Which video generation model is the best? Comprehensive evaluation of Doubao, Keling, and Hailuo [AI Evaluation]
 09/27 2024
09/27 2024
 615
615

A more apt description would be that Doubao's video model upgrade has significantly elevated the aesthetic standards of domestic AI videos, making them more practical.
Author | Dou Dou
Produced by | Chanyejia
The domestic text-to-video field is also reaping the benefits.
Recently, Volcano Engine announced the official release of Doubao's large model for video generation. This marks the official start of the competition between the two major short video platforms in the text-to-video field.
Chanyejia also got a sneak peek in advance. Here are a few demos to give you a glimpse of what's to come.
It's clear that the generation results are on par with Sora.
It's worth noting that Sora was highly anticipated during its initial promotions and reports. However, to date, Sora has yet to be made available to the general public, essentially remaining a concept.
To provide a more objective assessment of Doubao's text-to-video model capabilities, Chanyejia applied for access to the beta version of Jimeng AI's Doubao Seaweed video generation model. We compared its performance with several domestic mainstream text-to-video models under the same prompt, uncovering some surprising new highlights in Doubao's model.
1. Adept at executing complex instructions
As we all know, when filming a movie, the director instructs actors to perform multiple shots, which are then edited into a coherent story. If a scene involves multiple characters, the director must coordinate their positions, entrance times, dialogue, actions, and more.
Only in this way can the resulting footage flow smoothly. However, most current text-to-video models are limited to simple instructions and single actions. For example, they may only generate a single shot without switching or offering much variety in character movements.
The resulting footage is similar to a still image. However, Doubao's video generation model has made significant breakthroughs.
Prompt: A group of friends are having dinner at a restaurant when one of them suddenly suggests a surprise plan.

The video generated by Doubao Seaweed involves complex character movements. Each character's actions and facial expressions are harmonious, although some details could be optimized. The model can generate scenes with multiple subjects and actions.

Hailuo AI continues to excel in overall composition and lighting. However, most characters in the video exhibit some degree of distortion.

Keling AI's generated video shows relatively simple human movements and lacks authenticity.

Tongyi Wanxiang's character movements are also relatively simple, with weaker authenticity and natural fluidity.
Overall, Doubao's video generation model is highly obedient, capable of following complex prompts, unlocking timed multi-action instructions and interactions between multiple subjects. It opens the door to unlimited imagination.
2. Smooth camera movements
Consistent and stable visuals
Another notable feature of Doubao's text-to-video model is its strong narrative quality in the generated videos.
Prompt: A man walks from a bright outdoor area into a dimly lit indoor space. The camera transition should be natural, with smooth lighting changes.
The model seamlessly connects the details and transitions of the surrounding environment and visuals beyond the prompt's text, showcasing its powerful generalization ability.
For example, the video generated from the following prompt is more visually appealing and coherent.
Prompt: A woman running down a dark, damp street

The cobblestone road, roadside houses, and running woman in the video are impeccably rendered in terms of movement logic, lighting, and fluency.

Keling's generated video shows irregular distortions in the woman's limbs.
Tongyi Wanxiang's video is overall impressive, but details like the ground require further refinement.

Hailuo AI faces similar issues to Tongyi Wanxiang. Upon closer inspection, the road surface in the running scene is not consistently rendered, and the transition between the character and the background is unnatural.
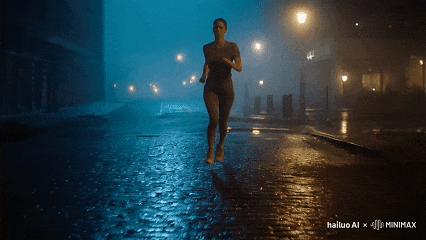
From the generated videos, it's clear that Doubao's text-to-video model produces consistent and stable visuals, maintaining harmony among characters, atmosphere, and environment while enabling natural camera transitions.
For instance, with Doubao Seaweed, you can immerse yourself in the excitement of a bodybuilding competition.
Or traverse a forest to witness a majestic snow-capped mountain in the distance.
Regardless of camera movements or transitions, the visual style, characters, lighting, and costumes remain consistent.
Another remarkable aspect is Doubao's ability to switch subject movements and camera angles. Simply put, as characters move in the scene, the camera can transition smoothly.
As seen in the following video generated by Doubao's text-to-video model, the camera first follows the subject, then switches to a close-up shot centered on the subject.
Prompt: Generate a video of a protagonist exploring a forest, including jumping over streams and climbing rocks.

Specifically, the video begins with an establishing shot to set the scene, then transitions to a push-in shot centered on the protagonist. This technique, known as "match cut," uses similar actions or movements in two shots to create a smooth transition and minimize visual jumps.
This technique requires meticulous filming and editing to ensure seamless action matching and visual coherence.
Yet, Doubao's video generation model achieves it.
In contrast, Keling AI's generated video lacks camera movement and transition.

Hailuo AI's generated video based on this prompt is commendable, but during the scene transition, a double image briefly appears on the left side of the screen before exiting, indicating room for improvement in scene transitions.

Tongyi Wanxiang's generated video effectively demonstrates its semantic understanding ability, particularly in the context of "jumping over streams and climbing rocks." However, it lacks scene and camera transitions, and there's room for improvement in character fluidity and naturalness.

Admittedly, Doubao's video generation model stands out.
According to the official introduction, Doubao's video generation model is based on the DiT architecture, which enables seamless transitions between dynamic shots and camera movements through efficient DiT fusion computing units. It supports various camera language capabilities such as zoom, pan, tilt, zoom out, and subject tracking. Its innovative diffusion model training method addresses the consistency challenges in multi-shot transitions, maintaining harmony among subjects, styles, and atmospheres during camera switches.
This represents a unique technological innovation in Doubao's video generation model.
3. Grand scene depiction
Optimized lighting, camera angles, and composition
In the text-to-video field, generating grand scenes often poses challenges due to the complexity of elements involved. However, our tests show that Doubao's text-to-video model performs admirably.
Comparing the generated videos from Doubao, Keling AI, Tongyi Wanxiang, and Hailuo AI (MiniMax text-to-video platform), Doubao's video stands out for its exceptional composition and color palette, even capturing the mist rising from a lake early in the morning.
One might mistake it for a scene from "The Animal Kingdom."
Prompt: Early in the morning, the first rays of sunlight pierce through the mist, illuminating a peaceful forest. A deer drinks from a stream, where ripples reflect golden glimmers.

Keling AI's video is commendable in color palette and composition, but the deer's movements lack fluidity and authenticity.

Tongyi Wanxiang's video also impresses, particularly in its semantic understanding. For instance, it captures the "golden glimmers reflected in the ripples" beautifully but leans more towards animation than reality.

Hailuo AI's video excels in realism but suffers from limited subject flexibility and textual understanding due to angle and composition issues, lacking aesthetic appeal.

In reality, Doubao's video generation model has been refined through iterations in business scenarios like Jianying and Jimeng AI, accumulating extensive data and technical experience in professional lighting arrangements and color harmonies. Its visuals seamlessly continue this tradition, enabling Doubao to capture intricate details while maintaining an aesthetic and realistic feel in grand scenes.
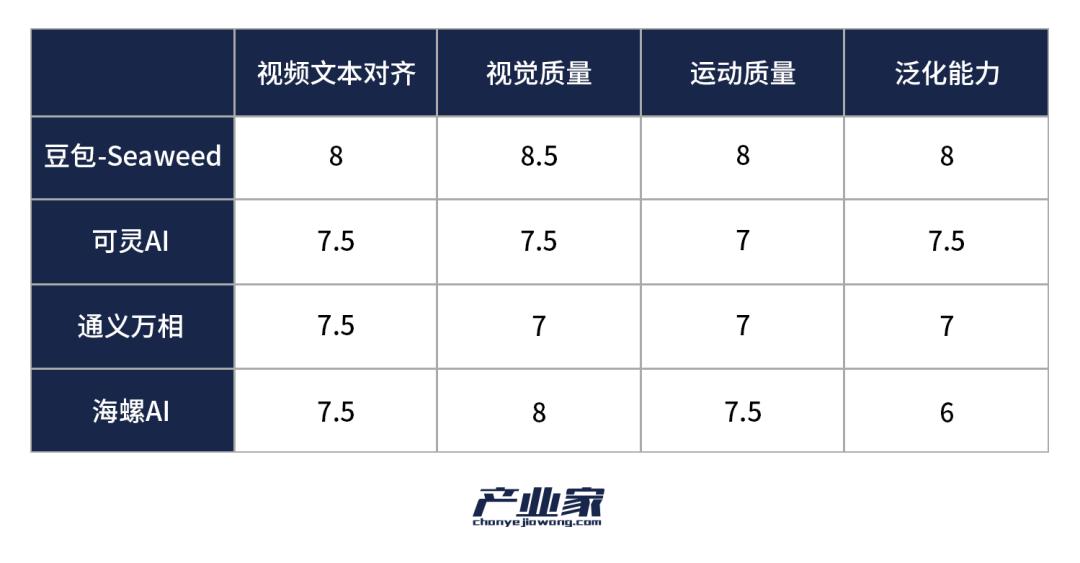
Illustration: Summary of video generation performance across platforms
4. Versatile in various styles and sizes
According to the introduction, Doubao's video generation model employs an optimized Transformer deep learning architecture, enhancing its power and generalization ability. Stylistically, it can generate videos in diverse artistic styles such as 3D animation, 2D animation, traditional Chinese painting, black and white, and thick painting.
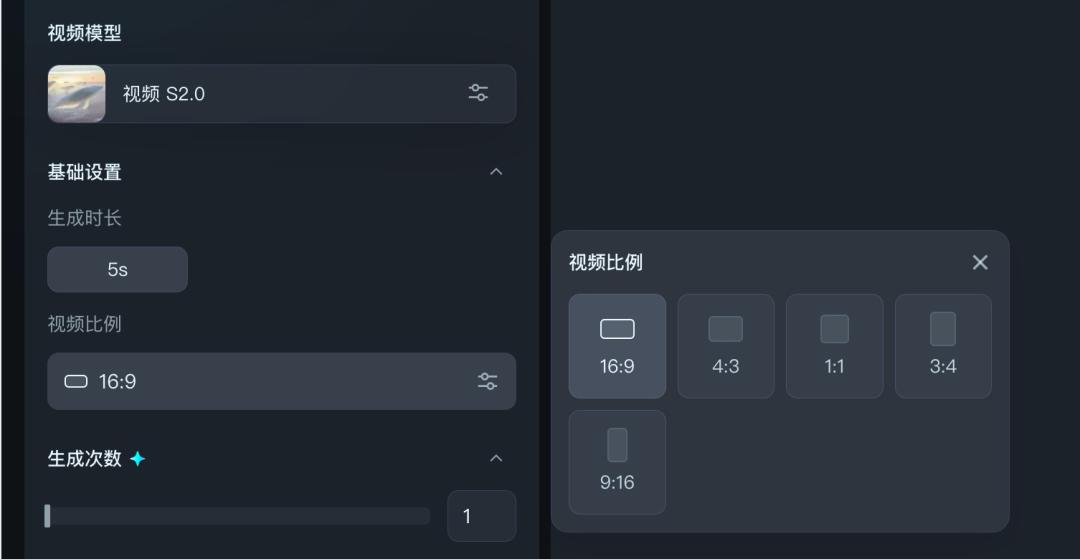
Furthermore, the generated videos are adaptable to different screen sizes, including ratios of 1:1, 3:4, 4:3, 16:9, 9:16, and 21:9, ensuring compatibility across cinema screens, TVs, computers, and mobile devices.
These videos can be used for various commercial purposes such as e-commerce marketing (e.g., product showcase videos), animation education (e.g., teaching animations), urban tourism (e.g., travel promotion videos), and micro-dramas (e.g., short video stories).

Beyond commercial applications, Doubao also assists professional video creators and artists in saving time, sparking inspiration, and tackling complex video production tasks.
Closing Remarks
In conclusion, here's a summary of Doubao's text-to-video capabilities.
Firstly, it's a semantic master. It not only understands your instructions but also grasps their deeper meanings, ensuring every movement in the video is just right.
Secondly, it's a camera transition expert. When switching camera angles, it maintains story fluency and coherence, akin to a seamless narrative maestro.
It is also an expert in motion capture. Whether it is fast action or cool camera movements, it can capture it vividly, making you feel like you are in the real world.
It can also be a visual artist: the videos it creates are not only clear and realistic, but also have professional colors and lighting, supporting a variety of styles and sizes to enrich your visual experience.
A more apt description is that the upgrade of the Doubao video model this time has raised the aesthetic realm of domestic AI video to a higher level, making AI video more practical.
At the end of the article, I want to emphasize that the videos generated in the article are all based on the non-member version of the Doubao video generation model S 2.0. At present, the Doubao video generation model-PixelDance, which has stronger capabilities of multi-agent interaction and multi-camera switching consistency, is being rigorously tested internally and launched online, which may bring more surprises to everyone.
Doubao is a bit low-key and does great things silently.
-
![]()
Over 50% of Revenue Hinges on Yutong Optics! This Optical Equipment Manufacturer is Charging Towards an IPO
-
![]()
YOCO Optics Finalizes Industrial and Commercial Registration Update Post 160 Million Yuan Investment in Jiangfeng Biology, Securing 20% Stake to Emerge as Second-Largest Shareholder!
-
![]()
Google Market Value Plummets by $1.5 Trillion Overnight Following the Loss of Two Key Figures
-
![]()
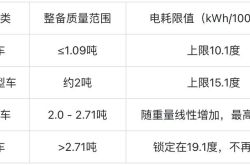
Put an End to the EV 'Weight Gain Race'! Can Your Car Still Be Driven Under the New National Standards?
-
![]()
In 2026, 'AI Upstarts' Collectively Bet on World Models
-
![]()
【OFweek Weike Cup】Phoenix Optics Officially Participates in the 2026 Optical Industry Annual Innovation Product Award
-
![]()
Ford Ditches Mach-E: Will Its Billion-Dollar Electrification Drive Have to Start All Over Again?
-
![]()
【OFweek Weike Cup】Shuangli Hepu Officially Participates in the 2026 High-Growth Enterprise Award in the Optical Industry