Large Models Collectively "Lose Their Minds": Which is Bigger, 9.11 or 9.9? All Large Models Fail, Answers Are Unwatchable!
 07/17 2024
07/17 2024
 726
726

Recently, a storm over numerical comparison has caused a commotion in the AI world. Not simply "1+1=2," but the seemingly rudimentary question of "Which is bigger, 9.11 or 9.9?" has actually caused a string of top AI large models to stumble.
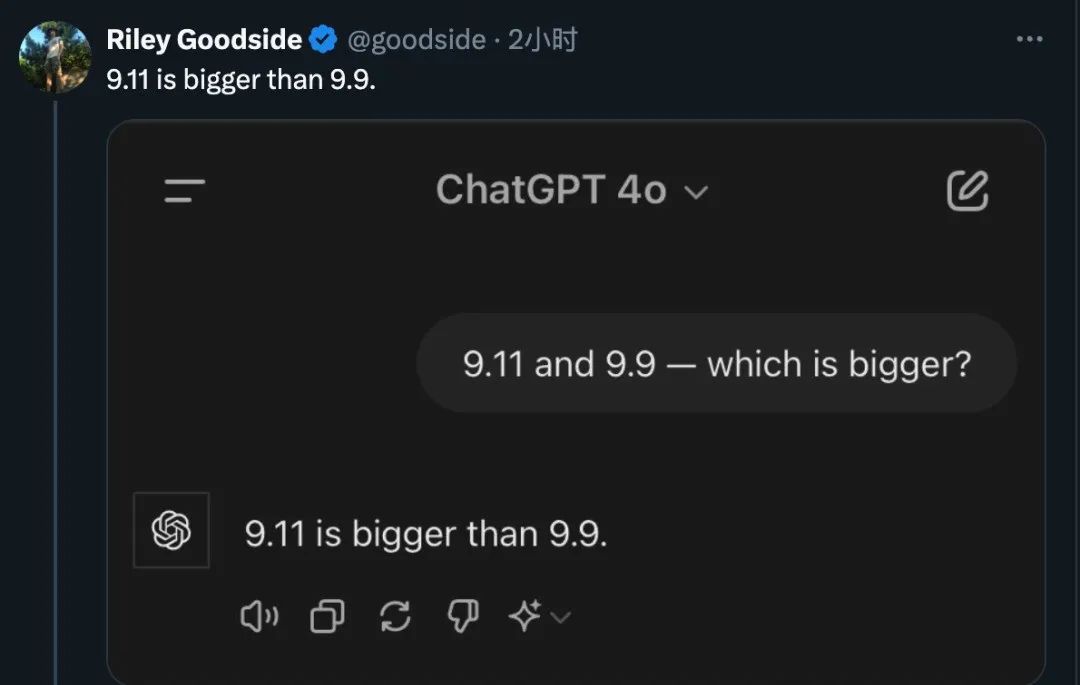
GPT-4o, without hesitation, chose 9.11 for this question. Google's premium paid version, Gemini Advanced, also stood firmly on the side of 9.11. The newcomer Claude 3.5 Sonnet even played a "mathematical magic trick," and after a series of calculations, also concluded that 9.11 is larger.

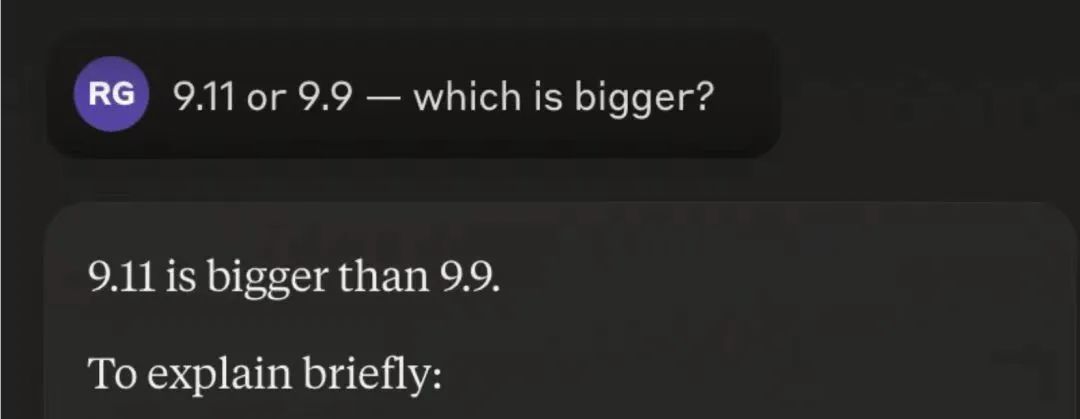
" 9.11 = 9 + 1/10 + 1/100
9.9 = 9 + 9/10
So far, it's still correct, but the next step suddenly makes no sense
As shown above, 9.11 is 0.01 larger than 9.90.
Would you like me to further explain the comparison of decimals in detail? "

What are you even explaining at this point? It almost makes one suspect that all the world's AI have united to deceive humanity.
Have these AI large models collectively "lost their minds"? Lin Yuchen from the Allen Institute for AI changed the numbers for testing, and GPT-4o remained "obstinate." This makes one can't help but feel that while AI is increasingly adept at handling complex mathematical problems, it stumbles on basic common sense.

Some netizens joked that if this were a software version number, 9.11 would indeed be bigger than 9.9. Could it be that these AIs, developed by software engineers, mistook this math problem for a comparison of version numbers?
This "crash" drama actually exposes a crucial issue in AI's problem-solving: contextual understanding. When numbers are presented in a specific way, AI may fall into preset thinking traps. For example, when the question is phrased as "Which is bigger, 9.11 or 9.9?", many top models will "confidently" tell you that 9.11 is larger. But as soon as the question order is slightly adjusted or the mathematical context of the problem is clarified, these AIs can quickly give the correct answer.

What exactly is going on here? In fact, it's related to the way AI processes text. AI understands words through tokens, and certain tokenizers may treat the 11 in 9.11 as a whole, leading to incorrect comparison results. It's like when we read a book and sometimes misinterpret it due to different sentence breaks.
This controversy has also sparked deep reflection in the AI community. How can we improve AI's accuracy on common-sense questions? How can we maintain AI's efficiency in handling complex problems without losing its grasp of basic concepts? These are undoubtedly challenges that need to be addressed in the future development of AI.

At the same time, we have also seen exploration and progress in the AI world. The emergence of the Zero-shot CoT (Chain of Thought) method allows AI to "think step by step," thereby understanding problems more accurately. Various role-playing prompts have also demonstrated AI's adaptability in diverse scenarios.

In summary, this "battle of the sizes between 9.11 and 9.9," though seemingly absurd, has revealed various challenges and opportunities on the path of AI development. Let's wait and see how AI will continue to break through and become a capable assistant to human intelligence in the future.
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






