Cui Dabao: Difficulties, bottlenecks, and milestones behind the cooling of large models
 08/20 2024
08/20 2024
 741
741

Cui Dabao | Founder of Node Finance
Entering 2024, large models seem to be losing steam: in the capital market, related concepts are no longer hyped, and NVIDIA's share price has plunged, raising concerns about a "bubble bursting";
In the consumer market, BATH (Baidu, Alibaba, Tencent, and Huawei) have fewer new product launches, the pace of product updates has slowed, and public interest has waned...
The only excitement left seems to be two intense battles: Since ByteDance announced a "per-thousand impression" pricing model on May 15th, sparking the first salvo in the "price war" for domestic large models, followed by Baidu Wenxin, iFLYTEK Spark, Alibaba Tongyi, and Tencent Yuobao;
Meanwhile, in densely populated areas like subways, office buildings, and airports, slogans from Baidu Wenxin, iFLYTEK Spark, Alibaba Tongyi, Tencent Yuobao, and Huawei Pangu compete for attention, with face-to-face marketing reminiscent of a battlefield.
The fusion of "seawater" and "flames" prompts reflection on where the future lies for large models, and what the difficulties, bottlenecks, and milestones are.
01 Difficulty: Difficult to monetize and implement
Even giants like OpenAI face monetization challenges.
According to foreign media reports, OpenAI estimates a loss of $5 billion, with annual operating costs of up to $8.5 billion, suggesting a high likelihood of exhausting its cash flow within a year.
In a long article titled "How does OpenAI Survive," the author questions OpenAI's business model:
"OpenAI's revenue ranges from $3.5 billion to $4.5 billion, but its operating losses could reach $5 billion, far exceeding its revenue. To launch the next-generation GPT5, OpenAI requires more data and computing power, adding significant costs."
Despite significant investments, large models have yet to find a viable monetization path.
According to Node Finance observations, most large models on the market adopt a To C+To B strategy, combining membership subscriptions with developer API calls.
However, few can generate immediate revenue from either model, and after deducting costs, most are unprofitable.
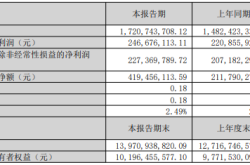
Taking Baidu, a pioneer in domestic large models, as an example, in Q1 2024, its cloud business revenue was 4.7 billion yuan, a year-on-year increase of 12%, with 6.9% (about 324 million yuan) coming from external customers using large models and generative AI services.
In Q4 2023, large models contributed an additional 660 million yuan to Baidu Cloud's revenue.
As the only domestic company to disclose large model revenue, Baidu's size and resources give it a competitive edge. However, focusing solely on revenue growth without profitability is flawed.
It's easy to imagine the confusion and struggle faced by competitors who dare not disclose their accounts.
The underlying reason for the difficulty in monetization is the challenge of implementing large models.
Despite proclamations of large models as the "iPhone moment" and the fourth industrial revolution, they still have limitations, including cognitive biases, lack of initiative, weak generalization capabilities, and hallucinations.
For example, numerical computation is a weakness of large models, making them more suited to liberal arts than math problems solvable by second or third-grade students.
Node Finance tested Kimi by asking, "Which is greater, 9.11 or 9.8?" After a lengthy response, Kimi provided an incorrect answer.
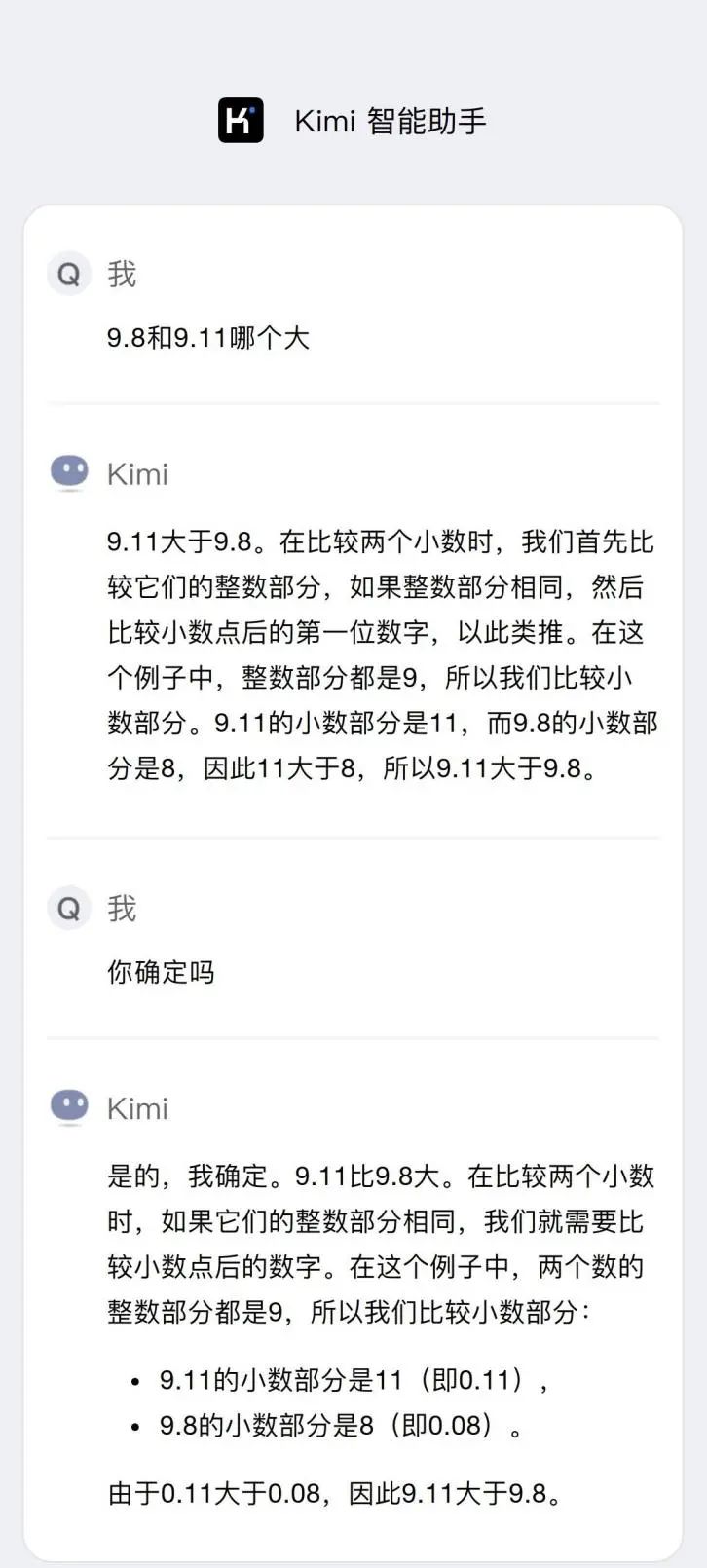
Image source: Kimi official website
Another example is the outdated information in large models, which can only be partially mitigated by external knowledge bases, leaving room for inaccuracies.
Recently, SearchGPT generated much buzz, but when asked about details of the Boone Bluegrass Festival in North Carolina in August, SearchGPT provided five answers, three of which contained factual errors.
Large models also suffer from short-term memory loss, requiring users to repeat themselves in multi-turn conversations.
In B2B settings, large models face even greater challenges due to limited industry experience, unfamiliarity with specific know-how, and complex environments. One industry insider notes that no mature industry case studies exist for large models to date.
02 Bottlenecks: Data, computing power, and costs
Deeply analyzing the implementation challenges of large models reveals three critical bottlenecks: data, computing power, and costs.
Bottleneck: Data
If large models are compared to Giant beast , their significant characteristic is their insatiable appetite for high-quality, extensive corpus data, requiring continuous and frequent feeding.
The quality, quantity, freshness, and diversity of data determine the iteration progress and learning outcomes of large models, posing significant challenges for data mining, acquisition, and handling sensitive information.
Recently, the free online novel app Tomato Novel caused an uproar with its "AI Agreement," which allowed the platform to use signed works to train AI models for various applications, drawing widespread opposition from authors.
Bottleneck: Computing Power
If the AI chain is a factory, computing power is the expensive "fuel" (coal, oil, electricity, etc.) that keeps it running.
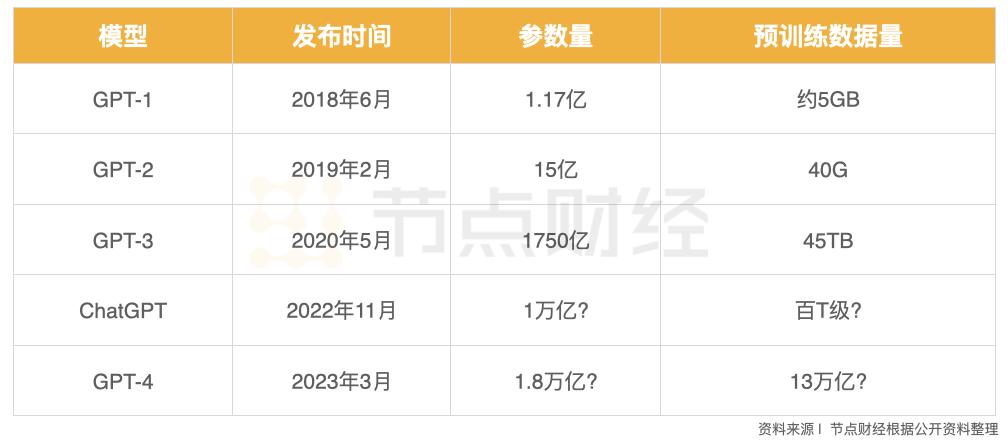
Initial ChatGPT required 10,000 NVIDIA A100 AI chips, costing over 700 million yuan. Subsequent optimizations consumed approximately 3,640 PFLOPS of computing power daily, equivalent to the support of 7-8 data centers with 500 PFLOPS of computing power, totaling billions in infrastructure costs.
According to GF Securities estimates, domestic AI large models require computing power equivalent to 11,000 to 38,000 high-end AI servers during training, inference, and prediction, corresponding to investments of 12.6 billion to 43.4 billion yuan.
As large models scale up, computing power demands will multiply, exceeding Moore's Law. ChatGPT's parameters have surged from 117 million in version 1.0 to 175 billion in version 3.0.
Currently, China faces external constraints and internal deficiencies in computing power, hindering the effectiveness of large models compared to international counterparts.
"Large models have only two tiers: OpenAI and Others. It doesn't matter which domestic provider you choose," say multiple AI practitioners.
Bottleneck: Costs
Large models' dependence on computing power is also a cost issue.
Cost reduction is crucial for technology adoption, as seen in the popularity of affordable computers, smartphones, and electric vehicles.
Similarly, for large models to succeed, costs must be effectively controlled. When only one supplier (like NVIDIA) profits significantly, sustainability becomes questionable.
Fortunately, in late February, Robin Li revealed that Baidu has continuously reduced the inference costs of its Wenxin large model to 1% of last March's version.
03 Milestone: Embedding large models in industries
Undoubtedly, large models have shortcomings, but new technologies thrive in uncharted territories.
Seemingly insignificant sparks often ignite significant changes. While current large models are still finding their niches, they are gradually infiltrating industries and taking on shallow agent roles.
A notable sign is that large models are no longer limited to chatting, poetry, and art but are actively entering sectors like mining, government, finance, healthcare, and logistics to fulfill their ultimate missions.
For example, in mining, Huawei's Pangu Mine large model automates inspections in coal mines, replacing humans in hazardous environments and improving safety and efficiency.
JD.com emphasizes that foundational large models are trained, while enterprise-specific models are used. In logistics, its Yanxi Da Model's Xiaoge Terminal Assistant streamlines delivery processes for over 350,000 JD.com couriers.
In retail, JD.com's AIGC marketing tool "Jingdiandian" based on the Yanxi Da Model assists merchants in creating product images and marketing copy, enhancing sales potential.
Embedding large models in industries and fostering their growth is a consensus among major players, akin to a spark that will eventually ignite a prairie fire.
Closing Thoughts
After the hype subsides, only a few players will remain in the game of large models.
Faced with data, computing power, and cost realities, both supply and demand are returning to rationality.
Between genuine usefulness and profitability, large models have a long way to go.
-
![]()
It's Kunlunxin's Turn to Play
-
![]()
Is the New Performance Peak Just the Starting Point? What Will Be Crystal-Optech's Next Destination?
-
![]()
Goertek Pours 69 Million Yuan into Elite Precision: Ramping Up Optical Precision Manufacturing and R&D Capabilities
-
![]()
Avatr Attempts HKEX Listing Again, With 20,000 Vehicles Sold in First Five Months
-
![]()
NVIDIA Announces 10-Fold Production Capacity Increase in 2 Years, Disrupting the Energy Storage Industry
-
![]()
AI Enters the Second Half: Models Are No Longer Scarce, What’s Truly Scarce Are Computing Power, Scenarios, and Trust
-
![]()
Rediscovering Momentum After Years of Obscurity: What Fuels Changhong TV's Resurgence?
-
【In-depth】Current Market Status and Key Enterprise Analysis of Confocal Fluorescence Microscopes in 2026