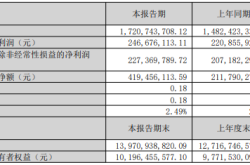
Tsinghua and Xingdongjiyuan Unveil Groundbreaking Initiative: Open-Sourcing the First AIGC Robot Large Model
 05/13 2025
05/13 2025
 762
762
On May 7, Xingdongjiyuan announced a partnership with the ISRLab at Tsinghua University's Institute for Artificial Intelligence to open-source the groundbreaking AIGC generative robot large model, VPP (Video Prediction Policy).
VPP leverages an extensive corpus of internet video data for training, directly learning human movements, minimizing the need for high-quality real robot data, and seamlessly adapting to different humanoid robot bodies. This advancement is anticipated to significantly expedite the commercialization of humanoid robots.
At this year's ICML 2025, VPP distinguished itself from over 12,000 submissions, being selected as a Spotlight paper, representing less than 2.6% of the total.
Currently, the field of AI large models is dominated by two main "giants": autoregressive understanding models, epitomized by GPT, and diffusion-based generative models, such as Sora.
GPT's approach, evolved into embodied intelligence, is exemplified by VLA technology, represented by PI (Physical Intelligence). Derived from fine-tuning visual-language understanding models (VLM), it excels in abstract reasoning and semantic understanding.
The convergence of generative technology and robotics has given rise to large generative robot models like VPP.
VPP's two-stage learning framework ultimately enables video action generation based on text instructions. The first stage employs a video diffusion model to learn predictive visual representations, while the second stage involves action learning through Video Former and DiT diffusion strategies.
Unlike previous robot strategies (e.g., VLA models) that rely solely on current observations for action learning, requiring robots to first comprehend instructions and scenarios, VPP can anticipate future scenarios, enabling robots to "act with foresight," vastly enhancing generalization capabilities. Furthermore, VPP's video prediction results closely mirror the robot's actual physical execution outcomes, meaning what can be visualized in a video can also be executed by a robot.
Previously, training robot strategies (e.g., VLA models) necessitated repeatedly filming numerous videos of robots performing tasks, which was costly and time-consuming. In contrast, VPP, akin to a "super scholar," can learn these actions by directly observing massive amounts of human activity videos online, such as sweeping and cooking. It can also "mentally rehearse" upcoming scenarios, adjusting actions in advance, for instance, knowing to stabilize a cup before lifting it to prevent spills.
High-Frequency Prediction and Execution with Ultra-Fast Response Times
Previously, AIGC-generated visuals were slow, often requiring extensive inference time, akin to waiting a long time for a video to load on a computer.
The Xingdongjiyuan research team discovered that it is unnecessary to precisely predict every pixel in the future. By effectively extracting representations from the intermediate layers of the video model, single-step denoising predictions can encapsulate a wealth of future information.
VPP realizes that precise prediction of every frame detail is unnecessary; capturing key information suffices. As a result, it predicts the next action in less than 0.15 seconds, controlling robots at a frequency several times faster than conventional models, executing tasks smoothly and efficiently.
Cross-Body Learning with Convenient Skill "Sharing"
Different robots have varying "bodies" and "arms," making it cumbersome to teach them skills in the past.
VPP directly uses videos of robots performing tasks as teaching materials and can even learn from videos of humans at work. It's akin to learning to cook by watching someone else do it once, then being able to replicate it yourself.
In tests, it completed tasks 41.5% more efficiently than older methods, scoring nearly full marks in simulation tests and achieving a 67% success rate in real robot tests.
Able to Draw Inferences About Other Cases from One Instance, Demonstrating "Versatility" in the Real World
In real-world tests, the VPP model exhibited remarkable multi-task learning and generalization capabilities, yielding impressive results.
On Xingdongjiyuan's single-arm + humanoid five-finger dexterous hand XHAND platform, VPP can perform over 100 delicate operations using a single network, such as folding clothes and screwing bottle caps. On dual-arm robots, it can also proficiently handle over 50 complex tasks, like making dumplings and setting tableware.
Interpretability and Debugging Optimization for Instant Problem Identification
VPP's predictive visual representations are to some extent interpretable, allowing developers to identify failure scenarios and tasks in advance through predicted videos without conducting real-world tests. This enables targeted debugging and optimization.
If a robot makes a mistake while working, VPP can identify the issue in advance through the predicted video, akin to spotting flaws in a rehearsal video. In contrast, previous models required robots to repeatedly perform tasks to identify issues, making VPP a significant time-saver for debugging.
With VPP now fully open-sourced, the "martial arts secrets" have been freely shared. Relying on the strong momentum of the industry's continuous open-sourcing of high-quality models and technologies, robot technology is poised to embark on a new chapter, with embodied AGI striding forward along this innovative path.
-
![]()
Market Share Dilemma: DJI vs. Insta360—Is It '40-40' or '60-30'?
-
![]()
Market Share Dilemma: DJI vs. Insta360 – A '40-40 Split' or '60-30 Split'?
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust