Fake Open Source? Open Source Large Models Are Not What You Think!
 11/01 2024
11/01 2024
 779
779
25 years ago, renowned computer programmer and flag bearer of the open source software movement, Eric S. Raymond, published the book "The Cathedral and the Bazaar," where he first introduced the concept of Open Source, advocating for software source code to be accessible, modifiable, and distributable by anyone. Since then, open source has profoundly influenced every corner of the internet industry.
As large models and GenAI rise to prominence, open source has once again become the focus of industry attention, and debates on open vs. closed source persist. However, open sourcing large models is more complex than traditional software. There are entirely different standards and contents regarding the definition, nature, openness, and strategies of open source for large models.
Therefore, the label of 'open source advocate' is not so easily worn.
"Ripples in the 'Open Source' Large Model Scene
On October 29, the prestigious Open Source Initiative (OSI) released version 1.0 of the Open Source AI Definition (OSAID), which has caused quite a stir in the industry.

According to OSAID, for an AI model to be considered 'open source,' it must provide sufficient information to allow anyone to 'substantially' rebuild the model. There are three key points for an AI large model to be considered open source under the new definition:
First, transparency of training data. Sufficient information must be provided to enable anyone to 'substantially' rebuild the model, including the source, processing, and acquisition methods of training data;
Second, complete code. The complete source code used for training and running AI must be disclosed, demonstrating the specifications for data processing and training;
Third, model parameters. This includes model weights and configurations, with corresponding access rights provided.
OSAID also outlines the usage rights that developers should enjoy when using open source AI, such as the right to use and modify the model for any purpose without obtaining permission from others.
OSI states that the new definition aims to avoid excessive marketing and misuse of the term 'open source large model' in the industry. According to this standard, almost all currently available large models marketed as open source are not worthy of the name, including prominent benchmarks like Meta's Llama and Google's Gemma.
Over the past two to three years, OSI has discovered that 'open source' in the traditional software industry is fundamentally different from that of large models, and the existing definition does not apply to the currently popular AI large models. AI large models are far more complex than traditional open source software: they not only contain code but also involve massive amounts of data, complex model architectures, and various parameters during training. The collection, organization, and annotation of these data significantly impact the model's performance and results. Traditional open source definitions cannot fully encompass these new elements, leading to insufficient applicability in the AI field.
Currently, many startups and large technology companies worldwide claim their AI model release strategies are 'open source,' as describing large models as 'open source' is perceived by developers as more accessible, lower cost, and offering more resources. However, researchers have found that many open source models are only nominally open source; they restrict what users can do with the model, and the data required for actual model training is confidential. Additionally, the computational power needed to run these models exceeds the capabilities of many developers. For instance, Meta requires platforms with over 700 million monthly active users to obtain special permission to use its Llama model.
Similarly, a report in Nature in June this year pointed out that many tech giants claim their AI models are open source but are not fully transparent. The data and training methods for these models are often not disclosed, a practice known as 'open wash,' severely hindering the reproducibility and innovation of scientific research.
Andreas Liesenfeld, an AI researcher at Radboud University in the Netherlands, and computational linguist Mark Dingemanse have also found that, although the term 'open source' is widely used, many models are at best 'open weights,' with most other aspects of system construction hidden.
For example, although Llama and Gemma claim to be open source or open, they are actually only open weights. External researchers can access and use pre-trained models but cannot inspect or customize them and do not know how the models are fine-tuned for specific tasks.
What Exactly Does 'Open Source' Large Models Open Up?
For open source software in the community, the source code is its core. By reading the source code, developers can grasp all the details of the software, enabling them to develop new features, provide testing, fix bugs, and conduct code reviews.
Developers submit their code to open source projects, which, after integration, form new versions. This is open collaboration development, the basic development model for open source software. It is not fundamentally different from the development process of ordinary software, except that developers are geographically dispersed and rely on remote collaboration platforms like GitHub and Gitee for open governance collaboration.
However, for large models, data is a more critical core asset beyond the source code. Large models are deep learning models trained on massive amounts of data using deep learning technology. They can generate and understand text based on natural language, produce outputs from input data, and complete various types of general tasks.
In terms of large model operations, there are mainly two processes: training and inference. The training process is how large models are created. The basic principle involves running specific model architectures on deep learning frameworks, inputting training datasets into the architectures, and obtaining a set of desired weights through complex calculations and multiple iterations. These weights are the trained results, also known as pre-trained models.
After deployment and with the support of deep learning frameworks, pre-trained models produce corresponding outputs based on given inputs. This process is called inference.
It should be noted that the computational power and resources required during training and inference for large models can vary significantly. The training process requires many iterations and massive GPU computational power to complete a full training cycle within a reasonable timeframe.
In contrast, the computational resources required during inference are relatively smaller, as general-type inferences can be completed on consumer GPUs or ordinary GPUs.
Currently, most open source large models available on the market only provide a set of weights, i.e., pre-trained models. If developers want to reproduce the training process of these open source large models, they need to optimize datasets and methods to train a better model, requiring datasets, training processes, and source code. However, most open source large models do not provide these contents when open sourced, making reproduction impossible even if developers have the computational power.
These open source large models, analogous to traditional software, are more like open binary packages, such as .exe files, that are closed source but free to use. They are actually 'free software' rather than 'open source software.'
The so-called 'open source' of large models actually involves three components: source code, algorithms, high computational power, and big data. Only by possessing all three can a model with outstanding performance similar to ChatGPT be created.
The source code of large models lies in the algorithms, whose core components include model structures and training methods, both of which have corresponding source codes. Obtaining the source code is just the first step; high computational power and big data are thresholds that most enterprises cannot overcome. Compared to high computational power, big data is the most difficult to obtain and the most valuable.
So, can collaboration not occur with open source large models if datasets and source codes are not provided? Not entirely.
Based on the implementation principles and technical characteristics of large models, developers can extend the capabilities of pre-trained large models through fine-tuning. By using additional datasets for further training, the model's effectiveness in specific domains can be optimized, resulting in a new derivative model.
The scale of fine-tuning data can vary but is usually much smaller than the original training dataset. Therefore, the computational cost required to produce a fine-tuned model is much lower.
As a result, in the open source large model community, some fine-tuned large models derived from mainstream pre-trained models have emerged, forming a lineage.

Are Large Models Not Truly Open Source?
From the current promotional materials of various large model vendors, most adopt an overly general or evasive approach, easily confusing the concepts of model open source and software open source, leading developers or enterprises to mistakenly believe that open source large models and open source software share the same level of openness.
Whether it's large models or software, the essence of leveraging open source advantages is to incorporate improvements from developers. However, the current so-called open source large models cannot truly enhance their effectiveness and performance through community developer participation, as open source software does. Enterprises applying open source large models also find it difficult to iterate and optimize these models, hindering their efficient application in enterprise scenarios.
There is no clear consensus in the industry on what constitutes an open source large model, similar to open source software.
Comprehensively, there are indeed similarities in concept between open sourcing large models and software, both based on the principles of openness, sharing, and collaboration, encouraging community participation in development and improvement to drive technological progress and enhance transparency.
However, there are significant differences in implementation and requirements. Software open source primarily targets applications and tools, with relatively low resource demands. In contrast, open sourcing large models involves extensive computational resources and high-quality data, potentially with more usage restrictions. Therefore, while both aim to promote innovation and technology dissemination, open sourcing large models faces more complexity, and community contribution forms differ.
There has also been a debate on open sourcing vs. closed sourcing large models in China. Baidu founder Robin Li has repeatedly emphasized the difference between the two, stating that open sourcing large models is not the same as open sourcing code: 'Open sourcing models only provides a bunch of parameters and requires additional SFT (supervised fine-tuning) and safety alignment. Even with the corresponding source code, one does not know the proportion of data used to train these parameters, making it impossible for everyone to contribute and significantly improve the model. Obtaining these things does not allow you to iterate and develop on the shoulders of giants.'
Thus, current improvements to open source large models are primarily achieved through fine-tuning, which primarily adjusts the model's output layer without involving the core architecture and parameters, unable to fundamentally change the model's capabilities and performance.
Even with 'true open source,' due to technical characteristics and training costs, the effectiveness of open collaboration in enhancing large model performance is limited.
The training process of large models requires substantial computational power, with high costs. Even if creators open source datasets and training details, ordinary developers find it difficult to afford the high costs of reproducing the training process, making it challenging to substantially improve model capabilities through openness.
Data shows that the cost of a complete model training for ChatGPT exceeds 80 million yuan. If 10 complete model trainings are conducted, the cost would reach 800 million yuan.
From an enterprise perspective, choosing a large model product or application should be based on the organization's specific needs and strategic goals.
Robin Li believes that evaluating a model involves multiple dimensions, not just focusing on various capabilities listed on benchmarks but also considering effectiveness and efficiency. As large models accelerate into commercial applications, pursuing high efficiency and low cost, the true measure should be whether the model can meet user needs and generate value in practical applications.
The application of large models is a complete solution encompassing 'technology + services.' Neglecting or insufficient consideration of any single aspect can affect an enterprise's 'cost reduction and efficiency enhancement' efforts, or even lead to negative effects like 'cost increase and efficiency decrease.' Therefore, comprehensive consideration is necessary.
Regarding the choice of large models, enterprises need not overly obsess; instead, they should focus on which large model is more user-friendly and how it aligns with their actual business needs, thereby selecting the large model platform best suited to their business scenarios and focusing on application development. So, how should enterprises make their choices?
First, calculate hardware resource costs. Some commercial large models come with corresponding toolchains, including training and inference toolchains, which can effectively reduce costs. For enterprises, the training phase can save approximately 10-20% of hardware costs, with even greater savings in the inference phase, especially for larger business scales.
Second, consider the business benefits brought by the model. Some businesses are less sensitive to accuracy rates of 90% or 95%. However, for others, like commercial advertising, a slight difference in CPM or CTR can result in millions of differences per day for advertising platforms. In such cases, enterprises with higher model effectiveness requirements are more willing to invest in better models.
Third, consider opportunity costs and labor costs. In some commercial large models, vendors adapt the model and hardware to optimal states based on enterprise business needs, allowing enterprises to directly replicate proven experiences, significantly reducing computational power, labor, and other costs during the adaptation process of large models.
Faced with the debate on open sourcing vs. closed sourcing large models and the authenticity of open source within the industry, we should not morally coerce all large models to be open source, as this involves considerable technical, resource, and security considerations, requiring a balance between openness and security, innovation, and responsibility. Like other aspects of technology, a diverse range of contribution methods can build a richer technical ecosystem.
The true era of open sourcing large models is still far off. Just as open source and proprietary software have jointly shaped today's software ecosystem, the openness or closedness of large models and the degree of openness are not entirely opposed. The coexistence and development of multiple technical routes are essential drivers for promoting continuous AI technology advancements and meeting diverse application scenario needs. Ultimately, users and the market will make choices that suit them.
From Cloud Computing to AI Large Models: A Crucial Step in Cloud Giant Ecosystem Revolution
How Can Large Models Overcome the Data Hurdle for Implementation?
Is Open Source the Future of Large Models?
How Should Developers Navigate Commercializing Their Intentionally Sabotaged Open Source Projects?
[Original by Tech Cloud Report]
When reprinting, please indicate 'Tech Cloud Report' and include a link to this article
-
![]()
Over 50% of Revenue Hinges on Yutong Optics! This Optical Equipment Manufacturer is Charging Towards an IPO
-
![]()
YOCO Optics Finalizes Industrial and Commercial Registration Update Post 160 Million Yuan Investment in Jiangfeng Biology, Securing 20% Stake to Emerge as Second-Largest Shareholder!
-
![]()
Google Market Value Plummets by $1.5 Trillion Overnight Following the Loss of Two Key Figures
-
![]()
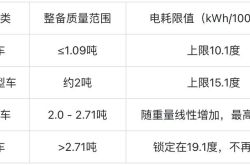
Put an End to the EV 'Weight Gain Race'! Can Your Car Still Be Driven Under the New National Standards?
-
![]()
In 2026, 'AI Upstarts' Collectively Bet on World Models
-
![]()
【OFweek Weike Cup】Phoenix Optics Officially Participates in the 2026 Optical Industry Annual Innovation Product Award
-
![]()
Ford Ditches Mach-E: Will Its Billion-Dollar Electrification Drive Have to Start All Over Again?
-
![]()
【OFweek Weike Cup】Shuangli Hepu Officially Participates in the 2026 High-Growth Enterprise Award in the Optical Industry