI, and the leadership of the GPT/o series of models is undeniable. Its upcoming open-weight model may very well reshape the entire open-source model community.
Source: Lei Technology
-
![]()
A Humanoid Robot Becomes an Office Intern: The 'Reinforcement Learning' Journey of a Former NVIDIA Engineer
-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?