Clarifying the Differences in End-to-End Architectures for Autonomous Driving
 05/08 2025
05/08 2025
 723
723
The rapid advancement of autonomous driving technology has led to a shift in design approach for intelligent driving systems, evolving from traditional modular architectures to end-to-end large models. Traditional modular architectures divide tasks such as perception, prediction, planning, and control among different modules, whereas end-to-end large models aim to directly map sensor inputs to vehicle control commands, achieving joint optimization. Despite all being end-to-end, various automakers have introduced technical architectures like modular end-to-end, dual-system end-to-end, and single-model end-to-end. What sets these end-to-end architectures apart, and how do they compare to modular-based architectures?
Traditional Modular System Architecture and Decision-Making Mechanism
Before delving into end-to-end large models, let's understand how modular-based autonomous driving architectures achieve intelligent driving. These architectures typically employ a modularized pipeline structure, connecting functions such as environmental perception, behavioral decision-making, and motion control in series. In the perception stage, the system performs object detection, segmentation, and tracking through sensors like cameras, radars, and LiDARs. In the decision-making and planning stage, it performs path planning and behavioral decision-making based on perception results and high-precision maps. Finally, in the control stage, it generates specific acceleration, deceleration, steering, and other control commands.
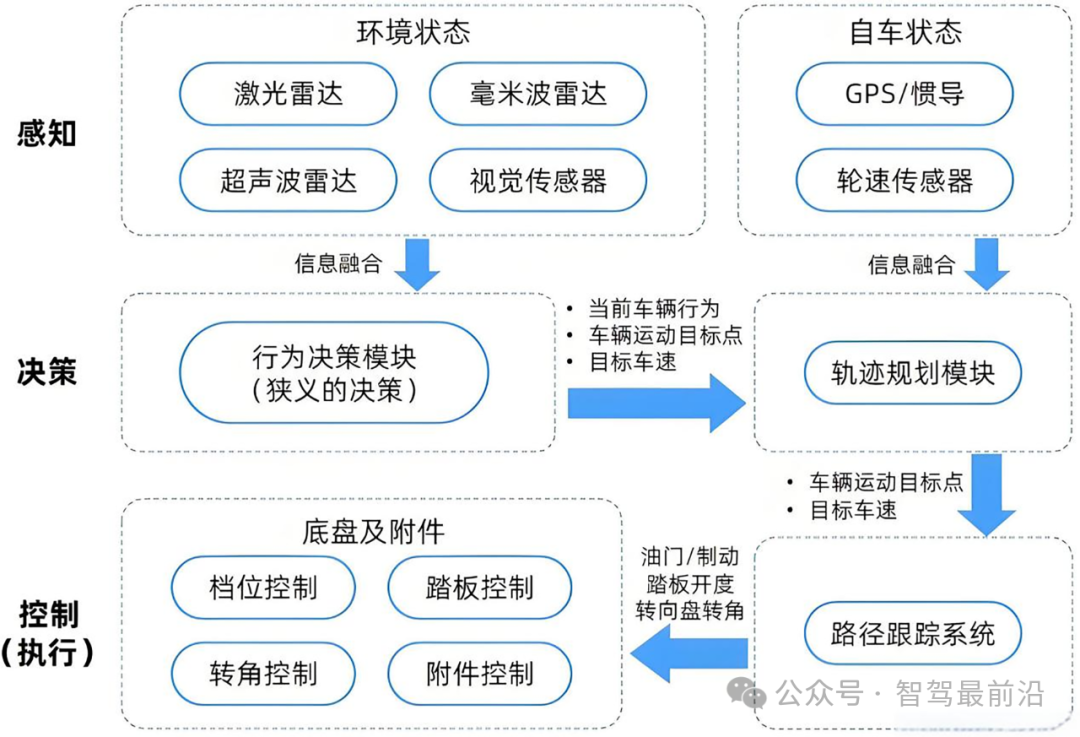
Autonomous Driving System Architecture
The advantage of modular-based autonomous driving architecture lies in the clear responsibilities of each part. These parts can be designed using abundant prior knowledge and rules, making it easy to debug and verify them individually. This technical solution first uses maps and rules to plan the desired path, then generates trajectories using techniques like the dynamic window approach or sampling optimization, and finally outputs execution commands through PID or model predictive control algorithms to achieve functions like highway NOA. However, this technology heavily relies on environmental modeling and rules, and may encounter performance bottlenecks when dealing with complex and variable traffic scenarios and long-tail anomalies.
