Li Xiang Navigates AI into Uncharted Territories with Visionary Ideals
 05/09 2025
05/09 2025
 732
732

Key Points: VLA Driver Large Model
Author | Wang Lei
Editor | Qin Zhangyong
After a hiatus of 130 days, Li Auto's second season of AI Talk has finally resumed.
In this latest interview, Li Xiang not only shared his latest thoughts on artificial intelligence and the current state of assisted driving but also discussed prominent AI companies such as DeepMind, Tesla, and Apple.
Li Xiang believes that, despite the crossroads faced by assisted driving, it has minimal impact on Li Auto. Today's assisted driving is akin to the darkness before dawn. When the industry encounters challenges, it is precisely the moment for Li Auto to showcase its value.

As early as the first season, Li Xiang expressed his view that Li Auto is an AI company. Its mission is not to intelligentize cars but to automate AI.
In the era of artificial intelligence, Li Auto's logic is that AI will only truly explode when it becomes a production tool.
Today, Li Auto has embodied the automation of AI in a tangible form—the VLA driver large model.
Li Xiang acknowledged that creating the VLA driver large model is akin to venturing into uncharted territories. Neither DeepMind nor OpenAI has traversed this path, nor have Google or Waymo.
01
AI Must Become a Productivity Tool
At the start of the interview, Li Xiang presented a fact: despite China's rapid AI development, his daily working hours have increased rather than decreased.
This is because most people still perceive AI as an information tool. Li Xiang believes that AI is imperfect as merely an information tool. To some extent, current AI is still increasing entropy, introducing a lot of invalid information, results, and conclusions.
The topic of AI's tool attribute is something Li Xiang has discussed in depth with many people internally over the past few months.

Li Xiang categorizes AI tools into three levels: information tools, auxiliary tools, and production tools. As an information tool, it only has reference value.
If AI is regarded as an auxiliary tool, it can enhance efficiency, such as current assisted driving functions or using voice to navigate, order food, or listen to music. It makes us more efficient, but we can still do without it.
When AI can genuinely alter the outcomes of our work and reduce working hours, it becomes a production tool, marking the birth of an Agent (intelligent agent). In Li Xiang's view, that will be the true moment of AI's explosion.

"The key to determining whether an Agent (intelligent agent) is truly intelligent lies in whether it becomes a production tool. Just like humans hire drivers, AI technology will eventually assume similar responsibilities and become a genuine production tool."
To embrace this moment, Li Auto introduced the "VLA driver large model," also known as a driver Agent. In Li Xiang's view, the VLA driver large model is a professional production tool in the transportation sector.
In fact, a month ago, Li Auto unveiled its next-generation autonomous driving architecture, VLA. VLA is a vision-language-action large model that integrates spatial intelligence, language intelligence, and behavioral intelligence into one model, endowing it with powerful 3D spatial understanding, logical reasoning, and behavioral generation capabilities, enabling autonomous driving to perceive, think, and adapt to the environment.
Therefore, it is both an intelligent agent that can communicate with users and understand their intentions and an exclusive driver that can comprehend, see, and be found.
Li Xiang hopes that this intelligent agent can work and create commercial value like a human driver in the future.
During the interview, Li Auto also showcased a demo video featuring the VLA driver large model. In the video, Li Auto's "driver Agent" demonstrates intelligent capabilities akin to human drivers. It not only possesses existing advanced assisted driving capabilities but can also efficiently interact with human drivers through voice.

For instance, when passing through a highway toll booth, simply saying "take the manual lane" will prompt the system to switch from the ETC toll lane to the manual toll lane. During daily driving and parking, simple instructions like "turn around ahead," "park in Zone C," and "pull over to park" can be used to adjust the driving or parking route.
In other words, the relationship between humans and VLA is similar to that between people and designated drivers. People can converse with the driver Agent in the same way they would with a designated driver.
When asked if there were any surprising moments during the test drive of the VLA (driver large model), Li Xiang modestly responded that it was quite difficult to have any surprising moments because when treated as a human, its performance was quite normal.
Of course, when ordinary users first see the test video of VLA, they will still be amazed by its performance.
When discussing the VLA driver large model, Li Xiang specifically thanked DeepMind first. It was precisely because of DeepMind's open-source contributions that the launch of VLA was faster than originally anticipated.

According to Li Xiang, his team originally planned to develop a language model that could meet demand by the end of this year, but DeepMind's open-source instantly accelerated the process by nine months.
However, DeepMind's open-source only accelerated the L (language) part of VLA (Vision Language Action model). For the combined corpus of VL (Vision and Language), neither OpenAI nor DeepMind has such data, nor such scenarios and demands. Li Auto had to develop it themselves.
According to Li Xiang, "I can stand on the shoulders of giants, but it's only part of me."
He even bluntly stated in the interview that the reason he open-sourced his self-developed vehicle operating system Li Xiang Xinghuan OS was partly out of gratitude to DeepMind and partly because he had received so much help that he felt he should contribute something to society and reduce industry competition.
02
Three Stages of Assisted Driving
VLA is akin to a "driver large model" that can work like a human driver. However, the birth of VLA is not a mutation but an evolution, as there is "no way to directly eat the tenth steamed bun."
The entire process has undergone three stages, corresponding to the past, present, and future of Li Auto's assisted driving.

In the first stage, Li Xiang compared it to "insect-animal intelligence": a segmented assisted driving solution that combines machine learning perception with rule-based algorithms. It has established rules and also relies on high-precision maps, similar to the way ants complete tasks.
With only millions of parameters, it is naturally unable to handle more complex tasks, so it requires constantly adding defined rules, forming a structure similar to "rail transportation."
This corresponds to Li Auto's self-developed assisted driving solution relying on rule-based algorithms and high-precision maps since 2021.
The second stage corresponds to Li Auto's research since 2023 and the official launch of end-to-end + VLM (Vision Language Model) assisted driving in 2024.
Li Xiang calls this the "mammalian intelligence" stage: learning human driving behavior through end-to-end large models, similar to how some animals in circuses learn to ride bicycles from humans. They can learn various human behaviors, but their understanding of the physical world is insufficient.
Therefore, it is necessary to determine one's own speed, trajectory, and position in space through three-dimensional images. Although this is sufficient to handle most generalized scenarios, it is difficult to solve problems that have never been encountered or are particularly complex. At this point, it is necessary to cooperate with the visual language VLM model, but the existing visual language models can only play an auxiliary role in dealing with complex traffic environments.

Only on the basis of end-to-end can we reach the third stage, which is the "human intelligence" stage mentioned by Li Xiang. The answer is the VLA driver large model.
It can fully comprehend the physical world through the combination of 3D and 2D vision, unlike VLM, which can only parse 2D images. Simultaneously, VLA possesses a comprehensive brain system with language and CoT (Chain of Thought) reasoning abilities, enabling it to see, understand, and genuinely execute actions, consistent with human operation.
Li Xiang also listed corner cases (long-tail cases) that the end-to-end + VLM (Vision Language Model) architecture may not be able to solve but that VLA (Vision Language Action model) can address.
03
How to Drive Like a Human
Regarding how to train VLA, Li Xiang provided a detailed explanation. The entire process is akin to how humans learn to drive.
The first step is pre-training, whose goal is to give AI basic cognition of the world and traffic, similar to how humans first learn various traffic rules.

In this step, sufficient Language and Vision corpora and tokens are input. Vision comprises two parts: 3D Vision of the physical world and high-definition 2D Vision. Then VL (Vision and Language) joint data is added, such as navigation maps and vehicles' understanding of navigation maps, which are simultaneously placed into the training set.
This forms a VL base model, which is then "distilled" into a smaller, faster-running model of about 32B on the end side to ensure smooth operation.
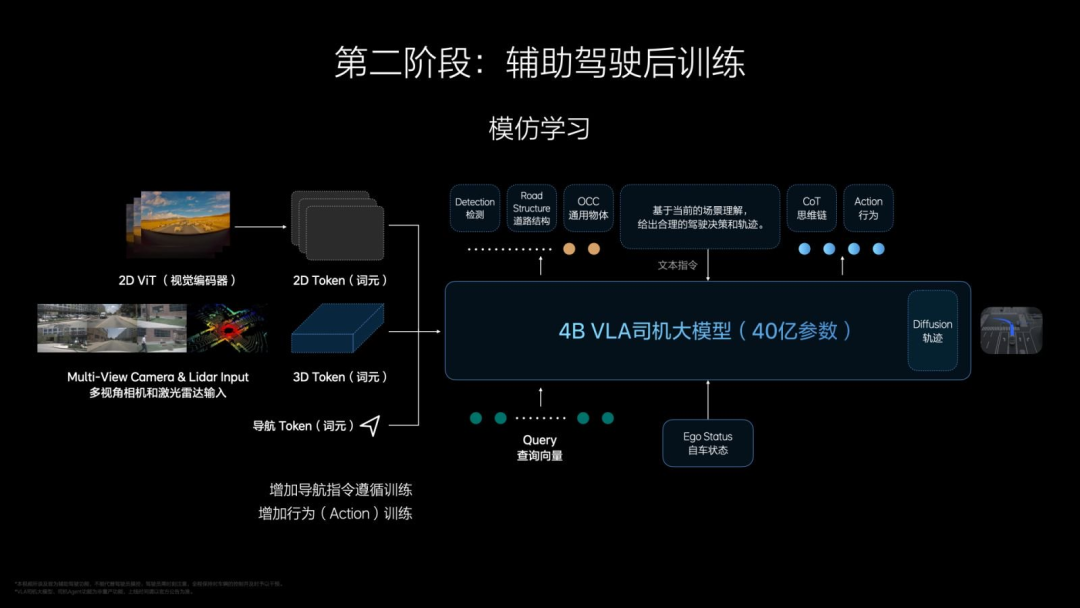
The second step is post-training, which adds Action to VL. The post-training of the Action part is similar to humans learning to drive in a driving school, enabling direct output from vision to understanding, forming a primary VLA "end-to-end" model.
Li Xiang also emphasized that they would not create long chains of thought, generally two to three steps, as otherwise, long delays would compromise safety. Additionally, after Action is completed, VLA will perform a 4-8 second diffusion model (diffusion) based on performance to predict trajectories and environments.
The third step is reinforcement learning, primarily divided into two parts. One is RLHF, reinforcement learning based on human feedback, which references a vast amount of human driver data. It receives encouragement when it performs well and feedback when it performs poorly.
Simultaneously, Li Auto has built a highly realistic virtual "traffic world," somewhat like an ultra-high-level simulator, where AI practices on its own. This part belongs to pure reinforcement learning.
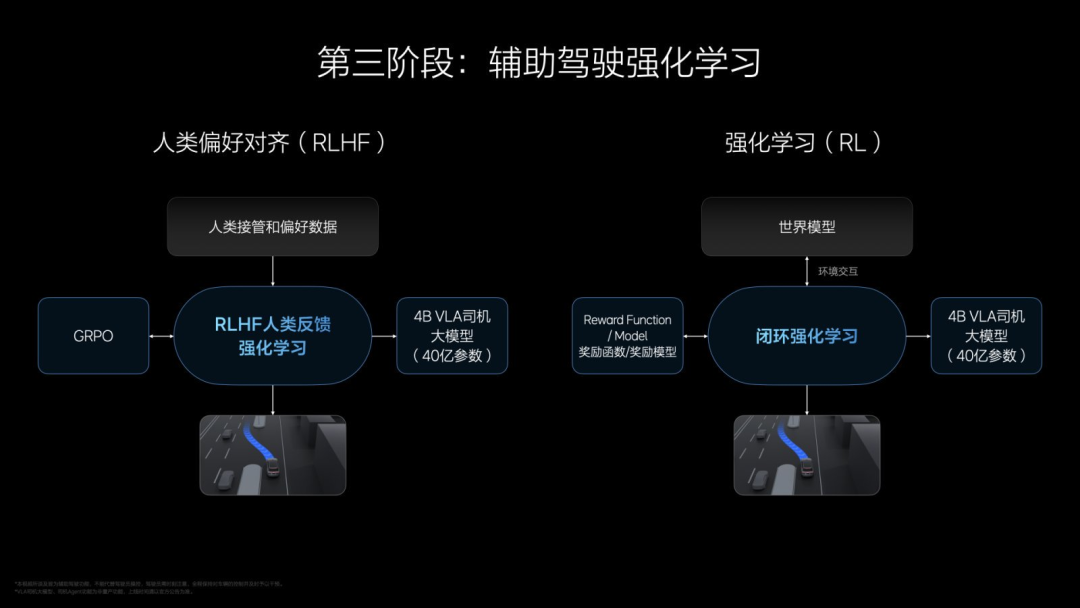
In terms of training indicators, Li Auto uses the G value to judge the comfort of assisted driving while also providing collision feedback and traffic rule feedback.
It is evident that the third step is akin to humans reinforcing their driving skills after obtaining a driver's license and driving on the road. After completing these three steps, the VLA model ready for vehicle deployment is produced.
However, this is not the end. Although the VLA driver large model is now available, it cannot yet achieve interaction between humans and VLA. At this point, Li Auto needs to build a driver Agent (intelligent agent) to teach the assisted driving system how to drive using natural language.
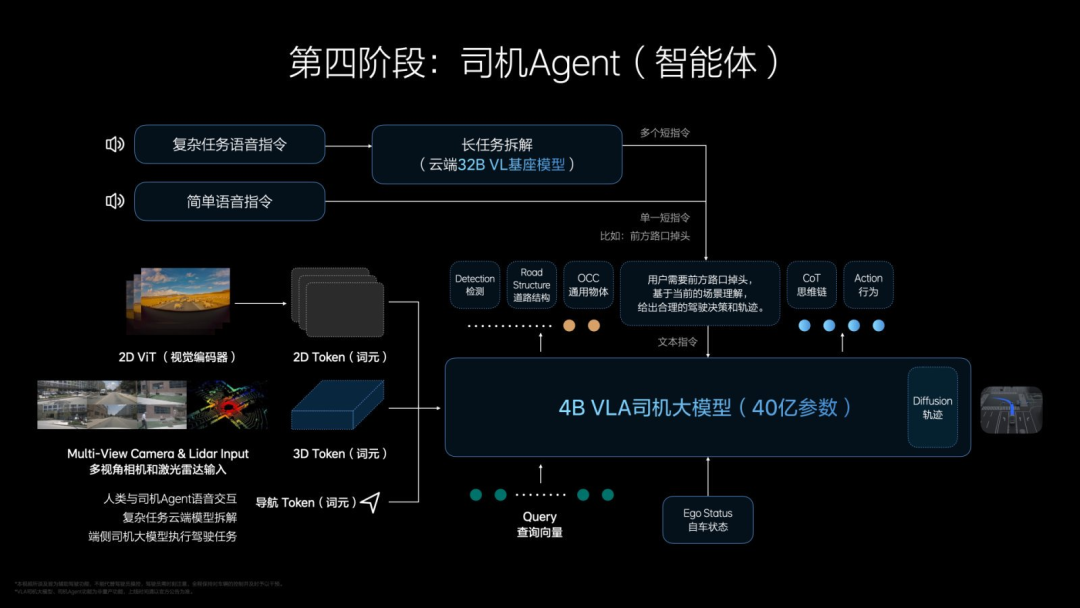
For some short instructions, the general short instruction VLA driver large model will directly handle them without going through the cloud. For complex instructions, they first need to go to the 32B base model in the cloud. After VL (Vision and Language) processing, the entire task will be handed over to the VLA driver large model for processing.
In Li Xiang's view, VLA is the most capable architecture at this stage, and its abilities are the closest to humans, with the potential to surpass them. However, it's not necessarily the ultimate architecture.
"Whether it is the most efficient way, or whether there will be a more efficient architecture, these are still questionable. I think there is a high probability that there will be a next-generation architecture."
Just as he said, no one has traversed this path before, and Li Auto is indeed venturing into uncharted territories.
"Li Auto used to walk in the uncharted territories of automobiles, and in the future, it will walk in the uncharted territories of artificial intelligence."
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust