OpenAI Makes a Move: Officially Announces Open-Weight Model Release, Crossing the River with DeepSeek's Stones
 04/02 2025
04/02 2025
 639
639


Editor: Yuki | ID: YukiYuki1108
After hinting at the launch of an open-source model in early April 2025, OpenAI CEO Sam Altman officially announced on social platform X that OpenAI plans to release a large reasoning-capable "open-weight" model in the coming months. This announcement quickly garnered widespread attention from tech media and industry insiders, with many Chinese outlets reporting it under headlines like "OpenAI Previews Upcoming Open-Source Model Release." Some experts viewed this as a significant step for OpenAI to return to open-source practices.
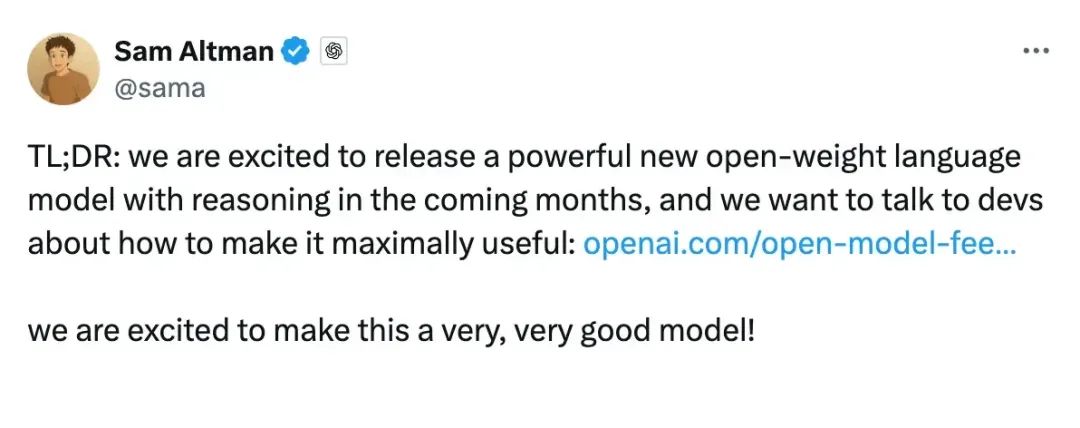
However, does "open-weight" equate to "open-source"? The answer is nuanced. There are notable differences between the two terms, both in OpenAI's usage and in industry practice. This article delves into these distinctions.
I. Conceptual Clarification: "Open-Weight" vs. "Open-Source"
First, it's essential to understand that "open-weight" and "open-source" are distinct concepts.
"Open-weight" refers to the public release of model parameters (weights) post-training, enabling developers to deploy, test, or fine-tune models based on these parameters. However, it does not include training data, the full training code, or explicit usage permissions. This means developers can use the parameters for local deployment and inference services (e.g., dialogue generation, text classification) but cannot reproduce the training process or freely modify the model's underlying architecture.
Conversely, "open-source" encompasses a broader scope. It involves the public release of code (both training and inference code), training data, methodological transparency, and usage permissions. The core of open-source is comprehensive transparency and free usage.
Thus, "open-weight" can be seen as a subset of open-source, lowering barriers to model usage (like local deployment and fine-tuning) but not fulfilling the requirements for true verifiability and reproducibility.

II. Industry Practice: "Open-Weight" as the New Norm
Despite the differences between "open-weight" and "open-source," "open-weight" has emerged as the industry standard for large models.
Consider the examples of DeepSeek, Qwen (Alibaba), and LLaMA (Meta):
DeepSeek: Its V2, V3, and R1 series all adopt an "open-weight" strategy. Additionally, DeepSeek provides technical reports and uses the MIT open-source license with minimal restrictions, allowing for free use, modification, distribution, and commercialization.
Qwen (Alibaba): The Qwen series not only discloses weights but also adopts the Apache 2.0 license, enabling users to freely use, modify, and distribute code, including for commercial purposes, with only the requirement to retain original copyright and license notices.
LLaMA (Meta): While the LLaMA series also discloses parameter inference scripts, its usage agreements are more restrictive. Starting with LLaMA2, Meta adopted a more relaxed license (LLaMA3 is even more open), but usage still requires an application and cannot be directly used for certain commercial application release services, limiting deployment scenarios.
These cases illustrate that while all three claim to be "open-source," a closer examination reveals that none are fully open in terms of disclosing complete training data or providing reproducible training code.

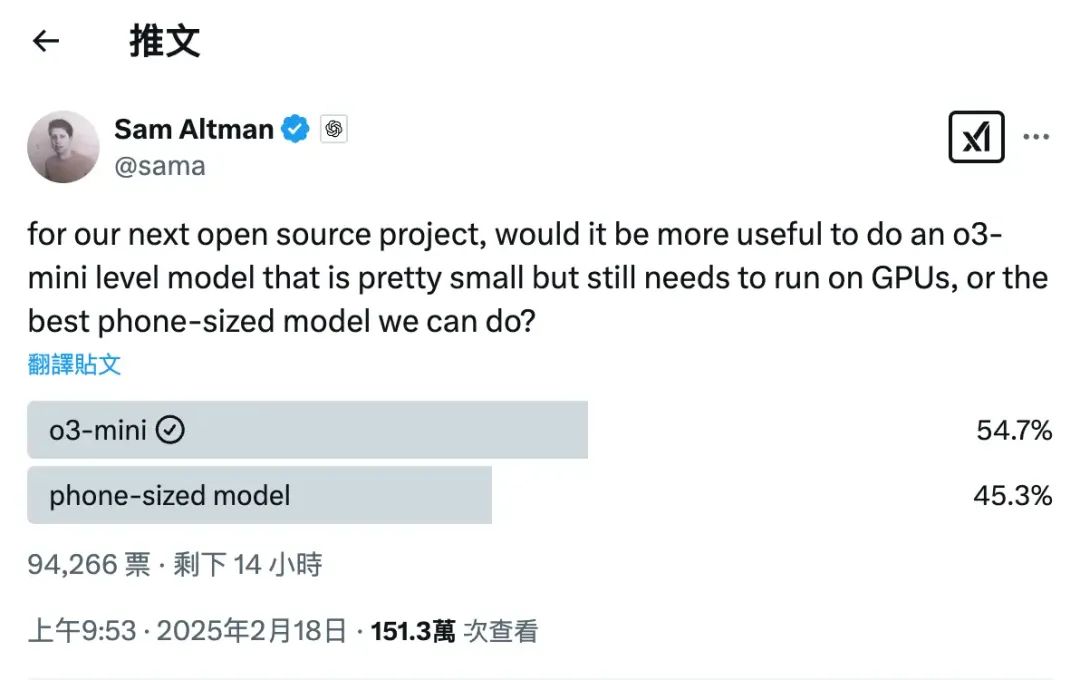
III. Positioning OpenAI's New Model: "o3-mini Level"
Based on Sam Altman's hints in February 2025 and his latest tweet about a "powerful new open-weight model with reasoning," it's evident that OpenAI has chosen an "o3-mini level" reasoning-based large language model to enter the open-weight scene.
The "o3-mini level" refers to medium-to-small large language models with strong reasoning capabilities suitable for lightweight deployment. This type meets enterprise-level application needs while reducing hardware costs, making it a popular choice in the market.
IV. "Return" or "Compromise"?
For OpenAI, this return to the community signifies more than just a release. Over the past two years, Meta, Mistral, Qwen, and DeepSeek have built and developed their ecosystems, gradually forming a large-scale industry landscape. Especially after DeepSeek-V3/R1, more hardware and software vendors have joined, significantly altering the industry. As a former leader, OpenAI's closed-source strategy has marginalized it. Thus, this partial return can be seen as a response to competitive pressure and a strategic adjustment.
V. "Truly Open" or "Selective Openness"?
While many associate OpenAI with open-source origins, it had plans for a closed-source approach as early as the GPT-2 era. In early 2019, GPT-2 was released with limited access due to concerns about malicious use, but public opinion deemed these risks exaggerated, leading to the release of the full 1.5 billion-parameter version later that year. However, starting with GPT-3, OpenAI fully transitioned to a closed-source model, no longer disclosing weights, code, or training data. Therefore, this re-entry can be viewed as a signal to the community, but it's crucial to note that based on Sam Altman's statements, it's likely to follow a similar path as DeepSeek, Qwen, and LLaMA:
Advantages: Lower barriers, support for local deployment and fine-tuning, adaptability. Disadvantages: Inability to reproduce the entire process, challenging to meet true openness demands.
-
![]()
A Humanoid Robot Becomes an Office Intern: The 'Reinforcement Learning' Journey of a Former NVIDIA Engineer
-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?