How Can Autonomous Driving Achieve an Effective Data Closed Loop?
 02/25 2026
02/25 2026
 512
512
The stability and safety of an autonomous driving system hinge on its capacity for continuous learning and enhancement. Such a system cannot indefinitely rely on a static program; it frequently encounters scenarios that it "does not understand" or "misjudges" during operation. If these issues and the new scenarios encountered in real-world driving are not relayed to the R&D team, it becomes challenging for them to rectify defects and bolster system capabilities.
The data closed loop is designed precisely to tackle this challenge. It involves the continuous transmission of data collected by vehicles during real-world driving or testing back to the development team. After processing, learning, validation, and redeployment, updates can be rolled out to the vehicles. As long as this cycle functions effectively, the autonomous driving system can make continuous progress.
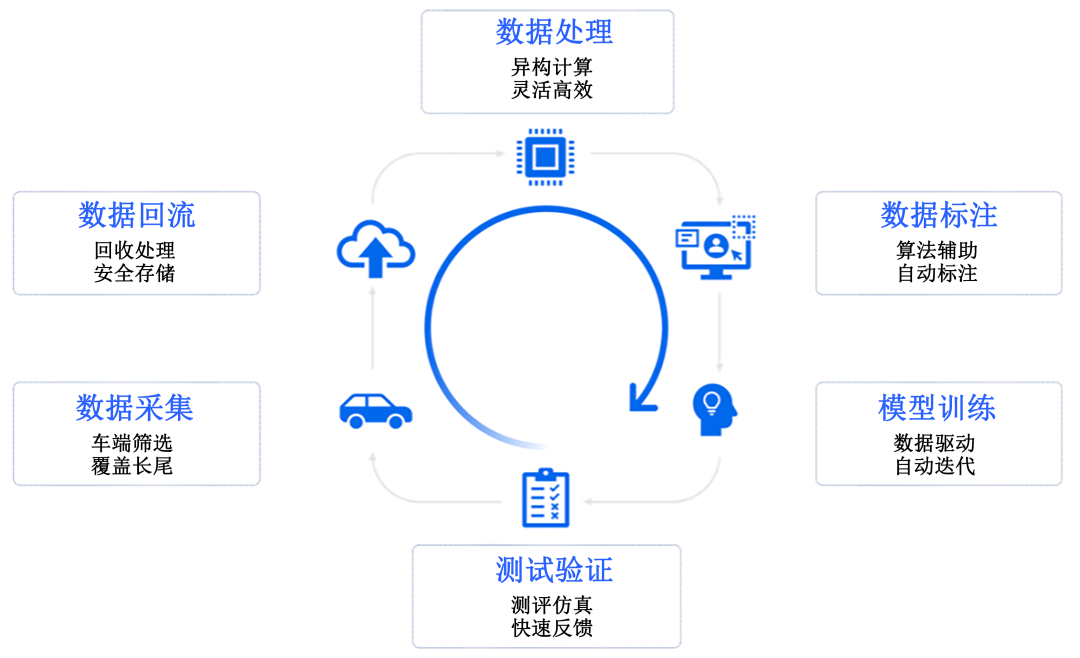
Image Source: Internet
The primary goal of the data closed loop is to facilitate the rapid identification, labeling, analysis, and model updating of new issues encountered in real-world traffic scenarios, thereby preventing the recurrence of similar problems. This mirrors the version iteration process in software development, where issues are pinpointed, feedback is gathered, backend fixes are implemented, new versions are rolled out, and the cycle repeats. However, in autonomous driving, the data closed loop system is significantly more intricate due to the involvement of massive sensor data, machine learning, and simulation testing.
Data Collection: The First Step in the Data Closed Loop
To establish an effective data closed loop, data collection is the initial step. Autonomous vehicles are outfitted with an array of sensors, including cameras, millimeter-wave radars, and LiDAR, which capture real-time information about the vehicle's surroundings. The data from these sensors is the most original and comprehensive, reflecting road conditions, obstacles, traffic signals, and the behavior of other road users. This real-time captured data lays the foundation for the entire closed-loop system.
The sources of this raw data can be categorized into two types: data collected by test vehicles during closed-course or open-road testing, and data collected by mass-produced vehicles during real-world operation. The former allows for active control of test scenarios, encompassing various predetermined test conditions; the latter captures real problems and numerous edge cases in actual traffic environments. The collected data is then transmitted to the cloud or data center for subsequent processing.
It is crucial to note that this data is not as easily organized as typical system logs. It encompasses various types of information, such as images, LiDAR point clouds, and radar signals, which are diverse and highly complex. Most of this content cannot be directly utilized for model training. Therefore, the collected data must undergo an initial screening to extract the most valuable road segments and specific error scenarios. This ensures that subsequent processing steps are not hindered by massive amounts of invalid data, allowing for a more focused optimization and learning of key issues.
Data Preprocessing and Cleaning: Essential Steps
The raw data collected cannot be directly used for model training; it must undergo preprocessing and cleaning. The purpose of this step is to eliminate interfering information from the data and extract the truly useful parts.
Preprocessing involves operations such as data format conversion, time alignment, and coordinate unification. This is because different sensors on autonomous vehicles have their own clocks and coordinate reference systems. If their data is not aligned in time and space, subsequent analysis will be chaotic. For instance, if the position of an obstacle detected by LiDAR is not synchronized in time with the image captured by the camera, it becomes difficult to ascertain whether the obstacle truly exists.
Cleaning entails filtering out data with obvious errors, missing information, or incompleteness. For example, sensors may be obstructed or interfered with during high-speed driving, resulting in unreliable data. If such data is used for training, it may cause the model to learn incorrect patterns. Therefore, data cleaning is a vital step to ensure the effectiveness of model training.
At this stage, automatic labeling technology is also employed. Automatic labeling tools can initially identify and mark the positions and types of objects in images, such as pedestrians, vehicles, and traffic signs. Subsequently, experienced engineers review and correct the automatic labeling results to ensure accuracy. The combination of "automatic labeling + manual review" significantly boosts the efficiency of the labeling process.
Training and Optimizing Models with Data
The cleaned and labeled data is then used for model training. In autonomous driving systems, most perception, prediction, and planning functions rely on machine learning models, which require large amounts of accurately labeled data to "learn" how to recognize scenarios and make correct judgments.
Training typically occurs on high-performance computing clusters in the cloud. Before training, the prepared data is categorized into perception model training data, prediction model training data, and simulation testing data, which are then combined into training and validation sets. Machine learning algorithms repeatedly adjust the internal parameters of the model to enable it to make correct judgments when encountering new data.
This training is not a one-time process but an iterative one. Whenever new data is labeled, it can be added to the training set to provide the model with more diverse training. This allows the model to continuously learn new situations and enhance its accuracy.
Some technical solutions also incorporate large models to expedite this process. Large models, with their stronger understanding capabilities, can automatically recognize complex scenarios and extract features, reducing manual involvement and enhancing training efficiency.
Simulation Testing: Validating Updates in a Virtual Environment
After model training, the model cannot be directly deployed to vehicles; it must undergo rigorous testing. While real-world road testing is necessary, it is costly and risky. Therefore, simulation testing is an indispensable part of the data closed loop.
Simulation environments can replicate various road scenarios, traffic conditions, and weather conditions. The newly trained model can be repeatedly tested in the simulation environment to verify its safety and stability under different circumstances. Scenarios such as peak-hour congestion, suddenly crossing pedestrians, and complex intersections can all be tested repeatedly in simulation.
One important role of simulation testing is to uncover edge scenarios that the model may encounter in the real world but has not yet encountered. These scenarios, due to their low probability of occurrence, are difficult to capture through real-world road testing. However, if encountered, they could lead to system failure. Simulation testing helps bridge this gap in scenario coverage.
Simulation systems can also generate new test scenarios based on existing data to supplement the deficiencies of real-world data, which is an important way to enhance training coverage and model robustness.
Vehicle-End Validation and Deployment
Models that pass both training and simulation testing can be deployed to vehicles for validation. At this stage, the vehicle operates under a wider range of real-world road conditions to observe whether the autonomous driving system's performance aligns with simulation testing results.
Vehicle-end validation still generates large amounts of data, which can be fed back to the cloud for the next cycle of collection and analysis. Through this process, the operational validation of the new model becomes input for the next iteration of the closed loop.
The most critical task at this stage is effective monitoring and anomaly detection. The system needs to record in real-time the differences between each decision, each prediction, and the actual situation. If a trend of judgment bias in specific scenarios is detected, the relevant data must be promptly extracted and used as important material for the next round of training.
Through such continuous validation and feedback, the entire autonomous driving system can gradually improve, evolving from initially operating only in simple road conditions to eventually handling complex traffic environments, adverse weather, and other real-world challenges.
Challenges in Deploying a Closed-Loop System
Building an efficient data closed loop is not as simple as merely transmitting data from vehicles to the backend. It resembles setting up an automated "learning assembly line," requiring close coordination among multiple steps and the support of corresponding tools and platforms.
Given the massive volume and diverse types of data generated in the data closed loop, high-performance storage and large-scale data processing capabilities are essential for efficiently storing, accessing, and organizing this vast information.
Automatic labeling and data processing tools are also crucial, as they determine whether raw data can be quickly and accurately converted into training samples for model learning, directly impacting the progress and quality of subsequent steps.
Simultaneously, a powerful training and simulation computing platform is indispensable. Model iterative learning relies on sufficient computational power, while simulation environments can safely and efficiently verify algorithm performance across numerous scenarios.
Additionally, a model deployment and real-time monitoring system must be established. This ensures that updated models can be smoothly applied to vehicles and continuously monitors their performance during actual operation, enabling timely issue detection and triggering a new round of optimization.
It is important to note that throughout the closed-loop process, data collection and processing must adhere to compliance and privacy protection principles. Data collected by autonomous vehicles sometimes involves personal image information or other sensitive content, which must undergo desensitization during transmission and storage to ensure personal privacy is not leaked. Moreover, various countries and regions have strict regulations on the use and cross-border transmission of autonomous driving data, which the development team must comply with.
In summary, the data closed loop requires systematic construction across the entire chain, from collection, storage, processing, training, testing, to deployment and validation, forming a highly automated and rapidly responsive operational mechanism. Only in this way can the closed loop truly function, driving the continuous evolution of the autonomous driving system.
Final Thoughts
The development of autonomous driving technology cannot advance without a data closed loop. A well-established data closed loop system enables various new situations encountered by vehicles in real-world traffic scenarios to be promptly captured, organized, learned, and used for system updates. This not only enhances system safety and stability but also accelerates overall R&D progress.
-- END --
-
![]()
Depreciation Rate on Par with Mobile Phones: Just 40% Value Retention After Three Years—Why Do Battery Electric Vehicles Lose Their Worth?
-
![]()
Clearing Bugatti Stock Worth 7 Billion: Why is Porsche 'Cutting Ties'?
-
![]()
Don’t Dismiss Huawei’s Potential in Sedans Just Because the Shangjie Hasn’t Hit It Big Yet
-
![]()
Unsold Cars in China Find Success Overseas
-
![]()
Ghosn: Only I Can Save Nissan, Shareholders Beg Me to Return
-
![]()
Expanding Automobile Consumption: It's Time to Address the High Cost of Electric Vehicle Repairs
-
![]()
Luna Ultra Entangled in 'National Subsidy Fraud' Controversy, Insta360 Pushed to the Brink by DJI
-
![]()
People have long suffered from splash ads. Will the 'temporarily disappeared' traffic behemoth make a comeback?







