Exploring MoA (Mixture-of-Agents): Unleashing the Potential of LLMs and Revolutionizing Language Model Collaboration
 05/13 2025
05/13 2025
 728
728
The full text spans approximately 3500 words, offering an estimated reading time of roughly 9 minutes.
In recent years, large language models (LLMs) have ignited a revolution in natural language processing, delivering astonishing performance across tasks ranging from dialogue generation to complex reasoning. However, the performance of a single model is often constrained by high training costs and resource demands. How can we transcend these limitations?
Today, let's delve into an innovative approach known as Mixture-of-Agents (MoA), proposed by the Together AI team nearly a year ago. Through multi-model collaboration, MoA significantly enhances language generation quality. This research has not only garnered academic attention but also surpassed GPT-4 Omni in benchmarks like AlpacaEval 2.0, achieving state-of-the-art (SOTA) results and demonstrating the remarkable potential of open-source models. This article will provide an in-depth exploration of MoA's innovations, experimental design, and impressive outcomes, unveiling the mysteries of this collaborative revolution.

MoA: The Power of Collaboration Reshapes Language Models
The core concept of MoA stems from an intriguing discovery: language models are inherently "collaborative." Specifically, when a model can reference the outputs of other models, even if those outputs are of lower quality, it can generate higher-quality responses. This phenomenon inspired the Together AI team to design a hierarchical architecture that enables multiple language models to collaborate as a team, jointly optimizing the final output.
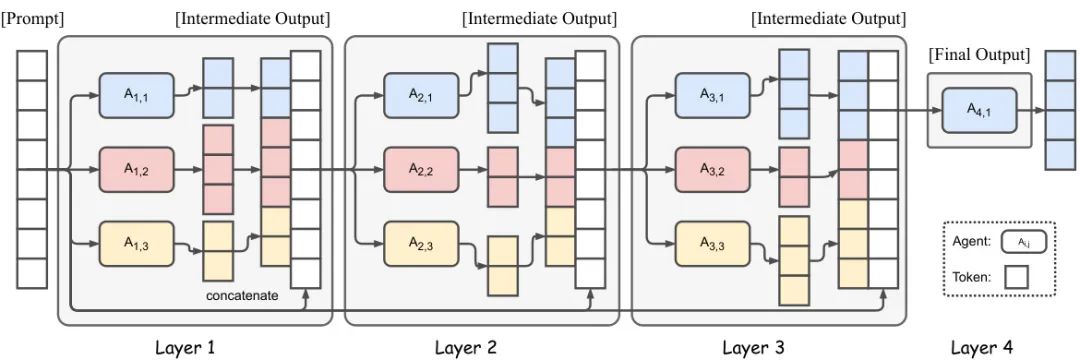
Figure 1: Schematic diagram of MoA structure. The figure depicts a 4-layer MoA architecture, with each layer containing 3 agents (models). Agents in each layer optimize based on all outputs from the previous layer, ultimately producing high-quality responses.
MoA's working method can be likened to a relay race. Each "runner" (i.e., language model) generates a preliminary response on its own "track" (MoA layer), which is then passed to the next layer of models for optimization and integration. Models in each layer refer to the outputs of all models from the previous layer, gradually refining a more accurate and comprehensive response. This layered collaboration not only leverages the unique strengths of each model but also compensates for the limitations of a single model through diverse perspectives.
Unlike traditional single models or simple integration methods, MoA does not require model fine-tuning and can achieve collaboration solely through prompting interfaces. This allows it to seamlessly adapt to any latest language model, regardless of its size or architecture. This flexibility and efficiency endow MoA with immense potential in practical applications.

Figure 2: Prompts used to integrate responses from all models in the previous layer. Translation: You have been provided with a set of answers from various open-source models in response to the latest user query. Your task is to synthesize these answers into a single, high-quality output. It is crucial to critically evaluate the information provided in these answers, recognizing that some may be biased or incorrect. Your response should not simply repeat the given answers but should provide a refined, accurate, and comprehensive response. Ensure that your response is well-structured, coherent, and adheres to the highest standards of accuracy and reliability. Here are the answers from different models: ...