End-to-End System Architecture and Decision-Making Mechanism
Unlike modular methods, the end-to-end (E2E) architecture directly maps sensor data to vehicle control outputs, achieving joint optimization. The concept of end-to-end is not new, as demonstrated by systems like ALVINN in 1989 and NVIDIA DAVE-2 in 2016, which used front camera image inputs and directly output steering angles through neural networks, validating the feasibility of end-to-end architecture.
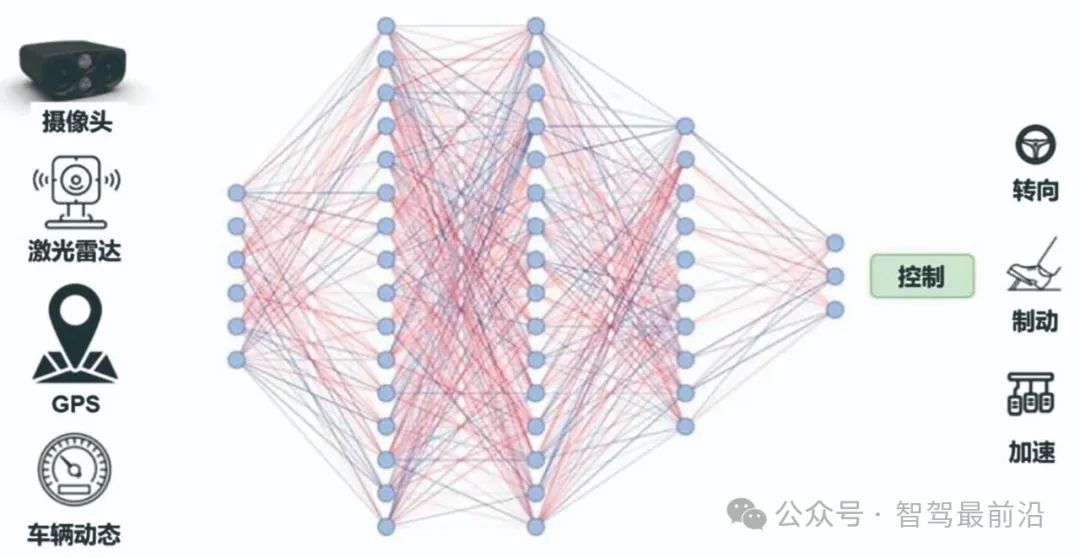
End-to-End Architecture
With the development of large-scale datasets and deep learning technologies, end-to-end autonomous driving methods have continued to emerge. Typical end-to-end decision-making mechanisms include strategies based on imitation learning (using driver operations as supervisory signals) and reinforcement learning (optimizing rewards with safety and comfort as goals). These driving models directly learn the mapping from sensors to planned trajectories or control commands. End-to-end systems can simplify structures by merging perception, prediction, and planning tasks into a jointly trainable model, enabling direct optimization of driving performance.
While end-to-end architectures offer significant advantages, the lack of explicit intermediate outputs often makes them 'black boxes,' making it difficult to explain their decision-making processes. Additionally, their reliability in extreme or rare scenarios has not been fully verified. End-to-end models require massive and diverse training data and powerful computing resources, making training optimization challenging. To balance performance and safety, some methods retain a certain modular structure within the end-to-end architecture (e.g., using semantic segmentation or object detection as intermediate representations). Recent attempts to combine visual data with language models (such as large-scale vision-language models) enhance scene semantics and causality understanding but increase system complexity and real-time challenges. Zhijia Qianyan once provided a simple graphical explanation of the transition from modular architecture to end-to-end large models, clarifying these two technologies through a story (Related Reading: What is the difference between rule-based decision-making and end-to-end large models in autonomous driving?).
Detailed Analysis of Three End-to-End Architectures
3.1 Modular End-to-End Architecture
The modular end-to-end architecture decomposes the overall planning task into differentiable sub-modules but jointly optimizes them during training and inference based on the final planning objective. This architecture retains the interpretability of the modular structure while enjoying the advantages of end-to-end training. Recent research and industrial solutions, such as Wayve's multi-task neural networks for end-to-end planning and Tesla's latest FSD V12 solution, adopt similar ideas. Tesla's solution uses an occupancy grid network in bird's-eye view (BEV) space for path planning, reducing reliance on high-precision maps and enabling more flexible responses to environmental perception after multi-sensor fusion. Simply put, the modular end-to-end architecture still retains modules for perception, prediction, planning, etc., but the parameters of each module can be jointly trained, balancing model interpretability and task-level optimization performance.
