The MoE large model is booming, what kind of future do AI vendors see in the new architecture?
 06/12 2024
06/12 2024
 680
680

Article | Intelligent Relativity
Long ago, in a distant kingdom, the king decided to build a magnificent palace to showcase the country's prosperity and power. He invited the most famous architect in the country to design this palace, renowned for his exceptional talent and wisdom.
However, although the palace designed by this architect was exquisite, it was too complex and intricate, leading to numerous difficulties during the actual construction process, and even skilled craftsmen felt overwhelmed.
At this time, the king had three ordinary stonemasons under his command. Although they lacked fame and their skills were not top-notch, they often worked together, enjoying excellent rapport and complementary skills. Facing the challenges of palace construction, they did not retreat but gathered to discuss and brainstorm solutions. Through numerous attempts and adjustments, they invented several new tools and construction methods, simplifying the complex building process and making the originally difficult-to-implement design feasible.
In the end, through cooperation, these three ordinary stonemasons not only helped solve the engineering problems but also accelerated the construction progress of the palace, ensuring the quality of the project, much to the surprise of the king and everyone. Their story quickly spread throughout the kingdom and became a popular saying - "the wisdom of the many surpasses the genius of one."
The truth reflected in this saying is precisely the design philosophy of the MoE hybrid expert model, which is currently booming in the AI industry. With the popularity of the MoE model, the development of AI large models is no longer pursuing "the genius of one person" but moving towards "the wisdom of the many".
What kind of future do mainstream vendors see in the new architecture of the MoE model? Can the popular saying "the wisdom of the many surpasses the genius of one" be realized in the MoE model?
How many large model vendors are betting on "the wisdom of the many"?
Currently, overseas, mainstream large models such as OpenAI's GPT-4, Google's Gemini, Mistral AI's Mistral, and xAI's Grok-1 have adopted the MoE architecture.
Domestically, Kunlun Tech's Tiangong 3.0, Inspur Information's Yuan 2.0-M32, Tongyi Qianwen Team's Qwen1.5-MoE-A2.7B, MiniMax's fully released abab6, and DeepSeek's DeepSeek-MoE 16B, among others, also belong to the MoE model.
More and more vendors are starting to get involved in the development and application of the MoE model. Rather than "the wisdom of the many," the specific working principle of the MoE model is closer to the ancient Chinese saying, "each has his own speciality." It works by categorizing tasks and assigning them to multiple specific "experts" for resolution.
Its workflow is roughly as follows: first, the data is divided into multiple blocks (tokens), and then each group of data is distributed to specific expert models (Experts) for processing through a gating network technology. In other words, it allows professionals to handle professional matters, ultimately aggregating the processing results of all experts and outputting answers based on relevance weighting.
Of course, this is just a general idea. The location of the gating network, the model, the number of experts, and the specific integration scheme of MoE with the Transformer architecture vary among different vendors and have gradually become a direction of competition - whose algorithm is superior can create a gap in the MoE model in this process.
For example, Inspur Information has proposed an attention-based gating network (Attention Router). The highlight of this algorithm structure is that it can learn the relevance between adjacent words through localized filtering-based attention (LFA) and then calculate global relevance, enabling it to better learn the local and global linguistic features of natural language, resulting in more accurate semantic understanding of natural language and better matching with expert models. This ensures a high level of collaborative data processing among experts and improves model accuracy.
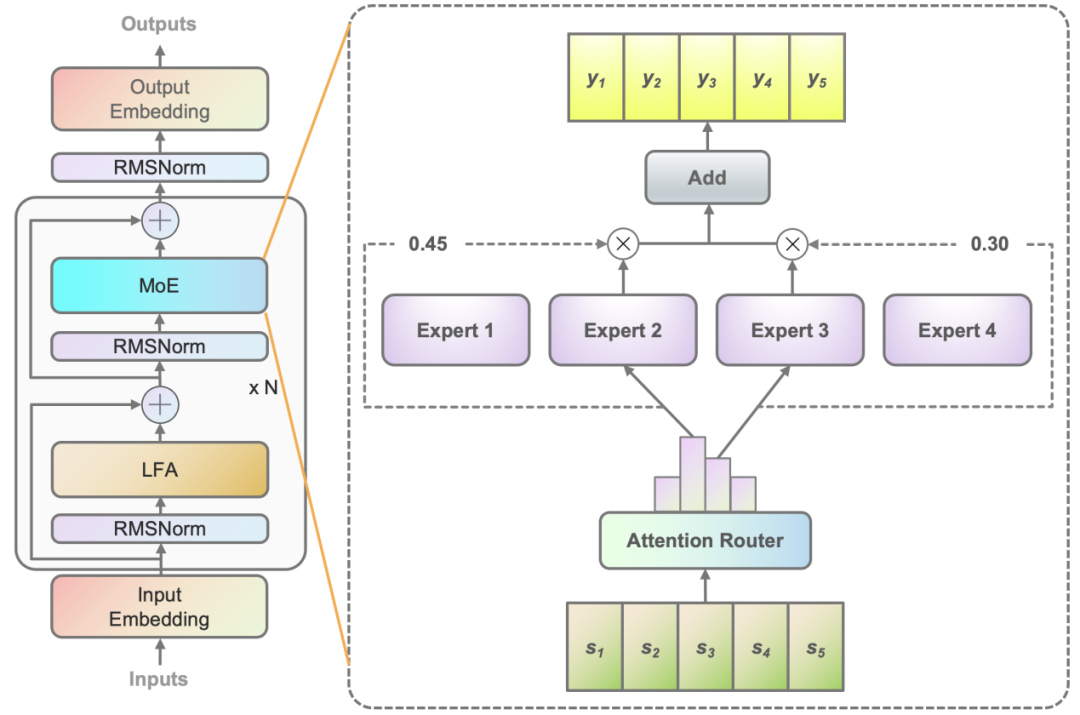
Attention-based Gating Network (Attention Router)
Leaving aside the current innovations and optimizations in algorithm structures among different vendors, the performance improvement brought by the MoE model's working philosophy itself is quite significant - it achieves higher expert specialization and knowledge coverage through fine-grained data segmentation and expert matching.
This allows the MoE model to more accurately capture and utilize relevant knowledge when handling complex tasks, improving the model's performance and applicability. Therefore, when "Intelligent Relativity" tried to experience AI search powered by Tiangong 3.0, it was found that for users' relatively general questions, the AI could quickly break them down and provide detailed comparisons of multiple project parameters, which is indeed powerful.
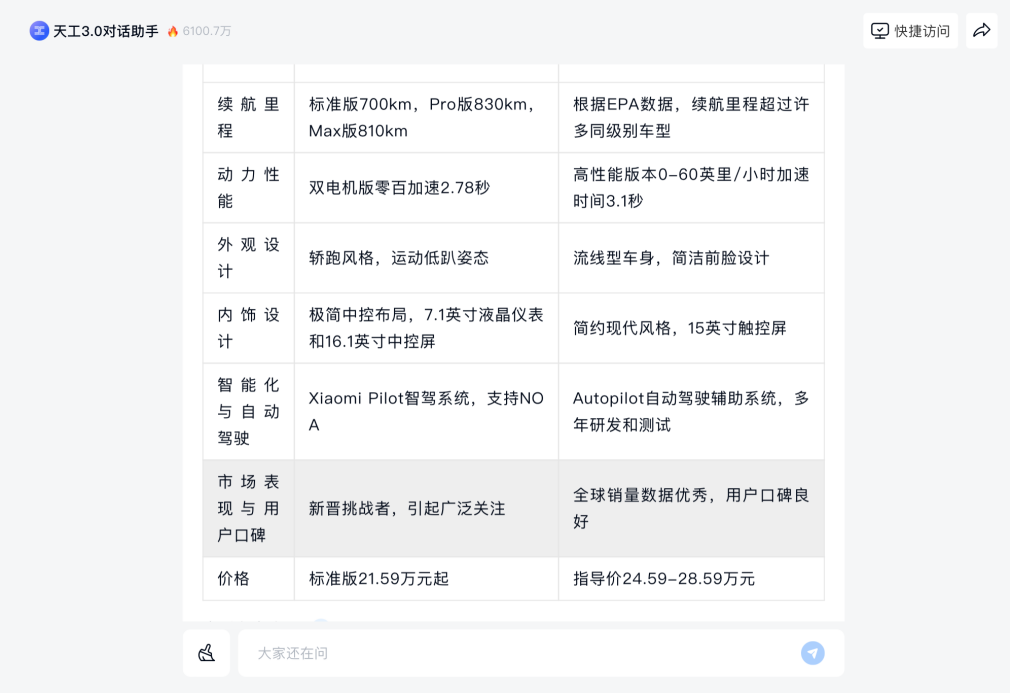
Results of the Tiangong AI search question "Compare Xiaomi su7 and Tesla Model 3"
From this, we can see that in comparing the two car models, AI cleverly broke down this question into multiple items such as driving range, power performance, exterior design, interior design, intelligence and autonomous driving, market performance and user reputation, price, etc., and processed them separately to obtain relatively complete and professional answers.
This result of "the wisdom of the many" is precisely the advantage of "each has his own speciality" - the reason why the MoE model has attracted increasing attention from vendors is primarily because its new problem-solving approach has significantly improved model performance. Especially with the emergence of complex problems in the industry, this advantage will enable the MoE model to be more widely applied.
Behind the rush of major vendors to open source the MoE model
While the MoE model is widely applied, some vendors are also rushing to open source their own MoE models. Not long ago, Kunlun Tech announced the open sourcing of Skywork-MoE with 200 billion parameters. Prior to that, Inspur Information's Yuan 2.0-M32, DeepSeek's DeepSeek-MoE 16B, and others have also been open-sourced.
The significance of open sourcing lies in making the MoE model more prevalent. So, why do vendors choose the MoE model for the market?
Aside from performance, a more prominent advantage of the MoE model is its improvement in computing efficiency.
DeepSeek-MoE 16B maintains performance comparable to a 7B parameter-scale model while requiring only about 40% of the computational effort. Meanwhile, the 3.7 billion parameter Yuan 2.0-M32 achieves a performance level comparable to the 70 billion parameter LLaMA3 while consuming only 1/19 of the computational power of LLaMA3.
This means that for the same level of intelligence, the MoE model can be achieved with less computational effort and memory requirements. This is because the MoE model does not need to fully activate all expert networks in applications but only needs to activate some to solve related problems, avoiding the awkward situation of "using a sledgehammer to crack a nut."
For example, although the total number of parameters in DeepSeek-MoE 16B is 16.4B, only about 2.8B parameters are activated during each inference. At the same time, its deployment cost is relatively low, allowing it to be deployed on a single 40G GPU, making it more lightweight, flexible, and economical in practical applications.
In the current situation of increasingly tight computing resources, the emergence and application of the MoE model can be said to provide a relatively realistic and ideal solution for the industry.
What's more worth mentioning is that the MoE model can easily scale to hundreds or even thousands of experts, significantly increasing the model's capacity while also allowing parallel computing on large distributed systems. Since each expert is only responsible for a portion of the data processing, it can significantly reduce the memory and computational requirements of individual nodes while maintaining model performance.
In this way, there is a very feasible path for the popularization of AI capabilities. This feature, coupled with vendors' open sourcing, will enable more small and medium-sized enterprises to access AI large models and obtain relevant AI capabilities without investing heavily in large model development and excessive computing resources, promoting technology popularization and industry innovation.
Of course, in this process, while providing open-source technology to the market, MoE model vendors also have the opportunity to attract more enterprises to become paying users, thereby paving the way for commercialization. After all, the advantages of the MoE model are clear, and perhaps more enterprises will attempt new architectures to expand AI capabilities in the future. The earlier the open sourcing, the more market players will be attracted to engage.
Open sourcing itself is a cognitive judgment and advance layout of industry trends. In this sense, the MoE model has the potential to become the key to the popularization of AI capabilities in the future.
Final thoughts
As a technical hotspot in the current AI field, the MoE large model brings new opportunities for AI development with its unique architecture and outstanding performance. Whether it is in application or open sourcing, with continuous technological progress and the expansion of application scenarios, the MoE large model is expected to exert tremendous potential in more fields.
Just like the fable story at the beginning, people may initially pursue the "genius of one person," but they will gradually realize that "the wisdom of the many" that understands cooperation and complementarity is the key to building and implementing projects, just like the current popularity of the MoE large model in the AI field.
*All images in this article are sourced from the internet.
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital
-
![]()
Why are 3C Brands Flocking to Douyin Mall During 618?
-
![]()
Token Economy Falters as Economic Tokenization Faces Challenges
-
![]()
Lenovo's Monthly Surge of 109%, Foxconn Industrial Internet's Market Cap Surpasses Kweichow Moutai: A Collective Resurgence of the 'IT Old Guard'?
-
![]()
After Zhang Xue's Victory, Where is Motorcycle Intelligence Headed?