MoA's innovation extends beyond its architectural design, encompassing a profound understanding of model role division. The research team divides models into two roles: Proposers and Aggregators. Proposers excel at generating diverse preliminary answers, providing rich material for subsequent optimization; Aggregators, on the other hand, are responsible for synthesizing these answers to produce the final high-quality output. By meticulously selecting models based on their performance and diversity, MoA ensures efficient and stable collaboration.
Furthermore, MoA's design draws inspiration from the Mixture-of-Experts (MoE) technique in machine learning but extends this concept to the model level. Traditional MoE achieves task optimization through subnetwork specialization, whereas MoA leverages the prompting capabilities of complete language models to achieve collaboration without modifying internal weights. This not only reduces computational costs but also opens up unlimited possibilities for future model integration.
Experimental Design
To validate MoA's performance, the research team designed a series of scientifically rigorous experiments across various benchmarks and model configurations. The following introduces the role division of LLMs, experimental scenarios and datasets, evaluation methods, etc.
LLM Role Division
In MoA's experiments, the research team carefully selected 6 open-source models to construct a 3-layer MoA, including Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, WizardLM-8x22B, LLaMA-3-70B-Instruct, Mixtral-8x22B-v0.1, and dbrx-instruct—each MoA layer uses the same set of models.
These models exhibit distinct strengths in different tasks, such as instruction following and code generation. The experiment optimized the MoA architecture configuration by analyzing model performance in proposer and aggregator roles.
For instance, Qwen1.5-110B-Chat excels in aggregation tasks, effectively integrating multiple inputs to produce high-quality outputs; while WizardLM-8x22B performs exceptionally well in the proposer role, providing diverse reference answers. By comprehensively considering model performance and diversity, the team ensures maximum synergistic effect among models within the MoA layer.
Experimental Scenarios and Datasets
The experiments are primarily based on three authoritative benchmarks: AlpacaEval 2.0, MT-Bench, and FLASK[1]. These datasets cover a wide range of task scenarios, enabling a comprehensive assessment of the model's language generation capabilities.
AlpacaEval 2.0: Contains 805 real user instructions, representing practical application scenarios. Evaluation employs the length-controlled (LC) win rate metric, comparing model responses with GPT-4 (gpt-4-1106-preview) outputs to ensure fairness. MT-Bench: Scores model responses using GPT-4, evaluating performance in multi-turn dialogues, emphasizing contextual understanding and continuous dialogue ability. FLASK: Provides 12 skill-specific scores covering dimensions such as robustness, correctness, logical reasoning efficiency, and factuality, offering a fine-grained analysis of model performance.
Additionally, the team tested MoA's reasoning ability on the MATH dataset, verifying its performance in mathematical reasoning tasks. These diverse test scenarios ensure the comprehensiveness and reliability of MoA's performance evaluation.
Evaluation Methods
MoA's evaluation method combines automatic evaluation and comparative analysis. The core metrics include:
LC Win Rate: In AlpacaEval 2.0, compares model responses with GPT-4 to calculate the probability that the model outperforms the benchmark model, eliminating length bias. MT-Bench Score: A score of 0-10 given by GPT-4, evaluating the overall quality of the response. FLASK Skill Score: Provides fine-grained scores for 12 skills, analyzing model performance across different dimensions. Math Task Accuracy: Evaluates the model's reasoning accuracy on the MATH dataset.
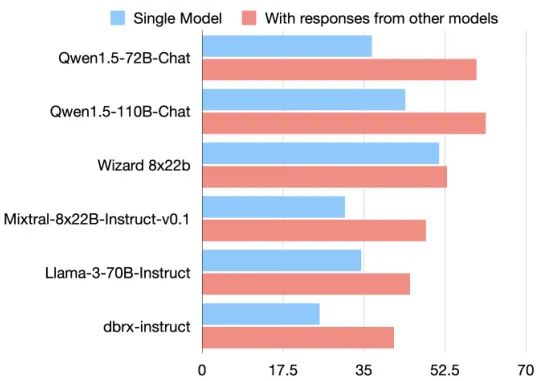
Figure 3: Improvement in AlpacaEval 2.0 LC Win Rate. The figure illustrates the performance enhancement of multiple models after referencing the outputs of other models, confirming the collaborative nature of language models.
To gain deeper insights into the internal mechanisms of Mixture-of-Agents (MoA), the research team conducted multiple in-depth experiments. They compared MoA's performance with LLM-Ranker, confirming MoA's superiority in comprehensive generation; through BLEU, TF-IDF, and Levenshtein similarity analysis, they revealed how aggregators intelligently integrate proposer outputs; furthermore, the team studied the impact of model diversity and the number of proposers on performance, finding that multi-model collaboration significantly enhances results; by analyzing proposer and aggregator role performance, they further clarified each model's expertise. Collectively, these experiments illuminate the core mechanism of MoA's efficient collaboration.
Experimental Results: The Feat of Surpassing GPT-4 Omni
MoA's experimental results are exhilarating, particularly on AlpacaEval 2.0, where MoA demonstrates overwhelming advantages. The following provides a detailed analysis of the key results.
AlpacaEval 2.0: The Comeback of Open-Source Models
In the AlpacaEval 2.0 benchmark, MoA achieved an LC win rate of 65.1%, surpassing GPT-4 Omni's 57.5%, representing an absolute improvement of 7.6%. Remarkably, this achievement was solely attained by open-source models, fully showcasing MoA's potential in integrating open-source model capabilities.
The team also tested two variants: MoA w/ GPT-4o and MoA-Lite. MoA w/ GPT-4o uses GPT-4o as the final aggregator, achieving an LC win rate of 65.7%, further enhancing performance. MoA-Lite, on the other hand, reduces the number of layers (2 layers) and employs a lighter Qwen1.5-72B-Chat as the aggregator, achieving an LC win rate of 59.3%, still superior to GPT-4 Omni at a lower cost.
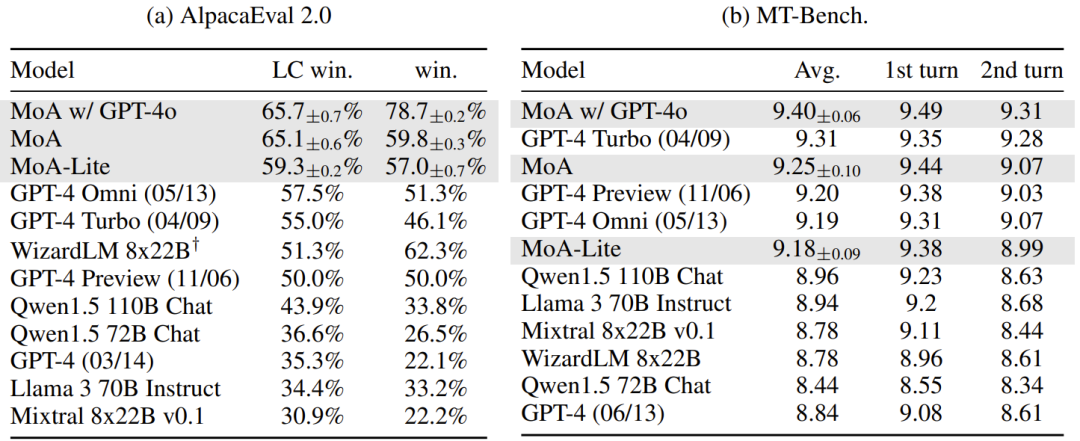
Figure 4: Results of AlpacaEval 2.0 and MT-Bench (the latter's full score is 10). For AlpacaEval 2.0, MoA and MoA-lite correspond to 6 proposers in 3 and 2 layers, respectively. MoA w/ gpt-40 corresponds to using gpt-40 as the final aggregator in MoA. The study conducted three experiments, reporting the average score and standard deviation. † Indicates the replication of AlpacaEval results by this study. The researchers of this study ran all MT-Bench scores themselves, obtaining turn-based scores. MT-Bench: A Small but Steady Lead
On MT-Bench, MoA's performance was equally impressive, with an average score of 9.25, slightly higher than GPT-4 Omni's 9.19 (out of 10). While the improvement margin is small, this is primarily because MT-Bench scores are near saturation (top models generally score above 9). Nevertheless, MoA remains at the top, demonstrating its stability in high-difficulty dialogue tasks.