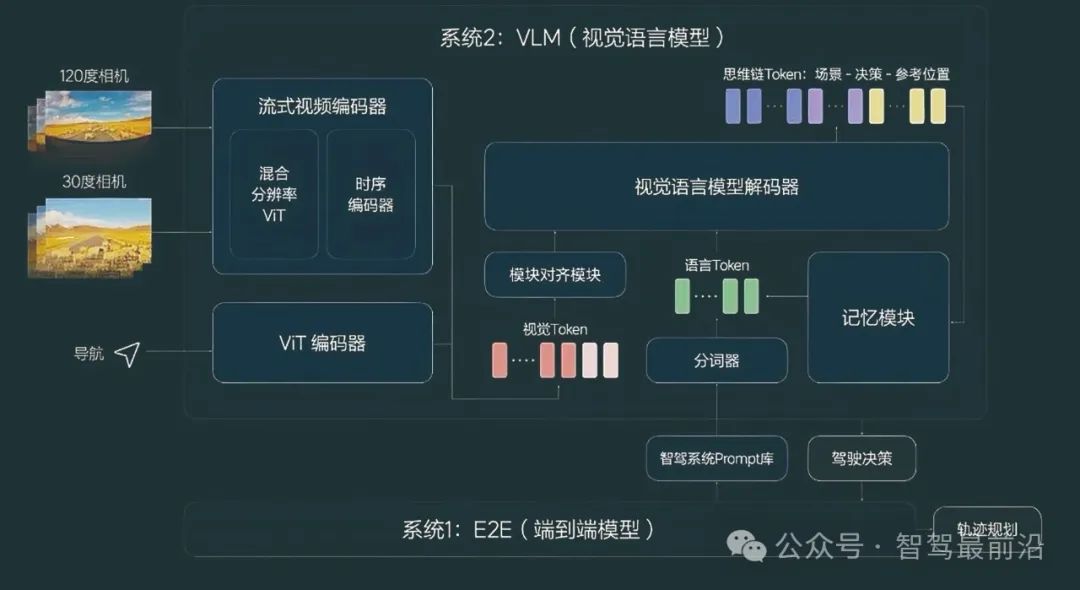
3.2 Dual-System End-to-End Architecture (End-to-End + Vision-Language Model)
The dual-system end-to-end architecture enhances the ability to understand and reason about complex scenarios by adding a vision-language assistance system to the single end-to-end model. This architecture adopts a 'fast and slow dual-system' concept, with the fast system handling immediate trajectory planning and control using end-to-end learning, and the slow system leveraging large-scale vision-language models (VLM) for high-level semantic reasoning and decision support. The dual systems cooperate to ensure intelligent driving system safety. Li Auto's latest solution uses one end-to-end neural network for real-time driving control and another vision-language model for scenario semantic analysis, providing supplementary information and decision-making suggestions. Changan Automobile's 'Tianshu' large model architecture also adopts a 'brain and cerebellum' structure, with the 'brain' part responsible for complex reasoning and the 'cerebellum' for specific planning and control. The decision-making mechanism typically involves the end-to-end model quickly generating an initial path, while the vision-language model analyzes the environmental context and revises or enriches the planning results when necessary. However, this solution requires the simultaneous operation of two large models, consuming significant computing power, and requires special design and optimization for coordination efficiency and consistency.
3.3 Single-Model End-to-End Architecture
The single-model end-to-end architecture (One Model E2E) aims to complete all autonomous driving tasks, including perception, prediction, and planning, using a unified multi-modal large model. Inspired by large-scale language and vision-language models, this approach strives to build a 'general foundation model for the driving domain.' Recent industry attempts, such as DriveMM, a novel large-scale multi-modal model, can process various inputs like images and multi-view videos and perform a wide range of driving tasks. The model is pre-trained on various visual and language data and fine-tuned using driving datasets, achieving state-of-the-art performance on multiple public datasets. In terms of decision-making, the single-model architecture transforms driving problems into a language question-answering or generation form, with the model directly providing safe planning or control outputs, and can even control intentions through natural language interaction. This 'all-rounder' model unifies data representation and optimization objectives, exploiting cross-task synergies. However, it requires a huge model size, high computing power, and extensive data, with currently no mature solutions for real-vehicle deployment. Other attempts, like DriveGPT4, map driving tasks to text questions and utilize large language models to generate trajectories or control commands. These single-model approaches represent the future direction for large autonomous driving models but still need breakthroughs in safety controllability and real-time performance.

