AI models could scale 10,000x by 2030, report says
 09/02 2024
09/02 2024
 553
553
The recent advances in artificial intelligence (AI) can be attributed primarily to one factor: scale.
Around the turn of the century, AI labs observed that continuously expanding the size of algorithms or models and consistently feeding them more data could significantly enhance their performance.
The latest batch of AI models boasts trillions of internal connections and learns to code like us by consuming vast resources on the internet.
Training larger algorithms necessitates greater computational power. Consequently, according to EpochAI, a nonprofit AI research organization, the computational power dedicated solely to AI training has doubled annually to achieve this.
If this growth persists until 2030, future AI models will possess computational capabilities that are 10,000 times more potent than today's most advanced algorithms, such as OpenAI's GPT-4.
“If this continues, we might see massive advances in AI by the end of the decade, akin to the difference between GPT-2's rudimentary text generation in 2019 and GPT-4's sophisticated problem-solving capabilities in 2023,” Epoch wrote in a recent research report.

However, modern AI has already consumed vast amounts of electricity, tens of thousands of advanced chips, and trillions of online instances. Meanwhile, the industry has experienced chip shortages, and research indicates it may run out of high-quality training data.
Assuming companies continue investing in AI expansion: Is such growth feasible technologically?
Epoch examines four major constraints on AI expansion in its report: power, chips, data, and latency. Summary: Maintaining growth is technically possible but uncertain. Here's why:
01. Power: We need a lot of it
According to Epoch's data, this equates to the annual electricity consumption of 23,000 American households. However, even with efficiency gains, the power required to train a cutting-edge AI model in 2030 will be 200 times that of today, approximately 6 gigawatts. This represents 30% of the current electricity consumption of all data centers.
Few power plants can provide this much power, and most likely have long-term contracts. But this assumes one power plant supplies a single data center.
Epoch believes companies will seek regions where they can draw power from multiple plants through the local grid. Considering planned utility growth, this path, though tight, is feasible.
To better break bottlenecks, companies can distribute training across multiple data centers. In this scenario, they transmit training data in batches between independent data centers in multiple geographic locations, reducing power demands at any one site.
This strategy necessitates fast, high-bandwidth fiber connections, which is technically feasible, as evidenced by early examples like Google's Gemini supercomputer training runs.
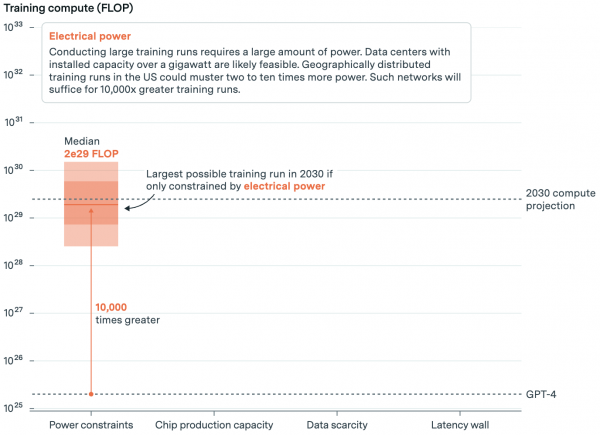
In summary, Epoch outlines various possibilities ranging from 1 gigawatt (local power) to 45 gigawatts (distributed power). The more power companies harness, the larger the models they can train. With limited power, models can be trained with computational capabilities roughly 10,000 times greater than GPT-4.
02. Chips: Can they meet computational demands?
All this power is used to run AI chips. Some of these chips provide customers with complete AI models, while others train the next batch. Epoch delves into the latter.
AI labs use graphics processing units (GPUs) to train new models, with NVIDIA leading the GPU market. TSMC manufactures these chips and pairs them with high-bandwidth memory interposers. Forecasts must consider all three steps. According to Epoch, GPU production may have spare capacity, but memory and packaging could hinder growth.
Considering projected industry capacity growth, they estimate 20 to 400 million AI chips for AI training by 2030. Some will serve existing models, and AI labs can only purchase a fraction.
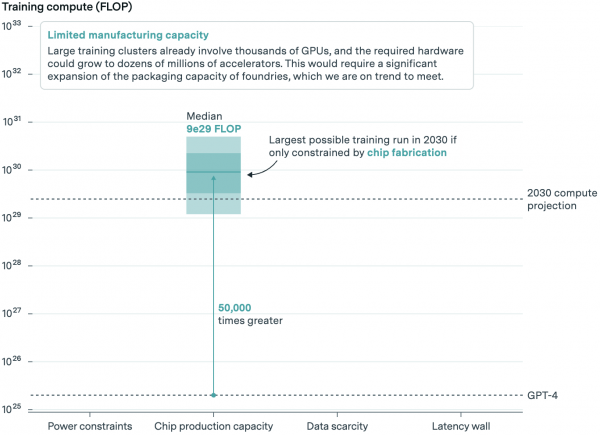
The wide range indicates significant uncertainty in model availability. But considering projected chip capacity, they believe a model could be trained with computational capabilities roughly 50,000 times greater than GPT-4.
03. Data: AI's online education
AI's insatiable appetite for data and impending scarcity are well-known constraints. Some predict a dearth of high-quality public data streams by 2026. But Epoch believes data scarcity won't hinder model development until at least 2030.
They write that at current growth rates, AI labs will exhaust high-quality text data within five years, and copyright lawsuits could also affect supply.
Epoch believes this adds uncertainty to their models. But even if courts rule in favor of copyright holders, complex enforcement and licensing agreements, like those adopted by companies like VoxMedia, TIME, and The Atlantic, suggest limited supply impacts.
Crucially, current models use more than just text in training. Google's Gemini, for instance, is trained on image, audio, and video data.
Non-text data can augment text data supplies through captions and scripts. It can also expand model capabilities, like identifying fridge food images and suggesting dinners.
More speculatively, it could even lead to transfer learning, where models trained on multiple data types outperform those trained on just one.
Epoch claims evidence suggests synthetic data can further expand data volumes, though it's unclear by how much.
DeepMind has long used synthetic data in its reinforcement learning algorithms, and Meta has employed some synthetic data to train its latest AI models.
However, there may be hard limits on how much synthetic data can be used without degrading model quality. Moreover, generating synthetic data requires even more expensive computational power.
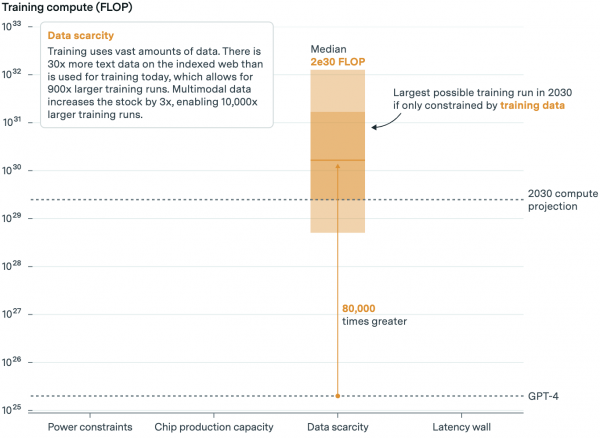
Overall, though, including text, non-text, and synthetic data, Epoch estimates sufficient data to train AI models with computational capabilities 80,000 times greater than GPT-4.
04. Latency: Bigger means slower
The final constraint relates to the size of upcoming algorithms. The larger the algorithm, the longer data takes to traverse its artificial neuron networks. This could mean training new algorithms becomes impractically slow.
This is somewhat technical. In brief, Epoch examines potential future model sizes, the batch sizes of training data processed in parallel, and the time required to process data within and between AI data center servers. This enables estimating how long it takes to train a model of a given size.
Key Takeaway: Training AI models with current setups will eventually hit ceilings, but not for long.
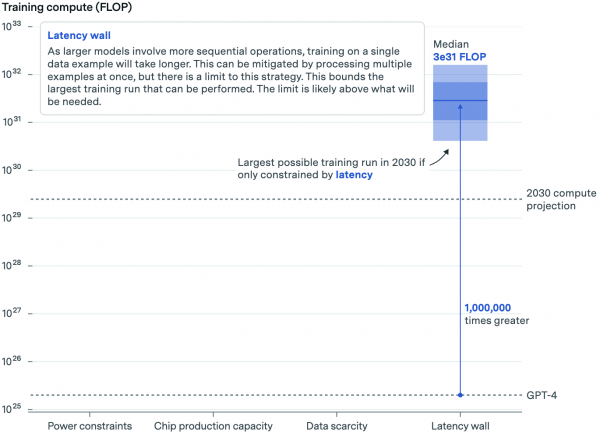
Epoch estimates we could train AI models with computational capabilities 1 million times greater than GPT-4 using current practices.
05. Scaling up: 10,000x
We'll note that under each constraint, the possible size of AI models grows, meaning the upper limit for chips is higher than power, the limit for data is higher than chips, and so on.
But if we consider all constraints together, the model can only realistically achieve the first bottleneck it encounters. In this case, the bottleneck is power. Even so, substantial expansion is technically feasible.
“Taken together, these AI bottlenecks imply that training runs up to 2e29 FLOPs are feasible by the end of the decade,” Epoch believes.
This would represent roughly a 10,000x expansion relative to current models, suggesting historical expansion trends could continue uninterrupted until 2030.
While all this suggests continued expansion is technically feasible, it also makes a fundamental assumption: AI investments will grow as needed to fund expansion, and expansion will continue yielding impressive, and importantly, useful advances.
Currently, every indication is that tech companies will continue pouring historic sums of cash into AI. AI-fueled spending on new equipment, real estate, and more has jumped to levels unseen in years.
“When you're going through a curve like this, the risk of underinvesting is much greater than the risk of overinvesting,” Alphabet CEO Sundar Pichai said on the company's last earnings call.
But spending needs to grow further still. Anthropic CEO Dario Amodei estimates that today's trained models could cost up to $1 billion, with next year's models potentially costing close to $10 billion, and each subsequent model potentially costing $100 billion over the following few years.
It's a dizzying figure, but one corporations may be willing to pay. Microsoft, for instance, is reportedly pouring so much money into its Stargate AI supercomputer project, a collaboration with OpenAI set to launch in 2028.

It goes without saying that the willingness to invest tens or hundreds of billions of dollars is not guaranteed. After all, this figure surpasses many countries' GDPs and a significant portion of tech giants' current annual revenues. As the AI shine wears off, continued AI growth may become a case of “what have you done for me lately?”
Investors are already examining the bottom line. Today, investment amounts pale in comparison to the returns. To justify increasing investments, companies must demonstrate continually scaling up to produce more powerful AI models.
This means upcoming models face mounting pressure to go beyond incremental improvements. If returns decline, or if enough people refuse to pay for AI products, that could change.
Moreover, some critics argue that large language and multimodal models may just be an expensive dead end. And there's always the possibility of breakthroughs, like this round, suggesting we can accomplish more with less. Our brains keep learning with the energy of a lightbulb, without the massive data volumes of the internet.
Epoch argues that even so, if current methods “can automate a substantial fraction of economic tasks,” their economic returns could justify the expense, potentially reaching trillions of dollars. Many in the industry are willing to bet on it. But whether they're right remains to be seen.
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?