Trillion-Dollar Market: Nvidia's Rising Anxiety
 03/18 2026
03/18 2026
 695
695

Is There a CUDA Moat in Inference?
"By 2027, orders for Blackwell and Vera Rubin systems will generate at least $1 trillion in revenue."
Another year, another GTC. At this year's "tech Super Bowl," Huang Renxun, clad in his signature leather jacket, unveiled new "nuclear bombs" and delivered an unprecedented explosive revenue forecast. This staggering figure reflects Huang's consistent optimism and confidence in the sustained growth of AI-era infrastructure, signaling to the market that Nvidia's growth story is far from over.
However, the capital market's reaction was lukewarm. Nvidia's stock price initially surged by 4.3% but then fell, ultimately closing up 1.2%. The unprecedented revenue forecast failed to ignite market enthusiasm.
The crux lies in the evolving rules of the game in the booming inference computing power market. Low latency, high energy efficiency, and application costs are replacing high performance, high throughput, large memory, and high bandwidth as the core factors dominating the computing power market.
Amid this structural upheaval, Nvidia—the undisputed king of AI computing power for the past three years—is facing unprecedented centrifugal forces. Beyond traditional chipmakers, Nvidia's traditional major clients, such as Amazon, Meta, and even OpenAI, are accelerating their in-house chip development. Meanwhile, China, a major player in inference demand, currently offers highly competitive inference costs for domestically produced computing power.
To address unprecedented inference-related anxieties, Nvidia unveiled a series of new products at this year's GTC conference to meet inference demands and reshaped its competitive moat with an AI factory narrative. However, the outside world is still observing and waiting to see the effects of these moves.
It is evident that this protectionist battle centered on moats and barriers has only just begun.
01
The "Centrifugal" Anxiety of the Inference Era
Nvidia is facing a massive "centrifugal movement." Multiple players vying for the inference market are creating a strong outward pull, challenging the giant's dominance in the training market.
The root cause lies in the seismic shifts occurring in the AI industry, where the inference market is surpassing the training market to become the primary battleground for AI computing power.
As Huang himself asserted in his GTC keynote this year, "The inference inflection point has arrived." This represents a vast, emerging market. IDC predicts that by 2027, China's inference computing power will account for over 70% of total computing power. Globally, the use of intelligent agents will grow tenfold, and inference demand will surge 1,000-fold. Deloitte also noted in a report that by 2026, inference workloads will account for two-thirds of all AI computing power, a rapid rise from one-third in 2023 to half in 2025.
However, in this high-potential, rapidly expanding market, the computing power requirements for inference tasks fundamentally differ from those in the training phase.
David Patterson, the founder of the RISC architecture, and Ma Xiaoyu, a senior engineer at Google DeepMind, mentioned in a paper earlier this year that the training phase requires massive parallel computing to process vast amounts of data. For instance, a single GPT-4-level training run demands 25,000 A100 GPUs operating continuously for 90 days, representing an "arms race" of peak computing power and capital.
In contrast, the logic of the inference phase is entirely different. It is essentially a sequential autoregressive process, generating one token at a time. Model parameters must be frequently loaded from GPU memory to the computing unit, making available memory bandwidth the decisive factor for token generation speed. This makes memory bandwidth and end-to-end latency the core bottlenecks.
Additionally, in terms of cost structure, the training era follows a "one-time outbreak " (one-time explosion) model, while inference involves continuous bleeding. Under billions of daily requests, AI application vendors place significant emphasis on cost control, as "token output per watt per dollar" directly impacts the viability of AI applications.
To address issues related to memory bandwidth, end-to-end latency, and cost-efficiency, there is a consensus in the industry that custom chips, optimized for specific tasks, outperform general-purpose GPUs.
Currently, multiple forces are entering the inference computing power market.
Traditional chipmakers like AMD and Intel are not sitting idle. They have long recognized the structural growth opportunities in the inference market. AMD, with its MI350 series (including MI355X), has formed a cost advantage in total ownership. Authoritative supply chain statistics show that Meta purchased 173,000 MI300 series chips in 2025 (with a large-scale shift to MI350 planned), while Microsoft bought 96,000. Oracle has also committed to deploying up to 131,000 MI355X chips. Meanwhile, Intel's Gaudi 3 accelerator is rapidly gaining traction in enterprise-level and cloud-based inference markets.
Leading cloud providers, previously major contributors to Nvidia's data center revenue, are now aggressively pursuing in-house chip development due to cost control and supply chain autonomy considerations. For these giants, given the scale of billions of daily inference requests, developing lower-cost custom chips can save billions of dollars annually while providing critical supply chain flexibility.
Currently, from Google to Amazon, all have collaborated deeply with Broadcom to design and mass-produce inference chips. Google's TPU, after multiple iterations, has secured orders from Anthropic (deploying over 1 million units) and Meta (signing a multi-year, billion-dollar leasing agreement in February 2026). Amazon's Trainium has received orders for 2GW capacity from OpenAI, and Anthropic has also extended an olive branch to Amazon. Meta's in-house MTIA series (including MTIA 300 and subsequent versions) has deployed hundreds of thousands of chips, fully supporting inference across its entire platform recommendation system.
Simultaneously, some specialized inference chip companies are also accelerating their efforts in this market. For example, Groq, acquired and integrated by Nvidia by the end of 2025, attracted significant attention from developers and enterprises in 2025 due to its LPU's far lower first-token latency than GPUs and its more competitive pricing.
Beyond these competitors, China, as a major client in the inference market, is also witnessing the rise of a domestic inference computing power ecosystem. The industry observes that the landscape has evolved from Huawei being the sole player to a flourishing market where companies like Biren offer highly cost-effective inference-specific chips, while Moore Threads and other vendors are highly recommended within the AI agent enterprise circle.
Surrounded by multiple adversaries, market research firms believe that the AI server market will shift from Nvidia's dominance to "diversified competition." XPU (dedicated accelerators that are neither GPU nor CPU) growth rates will surpass those of GPUs. Byteiota, a tech analysis firm, even points out that by 2028, Nvidia's inference market share will plummet from 80%, with ASICs capturing 70–75% of production inference workloads.
"There is no CUDA moat in inference," the Wall Street Journal recently reported, citing Andrew Feldman, CEO of emerging chipmaker Cerebras Systems. To some extent, this may represent Nvidia's greatest source of anxiety today.
02
Targeting the Trillion-Dollar Market: Nvidia's Moat Defense
Nevertheless, Nvidia has taken a series of actions and initiatives to address the challenges of the inference era. At the GTC conference, both Huang's keynote and the array of new products and moves showcased Nvidia's ambitions for the inference era.
During his over two-hour speech, someone counted that "training" was mentioned only a dozen times, while "inference" appeared nearly 40 times.
He also used the $1 trillion revenue forecast to demonstrate to the outside world that Nvidia will maintain its presence in the inference era—
"At this time last year, I mentioned that by 2026, the demand scale for Blackwell and Rubin could reach $500 billion. Today, I want to tell you: standing here, by 2027, the high-certainty demand we see is already at the trillion-dollar level. And I believe the actual demand will be even higher."
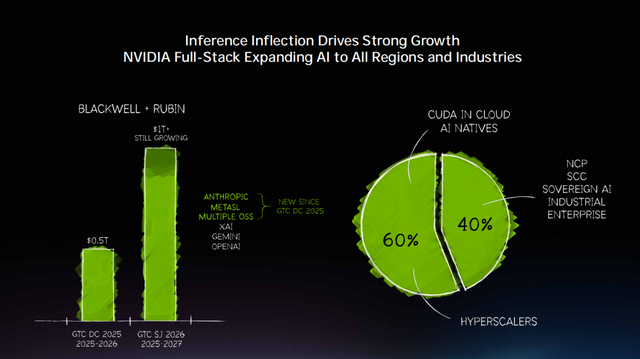
Behind this, Huang mentioned that starting in 2025, Nvidia has been fully committed to inference capabilities, ensuring that Nvidia excels not only in training but also in post-training, inference, and the entire AI lifecycle.
At the conference, Nvidia showcased its comprehensive strategic layout for addressing the challenges of the inference era. Huang Renxun dissected the inference process into two distinct stages—"prefill" and "decode"—and equipped each stage with specially optimized hardware architectures.
Some commented that this was an attempt to regain Nvidia's voice in the inference era by redefining the essence of inference computing.
The new flagship GPU, the Vera Rubin GPU, is dedicated to the "prefill" stage, offering a 3.3–5x improvement in inference performance over the previous generation, capable of converting user requests into tokens.
The inclusion of Groq 3 LPX is seen as a crucial step for Nvidia to address its low-latency inference shortcoming (weakness). In December 2025, Nvidia invested $20 billion to acquire Groq's low-latency inference technology and core team through an unconventional acquisition, marking the largest deal in its history. Groq focuses on ultra-low latency and performance determinism, with its founder, Jonathan Ross, being a key driver behind Google's TPU.
The Groq 3 LPU, the first product resulting from the collaboration, is manufactured by Samsung and expected to ship in Q3 2026. This chip is designed specifically for the decode stage, bypassing the traditional GPU's HBM memory bottleneck, achieving a first-token latency below 0.1 milliseconds, and delivering a 35x improvement in inference performance. Huang also stated that the division of labor between "GPU for prefill and LPU for decode" represents the optimal architecture for the inference era.
With the advent of the agent era, Nvidia also designed a new CPU specifically for agent workflows—the Vera CPU. Utilizing LPDDR5 low-power memory commonly used in smartphones and tablets, it shifts its positioning from a general-purpose computing processor to an agent task scheduler. Instead of blindly stacking memory bandwidth, it achieves efficient and precise data scheduling with lower power consumption. Huang claimed its performance is twice that of mainstream global CPUs, representing a multi-billion-dollar business. "We never thought we'd sell CPUs separately, but now we're selling a lot," he said.
Thus, Nvidia has also broken away from the narrative of relying solely on general-purpose GPUs, shifting toward scenario-based division of labor. Currently, the entire system forms a triangular division of labor: GPUs handle heavy computing, CPUs manage scheduling and orchestration, and LPUs are responsible for ultra-fast output. Combined with Nvidia's self-developed Dynamo scheduling software, it can flexibly meet the complex requirements of different AI tasks for cost, latency, and throughput. In high-value token generation scenarios, token throughput per megawatt increases 35x over the previous generation Blackwell.
Huang further provided deployment recommendations: high-throughput workloads can use 100% Vera Rubin; for coding and high-value engineering token generation workloads, a combination of 25% Groq and 75% Vera Rubin can be configured.

Beyond hardware and software releases, Nvidia has also constructed a new narrative—the "AI factory"—
"We're not just optimizing chips individually but engaging in extreme co-design (collaborative design): chips, systems, networks, software, algorithms, and deployment methods, all working in full-stack synergy. In the future, all cloud service providers, AI companies, and large enterprises will study their token factory efficiency just as they study manufacturing production lines today. Because data centers are no longer just 'places to store files' but factories producing tokens. Tokens are becoming the new commodity, and AI computing is becoming the new source of revenue."
Under this narrative, competition is no longer limited to the chip dimension but encompasses everything from chips to liquid-cooled racks, network interconnects, and AI factory operating systems. Nvidia occupies multiple levels, from energy and chips to infrastructure and models, allowing customers to obtain the optimal cost for the entire training + inference lifecycle in a "one-stop" manner. Huang also elaborated on the "Token factory economics," emphasizing the new metric of "token output per watt per dollar."
The outside world believes that Nvidia is using a comprehensive delivery model to leverage system advantages and offset single-dimensional cost advantages, thereby addressing competition in the inference market.
At GTC 2026, Nvidia remains the dominant player in the AI computing power market, but it is also entering the opening stages of a defensive battle. This inference defense war is also a battle for survival and dominance in the new era, and everything has only just begun.
-
![]()
AI Giants Start Borrowing to Fuel Computing Power Race
-
ByteDance Initiates Largest B2B Structural Adjustment, This Time It's Truly Different
-
![]()
Let's Talk About Kingsoft Office's Mid-Year Outlook and the True Strength of Its AI-Powered Office Solutions
-
Despite 150 Million Users, Struggles Persist: AIShige Faces Tough Competition from Seedance and Kling in AI Video Monetization
-
![]()
Ensuring Safe Gear Shifting in the Automotive Industry: Transitioning from 'Product Oversight' to 'Full-Chain Governance'
-
![]()
Net Profit Soars to $133.7 Billion! Azure Revenue Tops $100 Billion, with AI Fueling Microsoft's Growth
-
![]()
Before 6G Hits the Market, the U.S. Forges a 'Rules Alliance': What Challenges Await Chinese IoT Enterprises?
-
![]()
Intelligent Driving's 'Little Blue Light' Faces Ban: Night Glare and Cut-in Risks Prompt Official Action





