Why Embrace World Models Amidst the Large Language Model Boom?
 04/11 2025
04/11 2025
 724
724

Turing Award recipient Yann LeCun contends that the large language models currently pursued in AI have inherent limitations. They struggle with understanding the physical world, possessing long-term memory, exhibiting reasoning capabilities, and demonstrating complex planning abilities.
To overcome the first challenge, we turn to a technology known as world models.

While this may sound abstract, consider Google's 3D games and Tesla's autonomous driving. World models enable machines to distinguish physical spaces, grasp physical laws, and make decisions based on experience, akin to human reasoning.
Unlike large language models, world models do not generate probabilities from vast text corpora. Instead, they infer causality after deeply analyzing large-scale real-world videos.
Like infants, they construct cognitive understanding of the world through interactive learning.

Imagine a newborn baby, whose vision is not fully developed, piecing together the world through fragments of touch, temperature, and sound. Over millions of years, the human brain evolved to convert sensory information into an understanding of physical laws—a capability today's AI lacks.
World models aim to reconstruct such understandings of concepts like gravity and time from data.
The concept of world models traces back to cognitive science and control theory in the 1980s to 1990s. Influenced by psychology, researchers proposed that AI systems need to simulate internal models of the environment to make predictions and decisions.
An important element here is the environment. Biologically, behavior follows a stimulus-response pattern, where responses are direct reactions to environmental stimuli.

Over billions of years, animals developed senses and psychology, perceiving the world through vision, hearing, smell, etc., generating emotions like excitement and fear. Humans further developed self-awareness, allowing autonomous planning and purposeful decision-making.
Comparing biological evolution with AI development, the ultimate form of AI, AGI, aims to autonomously perceive reality, plan, and make purposeful decisions.
The rudiments of world models emerged from psychologists' observations of how humans and animals understand and decide. David Rumelhart's 1990 mental model theory emphasizes that agents need abstract representations of the environment.
For instance, the human brain has an internal cognitive framework for the world, making decisions based on experience, like associating dark clouds with rain. Similarly, world models enable machines to understand and predict their surroundings, like associating fire with burns.
However, early world model research remained theoretical. Clear definitions and goals existed, but no specific technical path.

From the 2000s to 2010s, research on world models took shape in the computational modeling stage. With reinforcement learning and deep learning advancements, scholars began constructing trainable world models using neural networks.
Reinforcement learning enables learning strategies through reward and punishment mechanisms, akin to training a dog. Deep learning automatically learns rules from vast data, akin to alchemy.
In 2018, DeepMind's "World Models" paper pioneered a "VAE+RNN+Controller" architecture to predict the environment, marking a milestone in modern world models.
This process resembles "dreaming"—compressing real scenes into data, deducing future possibilities using RNNs, and guiding actions with a controller. This intracranial deduction ability reduces trial-and-error costs.
After 2022, world models entered the large model era. With Transformer's sequence modeling and multimodal learning, their scope expanded from single to cross-modal simulations, transitioning from 2D to 3D (e.g., OpenAI's GATO and DeepMind's Genie).

Recent research, like Meta's VC-1 and Google's PaLM-E, brought world models into the spotlight. Combining them with large language models for broader environmental reasoning has become a technological path.
Google's PaLM-E (562 billion parameters) successfully integrates language models with visual and sensor data. The robot understands complex instructions and adapts to new environments. Meta's open-source multimodal framework for the Llama series further advances 3D perception research.
In summary, world models have evolved from conceptual deduction to practical implementation, gradually emerging from chaos to clarity.

Transformer's evolution and multimodal data explosion propelled world models from training grounds to gaming arenas and the real world. Google and Tencent generate realistic game scenarios, Tesla predicts vehicle trajectories, and DeepMind models global weather.
Like human infants learning through games, world models' first challenge is gaming.
Early applications relied on virtual environments with clear rules, like Atari games (DQN) and StarCraft (AlphaStar). Later, CNNs/RNNs processed image inputs.

Evolving to 3D, Google DeepMind's Genie 2 generates interactive infinite 3D worlds from a single image, allowing users to explore dynamic environments. Tencent, HKUST, and USTC's GameGen-O model generates game characters and scenes with high fidelity and complex physical effects.
After extensive training, world models transitioned to industrial scenarios.
Game engines' core capability is constructing high-fidelity, interactive 3D virtual environments, transferable to industrial settings for fault simulations.

Boston Dynamics rehearses robot movements in virtual environments before physical application. Tesla's 2023 world model integrates game engine simulation technology, reducing real road test data dependence. NIO's intelligent world model deduces scenarios and makes plans in short periods.
Recently, world models entered basic research.
DeepMind's GraphCast processes millions of grid meteorological variables, predicting weather 1000 times faster and with 1000 times less energy than traditional simulations. Its graph neural network learns weather system dynamics from historical data, predicting global weather accurately and efficiently.
From virtual to real-world scenarios like autonomous driving, world models' essence is understanding physical laws through multimodal data. The "world model + large language model" may become AGI's core architecture, enabling AI to not just chat but truly understand and decide to change the world.
Why do we need world models amidst the large language model boom? What makes them irreplaceable?

The key to AI's transition from imitation to true understanding, overcoming uncanny valley effects, is letting it comprehend the world, real space, and physical laws. This understanding goes beyond mechanical token prediction based on data correlation.
Large language models, based on text corpora and reinforcement learning, cannot achieve this. Only world models can.
Traditional AI is a data-driven passive reaction system. World models understand physics and collisions by constructing internal virtual environments, pre-enacting action consequences like humans, and sharing reasoning power in gaming and robotics.
First, world models construct human-like mental models through underlying modeling and multimodal integration. Externally, they simulate physical laws and understand social rules and biological behaviors. Internally, they form spatio-temporal cognitive abilities through perception, prediction, planning, and learning coordination.

Second, world models possess causal prediction and counterfactual reasoning abilities. They predict future outcomes based on current states and actions, enabling effective decisions even with scarce data. This is widely used in autonomous driving.
Finally, world models acquire cross-task and cross-scenario generalization capabilities through self-supervised learning, unlike traditional models requiring fine-tuning for specific tasks.
But why can't large language models achieve these abilities?
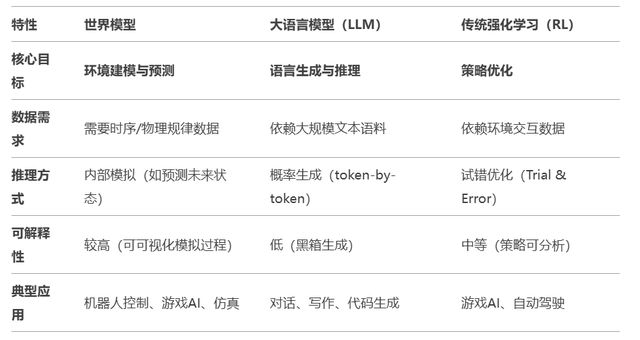
World models' predictive ability differs from large language models' token prediction. The former involves causal reasoning, while the latter is probabilistic association.
Large language models (e.g., GPT series) focus on big data-driven autoregressive learning, generating text through massive text data. Essentially, it's probability prediction. World model proponents argue that autoregressive Transformers cannot lead to AGI; AI needs true commonsense understanding achievable only through deep multimodal data analysis.
At the model structure level, large language models rely on the Transformer architecture, processing text sequences through self-attention. World models, however, contain multiple modules (configurator, perception, world model, role) capable of estimating world states, predicting changes, and finding optimal solutions.
In layman's terms, large language models train text geniuses who talk the talk but lack common sense. World models are seasoned generals in a modeling environment, intuitively predicting opponents' moves.

While the world model shows great promise, it is not without its challenges.
In terms of computational power, the resources required to train a world model vastly surpass those needed for large language models. Additionally, the phenomenon of "hallucinations" or erroneous predictions remains a concern. When it comes to generalization ability, balancing model complexity with the capacity to adapt across various scenarios is a significant hurdle. Moreover, the availability of multimodal data is limited, and it necessitates rigorous annotation, making quality control paramount.
If large language models like GPT have reached a stage of articulate maturity, world models are still in their nascent, babbling phase.
In essence, the world model represents an alternative avenue for exploration beyond deep learning. Should deep learning encounter future development bottlenecks, the world model could emerge as a viable option. However, at present, the world model is still in its exploratory stage, necessitating our continued focus on the technological advancements of large language models and deep learning.
Through collaborative efforts and shared progress, we can open up new avenues for AI growth.

-
![]()
A Humanoid Robot Becomes an Office Intern: The 'Reinforcement Learning' Journey of a Former NVIDIA Engineer
-
![]()
Meta Plans to Launch Cloud Infrastructure Business: Is Computing Power Really in Excess?
-
![]()
Giants Enter the Arena One After Another: The Embodied AI Battle Commences
-
![]()
Is It More Profitable to Build 'Hands' for Robots Than 'Humans'?
-
![]()
Yunling Optoelectronics Accelerates Its Listing on the Beijing Stock Exchange: Secures 989 Million Yuan to Bolster Production of Computing Optoelectronic Chips
-
![]()
From Drill Bits to Optical Coatings: A 200-Billion-Yuan Behemoth Quietly Unveils a New Business Front!
-
![]()
New Energy Vehicle Growth Slows: Are 370 Million Existing Cars the Next Lucrative Market?
-
![]()
Is Baidu Now Fostering Its Own 'Yao Shunyu'?