Analysis of the Advantages and Disadvantages of Modular and End-to-End Solutions
4.1 System Complexity
Modular architecture involves numerous specialized modules, making system design and integration complex, requiring manual debugging and maintenance of multiple components. In contrast, a pure single-model end-to-end solution compresses the entire process into one network, reducing the number of traditional modules and resulting in a streamlined architecture. However, modular end-to-end architecture requires designing multiple differentiable sub-networks and managing data flow between them. The dual-system architecture needs to run two large models simultaneously and coordinate their outputs, adding additional sub-modules or parallel networks, making the system hierarchy slightly more complex. Overall, a pure single large model is the simplest in terms of system composition but has a huge model size. Traditional modular systems have many modules, but each is relatively simple.
4.2 Training and Optimization Difficulty
Modular solutions can be trained separately for each sub-task, using structured annotation data and easily converging through supervised learning. However, this requires collecting and annotating large amounts of data for each module. End-to-end models require even larger-scale driving data for joint training, often requiring extensive road testing and simulation data to cover various scenarios. Dual-system architecture also needs to prepare datasets suitable for vision-language models and special dialog or question-answering training. A single large model faces the highest training difficulty, as it needs to fuse multi-modal data and learn multiple tasks within a single model, making the training process complex and demanding more computing power and data than other solutions. Generally, end-to-end solutions lack explicit intermediate supervision signals during optimization, making them prone to convergence difficulties or unstable performance, requiring more exploration and parameter tuning.
4.3 Decision Transparency
A key advantage of modular systems is their strong interpretability, with each module having clear functional boundaries. Designers can view results like perception outputs, intermediate maps, and planned trajectories to locate problems. In contrast, fully end-to-end models are often 'black boxes' due to their highly integrated decision-making process. However, end-to-end paradigms do not necessarily result in complete black boxes. Systems adopting a modular end-to-end strategy can retain intermediate outputs like object detection or semantic segmentation, providing partial transparency. For example, Tesla's BEV occupancy map provides some environmental semantic information, and systems like Wayve also output heatmaps for visualization.
The vision-language models integrated into dual-system architecture primarily serve as auxiliary reasoning tools, yet these models often lack clear decision interpretability. Despite single-model architectures being the most functionally powerful, they possess minimal visible intermediate layers for review, rendering their decision-making processes challenging to oversee or comprehend. Consequently, they rely on subsequent interpretive AI technologies to analyze the network's regions of interest. In contrast, traditional modular and modular end-to-end solutions excel in transparency; whereas, the decisions of pure end-to-end or large-scale large model systems tend to be less transparent.
4.4 Flexibility
When it comes to functional expansion and algorithm iteration, modular architecture offers significant flexibility. As new scenarios emerge or new functionalities are required, a specific module can be replaced or upgraded (e.g., switching to a superior perception algorithm or optimizing planning strategies) without necessitating the retraining of the entire system.
Conversely, end-to-end solutions do not easily accommodate the insertion of external knowledge or rules, and any modifications often necessitate retraining the network. Dual-system architecture occupies a middle ground; while the end-to-end model requires retraining, the semantic module (VLM) can flexibly incorporate interpretative capabilities, such as adapting to new demands through prompt modifications or fine-tuning the language model. Single-model architecture exhibits the least scalability due to its tightly coupled internal structure, where any fine-tuning can affect the entire model's performance. Moreover, integrating external strategy adjustments (like emergency takeover logic) into end-to-end models proves more challenging. In summary, modular design excels in flexibility, whereas highly integrated end-to-end models demand greater effort to adapt to changes.
-- END --
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
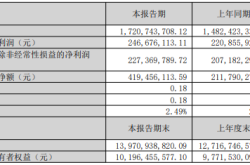
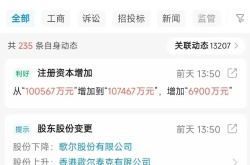
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust