Will Zero One Thing become AI First in pursuit of TC-PMF?
 07/08 2024
07/08 2024
 605
605
Zero One Thing, aiming to rival GPT-5, has released the closed-source large model Yi-Large after the Yi open-source version.
It is reported that in authoritative evaluation sets for both Chinese and foreign instructions, Yi-Large performed better than the top five international models.
In fact, in May last year, just six months after its establishment, Zero One Thing released its first bilingual Chinese-English large model, the Yi series. From the start, Kai-Fu Lee set a grand and challenging goal: "to become World's No.1".
Born as a "hot chicken", Zero One Thing has also relied on its large company background team and excellent model performance to reach a valuation of $1 billion.
At the Yi-Large launch conference, Kai-Fu Lee also announced that Zero One Thing has initiated training for the next-generation Yi-XLarge MoE model, aiming to challenge the performance and innovation of GPT-5.
However, as believers in AGI, Zero One Thing needs to consider whether pursuing GPT-5 will affect its own AGI development path.

I. How far is Zero One Thing from AGI in this fiercely competitive market?
In an interview with APPSO, Kai-Fu Lee said, "We are pragmatic believers in AGI. We must use the fewest chips and the lowest cost to train the best models we can. At the same time, we will continue to explore and find TC-PMF."
It is reported that Zero One Thing currently has nearly 10 million overseas users for its productivity applications, and its estimated revenue for a single ToC product this year is 100 million yuan.
However, this 100 million yuan revenue from a single product only represents TC-PMF and does not mean that Zero One Thing has achieved TC-PMF at the AGI level.
You should know that unlike weak models like NLP and VC, a materialized AGI is an omnipotent intelligent entity that integrates expert knowledge from various industries. It is a general artificial intelligence that can help the demander complete a complete set of needs and has adaptability and proactivity in the process.
The realization of AGI requires considerable costs to a certain extent, and these costs may not be achievable with tens of billions or hundreds of billions of dollars.
However, Kai-Fu Lee has also stated that Zero One Thing will not rely solely on a mindset of spending heavily to achieve the large model's implementation in scenarios with 10 billion or 100 billion dollars.

Compared to the irrational ofo-style money-burning approach in the industry, Zero One Thing prefers to allow large models to accumulate energy for long-term growth with a healthy and positive ROI.
But what Zero One Thing needs to consider is, even if it develops through finding TC-PMF, will it necessarily bring it closer to AGI?
In the development of AGI, cognitive AI is the clearest, most definitive, and most direct path to AGI.
Although several cognitive architecture projects have been actively ongoing for decades, so far, none has shown sufficient commercial prospects, been widely adopted, or received particularly sufficient funding.
The reasons are multifaceted and complex, but a common characteristic is that they are operating in a modular and inefficient manner and lack in-depth learning feedback and cognitive theory.
Looking back at the development of AI hardware in recent years, it can be seen that the progress of AGI in hardware has been constantly breaking through. Therefore, what really affects the realization of AGI is not the obstacles posed by software and hardware, but rather accurate development projects and sufficient financial support.

For Zero One Thing, which is currently developing weak models, "accurate development projects" may also be difficult. And achieving AGI and TC-PMF through existing open-source and closed-source large models and the one-stop AI platform Wanzhi is even more challenging.
Because for now, Wanzhi, a one-stop AI workstation that can handle meeting minutes, weekly reports, writing assistants, speed reading documents, and making PPTs, is positioned as a 2C productivity tool, but it is also mostly a text generation-based large model in its application.
This is still far from an intelligent entity that can help the demander complete a complete set of needs.
Whether it's Zero One Thing or other large model players, they seem to be more focused on a narrow field of artificial intelligence in order to quickly implement large models in specific scenarios.
For example, Zero One Thing's Yi series of large models covers areas such as AI writing, AI programming, healthcare, consumer 3C, biochemistry, and environmental materials.