FLASK: Excellent Performance Across Multiple Dimensions
FLASK's fine-grained evaluation reveals that MoA significantly outperforms the single model Qwen1.5-110B-Chat in dimensions such as robustness, correctness, logical reasoning efficiency, factuality, commonsense reasoning, insight, and completeness. Furthermore, MoA even surpasses GPT-4 Omni in metrics like correctness, factuality, insight, completeness, and metacognition. The only drawback is that the conciseness of its outputs is slightly inferior, possibly due to the slight verbosity of responses from multi-model collaboration.
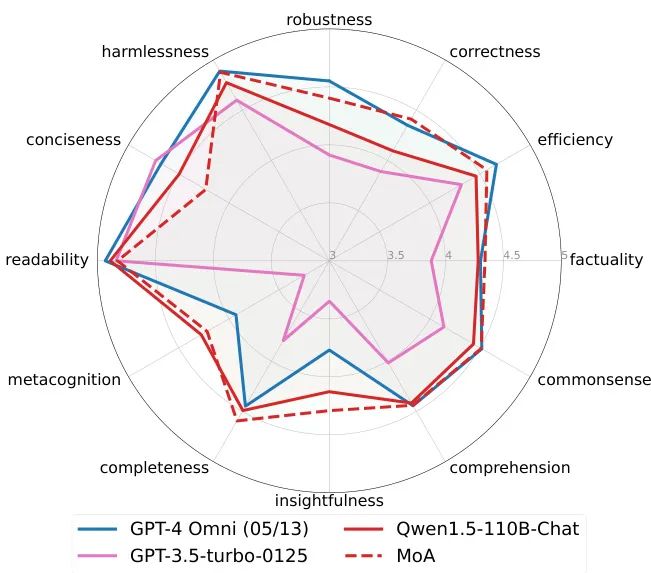
Figure 5: FLASK evaluation results. MoA performs exceptionally well across multiple skill dimensions, especially surpassing GPT-4 Omni in correctness, factuality, and insight. MATH Task: A Leap in Reasoning Ability
On the MATH dataset, MoA's performance is equally impressive. Using Qwen1.5-110B-Chat as the aggregator, MoA's accuracy in the three-layer architecture improved from 50.0% in the first layer to 57.6% in the third layer, demonstrating the significant effect of layered collaboration in reasoning tasks. This result indicates that MoA is not only applicable to language generation but also effectively enhances complex reasoning abilities.
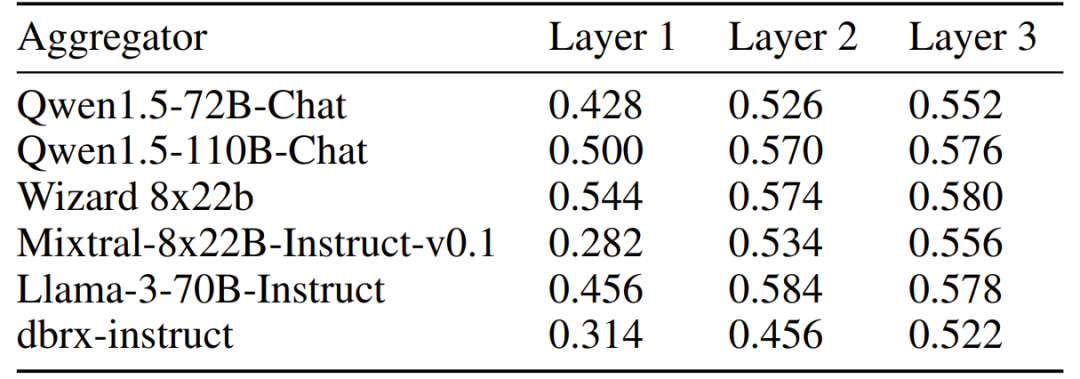
Figure 6: Results of the MATH task. Researchers evaluated different aggregators, with all six models acting as proposers in each MoA layer. Cost vs. Efficiency: Breaking the Pareto Frontier
Another highlight of MoA lies in its cost-effectiveness. By analyzing budget and compute power (TFLOPs), experiments plotted the Pareto frontier of performance vs. cost. The results show that MoA and MoA-Lite lie on the Pareto frontier, indicating they have lower costs at the same performance level. For instance, MoA-Lite has a cost comparable to GPT-4 Omni but achieves a 1.8% performance improvement; while MoA remains competitive at higher performance levels, with over 50% lower costs than GPT-4 Turbo.