However, an objective standard for developing AGI is whether the AI work done in the process of achieving AGI has clearly defined steps or an overall detailed plan. Few AI works meet this standard, including Zero One Thing.
For Zero One Thing, what can be seen currently is actually the core methodology of developing large models, such as model-infrastructure integration—parallel development of models and AI Infra; and model-application integration—parallel development of models and applications.
II. How can AGI believers be vigilant against the "narrow AI trap"?
However, in the integration of the basic model, Zero One Thing not only develops AI Infra independently but also sets AI Infra as an important direction, with a 1:1 ratio of model team members to AI Infra team members.
Of course, for Zero One Thing, which has ROI requirements for itself, a pragmatic tactical development approach is often more stable. At the same time, focusing on talent recruitment may help Zero One Thing develop towards AGI better.
To approach the true meaning of AGI, the market needs to shift from the second wave of AI to the third wave, from statistical generative AI to cognitive AI.
That is, from large models characterized by statistics and reinforcement learning to large models centered on autonomous, real-time learning, adaptation, and advanced reasoning.
But how can Zero One Thing, which is eager to validate TC-PMF through Wanzhi, be sure that taking the application layer path is more conducive to the realization of AGI?
You should know that the process of AI wave transitions is both simple and complex. Simple in terms of the cognitive simplicity of the entire transition, but complex not only in terms of "turning around and starting over" to change the benchmark for large model development but also in needing to be vigilant against the emergence of the "narrow AI trap".
Put simply, the "narrow AI trap" is that even if everything is smoothly progressing towards AGI's predefined goals—with a solid theoretical foundation and development plan, an excellent development team and strong funding, as well as correct target benchmarks and development standards—there is still the hidden danger of the "narrow AI trap".
Because the market's urgent desire to achieve AGI will, to some extent, lead most enterprises to ultimately utilize external human wisdom to achieve specific results or make progress on given benchmarks, rather than integrating wisdom (adaptability, autonomous problem-solving ability) into the system.
To put it bluntly, upgrading large models biased towards specific tasks is actually contrary to the adaptability and proactivity pursued by AGI.
If continuous reinforcement learning through specific tasks is employed, the likely result is that only nominally AGI-like narrow AI work will be achieved. Moreover, all large models that Zero One Thing can currently implement for specific scenario applications and solve specific problems are collectively referred to as narrow AI.
However, Zero One Thing's achievements in multimodal large models are evident.
As a necessary path for developing AGI, Zero One Thing's multimodal large model Yi-VL-34B version surpassed a series of multimodal large models with 41.6% accuracy on the MMMU test set, second only to GPT-4V (55.7%).
If comparing with GPT is set aside, 41.6% accuracy is not outstanding for a multimodal large model.
You should know that the integrity of information, environmental adaptability, naturalness of interaction, and universal application are the four most important aspects of multimodal development.
Among them, the integrity of information requires the large model system to consider more information dimensions to determine the quality and accuracy of the final decision. Conversely, 41.6% accuracy indicates the limited nature of the multimodal large model's data types, resulting in the system not considering more information dimensions during decision-making.
In addition, Zero One Thing's multimodal team is exploring multimodal pre-training from scratch to quickly approach and exceed GPT-4V, reaching the world's first-tier level.
GPT is not only Zero One Thing's most desired competitor to catch up with but also the rival that hundreds of large model companies want to surpass. However, when AGI has not yet taken shape, Zero One Thing's vision should be broader.
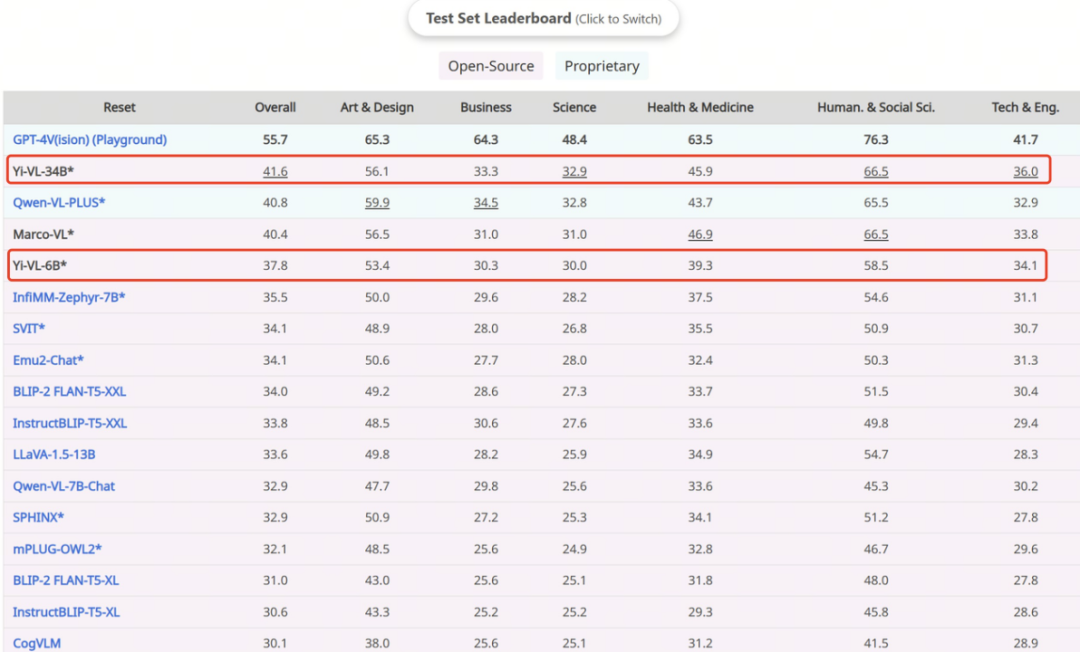
Image Source: AI Frontline
After all, in the past seven to eight decades of AI development, it can be seen that every new wave of AI is brought about by significant AI advances driven by leaps in model parameters, training sample sizes, and computing power.
Overseas companies are more adept at continuously investing in Scaling Law to increase model parameters, while domestic companies can only take one step at a time.
For example, developing more cost-effective AI chips, more energy-efficient intelligent computing centers, AI model acceleration technologies, accelerating multimodal model architecture innovation and data synthesis, and multimedia data annotation technology innovation.
III. Perhaps the focus of the third wave of AI is monetization?
In the past two years, market discussions on model performance improvements have focused solely on the training and algorithmic improvements of multimodal large models. For initial scenario implementation, they have also been free of charge.
Perhaps, in a market with limited financing, the current focus of large model companies, in addition to seeking commercial implementation, is more on increasing large model parameters, aiming to obtain more financing possibilities by expanding imagination space.
After all, in the domestic capital market, the direction of funds often tends to be more deterministic rather than gambling on uncertainty.
Similarly, during the difficult period of obtaining financing after 2023, large models tend to move towards 2B2C to make money and survive. C-end companies like OpenAI, Midjourney, and Perplexity provide productivity liberation tools to individual users and monetize through monthly subscription models.
B-end companies like Microsoft and Salesforce integrate AI technology into traditional products and provide vertical customized services, monetizing through monthly subscriptions or usage models.
Domestic companies that have not yet achieved monetization are constantly in the process of seeking commercial monetization.
For example, Baidu launched the Wenxin Yiyan subscription model on the C-end and provides underlying architecture and solutions on the B-end; 360 focuses on AI office on the C-end and AI security and knowledge management scenarios on the B-end; iFlytek attempts to combine large models with its hardware products.
Currently, Wanzhi AI Assistant is completely free to users, but it is reported that Wanzhi will introduce a paid model in the future based on product development and user feedback.
He believes that the development of large model C-end products can be divided into six stages: initially as a productivity tool, gradually expanding to entertainment, music, and gaming. Then entering the search field, followed by the e-commerce market; further extending to social media and short video; and ultimately developing to the O2O product stage.

Image Source: Yeswin
However, in the domestic market, C-end users do not seem to lack productivity tools or entertainment and social tools. Will Wanzhi, after starting to charge, really be as successful as overseas?
Currently, based on the trend of large models targeting both C-end and B-end markets, most large models mainly charge on the B-end, with fewer charging on the C-end and lower user willingness to pay.
This also means that among the many large models positioned as productivity tools, most C-end users will prefer lower-priced options.
Moreover, according to Similar data, the top three AI products in terms of domestic web traffic in May were Kimi, Wenxin Yiyan, and Tongyi Qianwen, with 22.5 million, 17.8 million, and 8 million visits, respectively. Wanzhi ranked tenth with only 320,000 visits.
Zero One Thing may have impressive achievements overseas, but not necessarily in China.
References:
Smart Connected Things: AI unicorn "01 Things" accelerates its overseas expansion matrix, and Kai-Fu Lee, who "only does To C," is gradually moving into the AI 2.0 era.
APPSO: Zero One Thing releases the trillion-parameter model Yi-Large, and Kai-Fu Lee says that Chinese large models are catching up with the US, aiming to rival GPT-5.
Z Finance: In-depth | Well-known AI unicorns are accelerating their overseas expansion, and Zero One Thing's Yi-Large lands on the global top model hosting platform Fireworks.ai.
Z Finance: In-depth | The "new AI Four Dragons" with over 10 billion valuations are born, Zero One Thing lags behind, and Lightyear is out!
AI Frontline: Zero One Thing releases the Yi-VL multimodal language model and open sources it, ranking second only to GPT-4V in evaluations.
-
![]()
Is the Future of Extended-Range EVs Pure Electric or Li Auto’s 5C Extended-Range? A Li Auto Executive Shares Insights
-
Ant Group’s New Board of Directors: Signaling a New Era?
-
![]()
Google Initiates TPU Sales, as Industry Leaders Eye AI Chips for 'Cost-Effective Tokens'
-
![]()
Input Methods: The Rising Star in AI! WeChat, Doubao, and Qianwen Lead the Charge into the Voice Input Era
-
![]()
Struggling to Sell? Cut It Out! Toyota, Volkswagen, and Changan Lead the Charge in Streamlining, Eliminating Non-Core Products in the Blockbuster Model Era
-
![]()
Arm China and Volcano Engine Join Forces to Expedite Cloud Computing and AI Infrastructure Rollout
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?