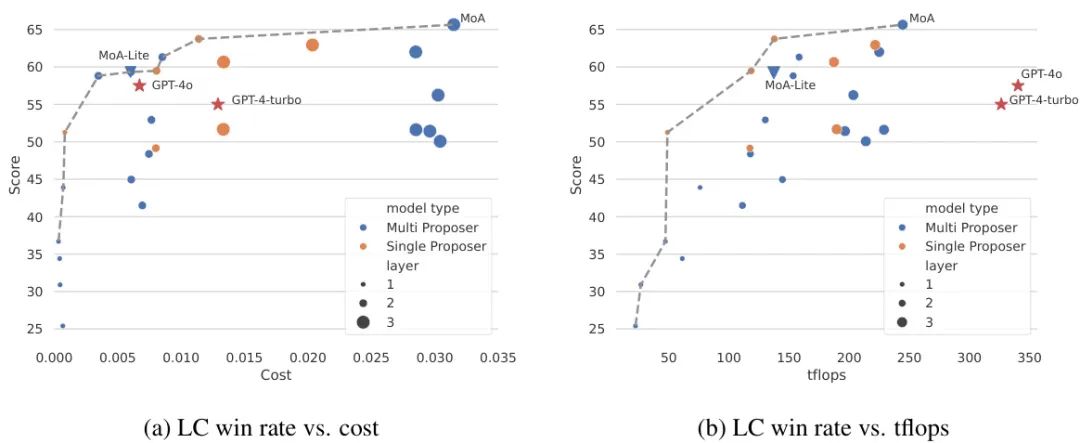
Figure 7: Trade-off between performance and cost. MoA and MoA-Lite lie on the Pareto frontier, demonstrating a perfect balance of high performance and low cost.
Why is MoA so powerful?
MoA's success stems from its profound understanding of collaboration mechanisms. Experiments show that MoA's aggregator does not simply select the best proposer's output but integrates the strengths of multiple inputs through a complex synthesis process. For example, BLEU similarity analysis reveals a high correlation between the aggregator's output and that of high-quality proposers, indicating that MoA can intelligently "borrow" the best content.
Moreover, model diversity and quantity are crucial to MoA's performance. Experiments found that using multiple different models (multi-proposer setting) significantly outperforms generating multiple outputs from a single model (single-proposer setting). For instance, in a configuration with 6 proposers, the LC win rate for the multi-proposer setting reached 61.3%, much higher than 56.7% for the single-proposer setting.
Future Prospects and Limitations
The advent of MoA (Mixture-of-Agents) introduces novel dimensions to language model collaboration. It not only elevates the quality of content generation but also showcases the potential for achieving high performance at low costs through the utilization of open-source models. Nonetheless, MoA's hierarchical design may introduce higher initial token processing times (TTFT), which could detract from user experience in real-time applications. To address this, future research could delve into techniques like chunk-wise aggregation to enhance response speed.
Moreover, MoA's interpretability stands out as a substantial benefit. By presenting intermediate outputs in natural language, users can gain a clearer understanding of the model's reasoning process. This serves as a cornerstone for developing more transparent AI systems that are better aligned with human requirements.
Conclusion: The Dawn of Collaborative Intelligence
The emergence of Mixture-of-Agents technology heralds a new epoch in language model collaboration, transitioning from solitary efforts to collaborative teamwork. Through its ingenious hierarchical structure and role distribution, MoA amalgamates the insights of multiple models, achieving remarkable performance that surpasses that of individual models. Whether it's topping the charts in AlpacaEval 2.0 or achieving breakthroughs in cost-effectiveness, MoA exemplifies the strength of collaboration. Looking ahead, with the integration of additional models and refined architectures, MoA is poised to further unleash the potential of language models, paving the way for myriad possibilities in AI applications.
Eager to delve deeper into the intricacies of MoA? Dive into the original paper: Mixture-of-Agents Enhances Large Language Model Capabilities. Let's anticipate with excitement the next phase of this collaborative revolution!
References
[1] FLASK: FINE-GRAINED LANGUAGE MODEL EVALUATION BASED ON ALIGNMENT SKILL SETS: https://arxiv.org/abs/2307.10928
[2] Mixture-of-Agents Enhances Large Language Model Capabilities: https://arxiv.org/abs/2406.04692
-- End --
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust