From Hunyuan to Zhipu: Evaluating the Craftsmanship of Six Domestic AI Large Models in Programming
 08/14 2025
08/14 2025
 645
645
Last week, we tasked six domestic AI large models with analyzing financial reports. This week, let's delve into a more exciting and challenging topic: AI writing code.
The notion that AI will render programmers obsolete persists. Is this a fact or a fiction?
To unravel this mystery, we've designed an "AI Programmer Skills Challenge."
Don't worry if you're not a programmer; we'll compare the tests to everyday tasks to make them more relatable.
This time, we've chosen contestants proficient in programming:
DeepSeek: DeepSeek-R1
Tencent: Hunyuan-TurboS
Alibaba: Qwen3-Coder
Zhipu: GLM-4.5
Dark Side of the Moon: Kimi-K2
Baidu: ERNIE-X1-Turbo
As always, we'll engage in deep thinking and disable online search for fairness.
This "AI Programmer Skills Challenge" adopts a driving test approach, comprehensively examining the programming abilities of the contestants through four "subjects," ranging from easy to difficult.
01
Subject 1: Theoretical Knowledge Written Test (Basic Knowledge Quiz)
Before diving into coding, we must ensure the AI contestants' foundational knowledge is solid. Hence, we've curated some "common sense questions" from the programming industry.
Test Question 1: "Please use a metaphor a junior high school student can understand to explain what 'Object-Oriented Programming' (OOP) is?"
'Object-Oriented Programming' is a cornerstone of programming. The terms 'Encapsulation, Inheritance, Polymorphism' often confuse not just junior high school students but also many college and graduate students. This question assesses not whether the AI 'understands' but whether it can 'teach'.
Evaluation Results:
Each model chose distinct life scenarios to elucidate OOP's classic concepts:
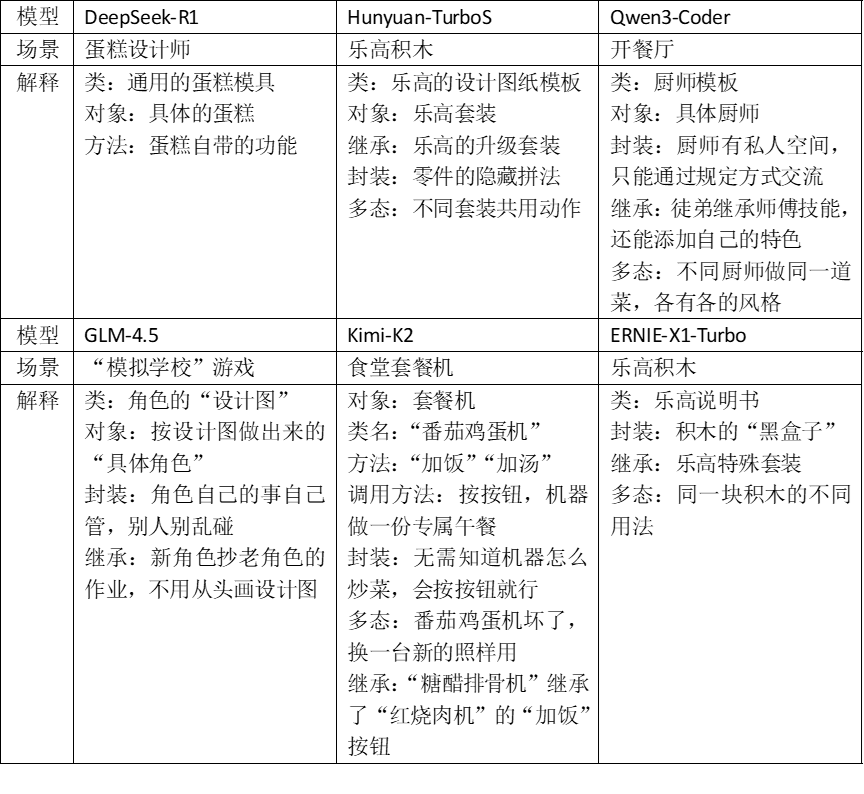
Qwen3-Coder and Kimi-K2's explanations were comprehensive, vivid, and inspiring, while DeepSeek-R1, GLM-4.5, and ERNIE-X1-Turbo omitted key concepts but remained understandable.
This round's score:

Test Question 2: "Explain what 'Recursion' is and what to pay attention to when using it?"
'Recursion' is a peculiar programming technique where a function calls itself, elegant yet perilous. Used well, it enhances readability and performance; misused, it can lead to infinite loops, crashing the program.
Evaluation Results:
Each model chose Russian nesting dolls as a metaphor and detailed recursion's constraints.
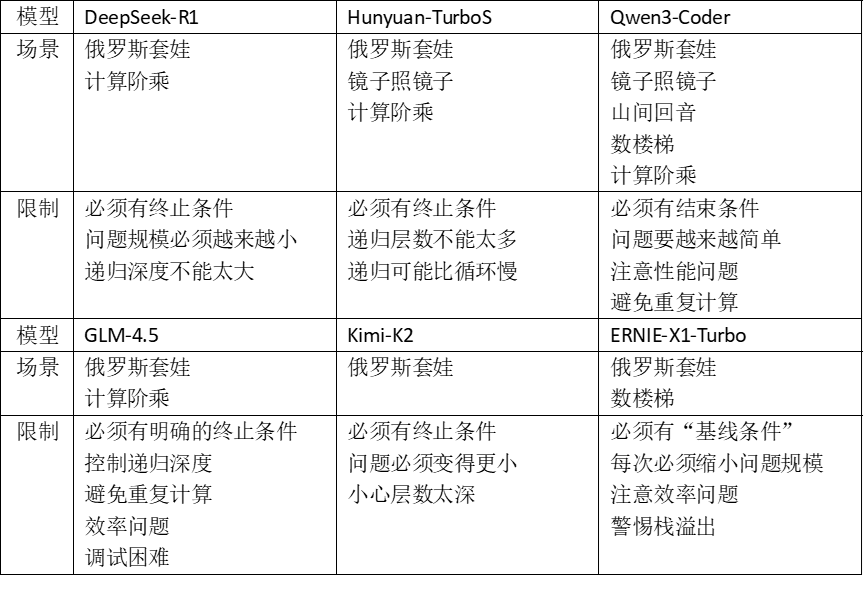
All models correctly explained the term, using similar metaphors. Qwen3-Coder and GLM-4.5 also mentioned recursion's application scenarios, making their answers more substantial. DeepSeek-R1, Hunyuan-TurboS, and ERNIE-X1-Turbo compared recursion with loops and iterations, another highlight.
This round's score:

Test Question 3: "What are the differences and connections between processes and threads? Give an example to illustrate."
A classic programmer interview question, it delves into how computers handle multiple tasks simultaneously. Clearly explaining these concepts proves the AI's robust computer knowledge system.
Evaluation Results:
Each model first provided a metaphor and then compared processes and threads from multiple angles:
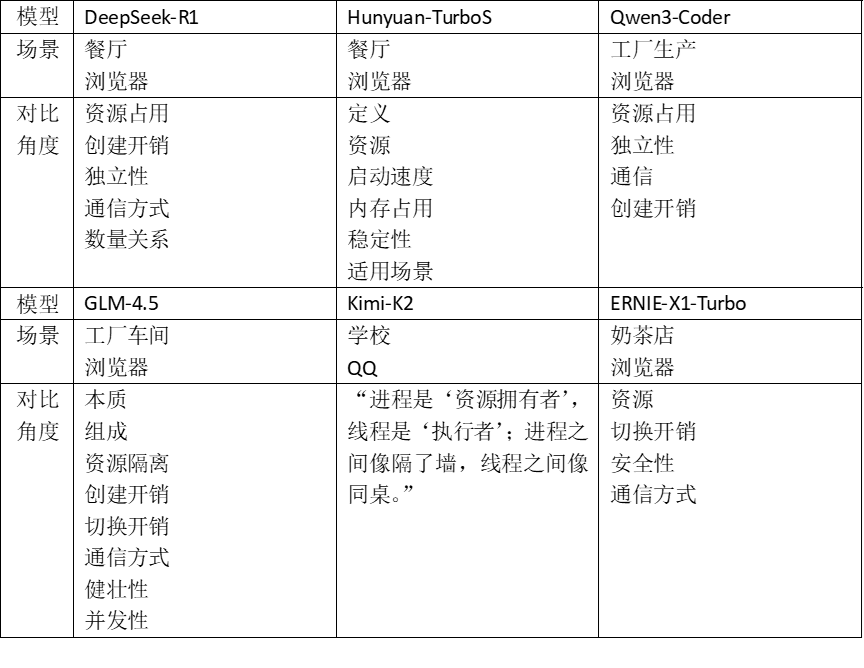
The metaphors were similar, with each model comparing processes and threads from various perspectives. GLM-4.5's answer was longer, covering simple metaphors and professional explanations, suitable for a wider audience. Kimi-K2's answer was concise but did not reveal the essence of the two concepts.
This round's score:

Subject 1 Score:
In the theoretical exam, all models demonstrated impressive strength, with profound knowledge, clear expressions, and apt metaphors. Qwen3-Coder and GLM-4.5 excelled slightly in theory, capable of serving as 'private tutors' for undergraduate computer science students.
However, in the programmer's world, code speaks louder than words.
02
Subject 2: Hands-On Practice Class (Entry-Level Programming Tasks)
After theoretical knowledge, it's time for practical tasks, akin to driving tests' 'reverse parking,' testing basic skills.
Test Question 1: "Write a classic 'FizzBuzz' problem: Print from 1 to 100, print 'Fizz' for multiples of 3, 'Buzz' for multiples of 5, 'FizzBuzz' for multiples of both, and the number otherwise."
From our perspective, this is elementary. However, it quickly assesses AI's programming logic, and we wanted to see creative answers.
Evaluation Results:
AI-generated code ran correctly, with two types of answers:
1. Reverse logic: First check multiples of 15, then 3 and 5 separately.
2. String concatenation: First check multiples of 3 and output 'Fizz', then multiples of 5 and concatenate 'Buzz'.
DeepSeek-R1, GLM-4.5, Kimi-K2, and ERNIE-X1-Turbo provided the first answer. Hunyuan-TurboS and Qwen3-Coder gave both, showcasing their intelligence.
This round's score:

Test Question 2: "Write a function to determine if an input positive integer is a 'prime number' (also called a prime)."
Introducing prime numbers is tougher than the previous question. The core idea is simple: To check if a number is prime, divide only up to its square root.
This tests AI's ability to convert mathematical concepts into code and basic algorithmic optimization awareness.
Evaluation Results:
All models provided the correct algorithm; all except Hunyuan-TurboS gave runnable code; and all except Hunyuan-TurboS and Kimi-K2 provided time complexity. Hunyuan-TurboS and GLM-4.5 suggested efficient algorithms like Miller-Rabin primality test for large numbers. Qwen3-Coder offered the Sieve of Eratosthenes for batch judgments, along with time complexity.
This round's score:

Test Question 3: "Write a function to determine if a string is a 'palindrome'."
An open-ended question with various solutions, testing AI's string handling abilities. Due to numerous solutions, we invited Gemini 2.5 as a referee.
Evaluation Results:
The 'referee' evaluated from five aspects: scheme breadth and depth, code quality and specification, explanation and teaching, unique highlights, and main deficiencies:
DeepSeek-R1:
- Scheme Breadth and Depth: High, provided space optimization
- Code Quality and Specification: High, rigorous code
- Explanation and Teaching: High, accurate complexity analysis
- Unique Highlight: Provided the most efficient space solution
- Main Deficiency: Fewer types of solutions
Hunyuan-TurboS:
- Scheme Breadth and Depth: Medium, practical solutions but lack optimal solutions
- Code Quality and Specification: High, solutions with Python characteristics
- Explanation and Teaching: Extremely high, clear layout, summary table
- Unique Highlight: Best teaching and user experience
- Main Deficiency: Lack of optimal solution for space complexity
Qwen3-Coder:
- Scheme Breadth and Depth: Extremely high, four methods, including recursion
- Code Quality and Specification: Extremely high, well-organized, including test functions
- Explanation and Teaching: High, clear comparison
- Unique Highlight: Most comprehensive technology, with both breadth and depth
- Main Deficiency: Layout is not vivid enough
GLM-4.5:
- Scheme Breadth and Depth: Medium, focused on optimal solutions
- Code Quality and Specification: Extremely high, including the use of type hints
- Explanation and Teaching: High, including execution flow examples
- Unique Highlight: Most vivid explanation of optimal solutions
- Main Deficiency: Single solution, insufficient breadth
Kimi-K2:
- Scheme Breadth and Depth: Low, only one solution
- Code Quality and Specification: High, used __name__ (Python programming style)
- Explanation and Teaching: Extremely high, the most cordial and colloquial language
- Unique Highlight: First in affinity, standard code structure
- Main Deficiency: Shallowest technical depth
ERNIE-X1-Turbo:
- Scheme Breadth and Depth: Medium, focused on interface design
- Code Quality and Specification: High but with flaws
- Explanation and Teaching: High, showing different application scenarios
- Unique Highlight: Embodies API design thinking, flexible and configurable functions
- Main Deficiency: Logical errors in test cases
This round's score:

Subject 2 Score:
In practical tasks, the 'candidates' began to differentiate. Qwen3-Coder aced all three questions, ranking first. DeepSeek-R1 and GLM-4.5 also scored high, each with unique strengths. Hunyuan-TurboS and ERNIE-X1-Turbo had minor errors, which was regrettable. The questions' difficulty is akin to freshman and sophomore computer science courses, showing AI can handle some final exams in computer science.
03
Subject 3: Life Application Questions (Solving Practical Problems)
Since Subjects 1 and 2 were academic, we'll up the ante. Subject 3 tests AI's ability to solve real-life pain points, assessing not just programming skills but understanding of human needs and problem-solving abilities.
Test Question 1: "My desktop has hundreds of files (images, documents, videos), and it's messy. Write a program to organize them into respective folders."
A typical 'automated office' need. Seeing a cluttered desktop drives many OCD sufferers crazy. This requires AI to write an OS-interacting script, completing file search, classification, folder creation, and movement.
Evaluation Results:
All models provided runnable code, realizing file classification. GLM-4.5 stood out with a simulation run feature, displaying operations without moving files. Kimi performed poorly, offering only three classification methods.
This round's score:
Test Question 2: "I want to know the outside air quality. If the PM2.5 index is high, remind me to wear a mask. Implement this function."
The difficulty rises further. The core challenge lies in linking the request with 'external data acquisition' (API call). The AI-written program must access a weather/meteorological data website and fetch the PM2.5 value. As evaluators, we focus on data accuracy and program automation.
Evaluation Result:
For this challenging question, the responses provided by the models were somewhat underwhelming.
DeepSeek-R1 fell short by failing to offer a direct method for data acquisition. The proposed solution required registration on tianqiapi.com to obtain an API key, but the provided link was inaccessible. Similarly, ERNIE-X1-Turbo also necessitated registration on HeWeather to acquire a key, and the program was limited to timed detection rather than query functionality.
Hunyuan-TurboS presented two solutions: one utilized the OpenWeatherMap API, which also required registration and key acquisition, while the other directly utilized public data from AQICN, achieving "one-click" acquisition, albeit with some inaccuracies.
Qwen3-Coder's generated code was relatively comprehensive, successfully calling an external API to enable "one-click" acquisition. However, there were errors in the queries, such as inputting Beijing but outputting data for Shanghai, and the program terminated after a single run.
GLM-4.5 and Kimi-K2's code was completely unable to fulfill the required functions nor offer feasible solutions.
Rating for This Round:

Test Question 3: "Help me create a simple password generator."
The requirements of the third question were relatively straightforward and did not involve external dependencies, and the AI's performance visibly "improved".
Therefore, we need to focus on whether the code generated by AI offers flexible and complete functionality.
Evaluation Result:
All models were capable of writing usable password generators, but there were certain differences in functionality:
DeepSeek-R1 thoughtfully incorporated a "fuzzy character avoidance" feature in the code, addressing the common issue of distinguishing between uppercase 'I' and lowercase 'l'.
Hunyuan took a different approach, using HTML to create an interactive password generator with a password strength scoring function.
Qwen3-Coder allowed users to customize password generation rules and generate multiple passwords simultaneously.
GLM-4.5 and Kimi-K2's code could only be run in the command line, which was relatively cumbersome. Additionally, the password generators written by Kimi-K2 and ERNIE-X1-Turbo did not allow users to customize password generation rules, lacking flexibility.
Rating for This Round:

Subject 3 Results:
This time, Hunyuan-TurboS led the race, occupying the top spot.
In previous evaluations, we already knew that acquiring accurate external information is a difficult task for models.
Therefore, it is not easy to bridge the "gap" of external communication and obtain meteorological data.
DeepSeek-R1 and Qwen3-Coder followed closely, performing well on the other two test questions, demonstrating reliable capabilities in a closed environment.
The other three candidates each had their own "shortcomings", performing poorly and disappointingly.
04
Subject 4: Ultimate Project Challenge (Advanced Comprehensive Ability)
This is the final stress test.
If the previous questions can be compared to "component"-level tasks, then Subject 4 is akin to letting AI "assemble a machine" by hand.
The following questions test the system design, code organization, and comprehensive application abilities of AI.
If AI can successfully pass Subject 4, it proves that it is a qualified "driver" in the field of coding.
Test Question 1: "Help me write a web-based to-do list (To-Do List)."
An entry-level frontend project.
It is not just a backend script but requires a "interface" with which users can directly interact.
This requires AI to master three "languages" simultaneously: HTML, CSS, and JavaScript.
Evaluation Result:
All models designed fully functional to-do lists.
It is worth noting that, in terms of program structure, only Qwen3-Coder separated HTML, CSS, and JS into three independent files. The other five models chose to embed CSS and JavaScript directly into the HTML file.
While Qwen3-Coder's approach may seem less convenient initially and not "out-of-the-box" ready, the "separated files" approach is the standard practice of professional web developers, offering high maintainability and readability.
This approach facilitates code reuse, team collaboration, and performance optimization, teaching a professional and sustainable development model. Despite a slight learning curve for beginners, Qwen3-Coder also provided detailed usage instructions.
Rating for This Round:

Test Question 2: "Please write a program that serves as a simple web page information extractor. Its task is to visit the homepage of Sina Finance and automatically extract and print the first 5 news headlines from the 'News' section on the homepage of the website."
One of the popular fields of AI application - web scraping.
This question is akin to letting AI send out a small robot to automatically browse web pages and accurately capture the required information from massive amounts of data.
However, the difficulty lies not in data extraction but in handling complex and variable web page structures.
Evaluation Result:
This question also led to a clear "differentiation" among the AI contestants.
Unfortunately, DeepSeek-R1, GLM-4.5, and ERNIE-X1-Turbo were unable to obtain the specified content.
In contrast, Hunyuan-TurboS and Kimi-K2's crawling abilities were significantly enhanced, able to obtain web page information, but the positions were incorrect.
Only Qwen3-Coder successfully completed the task, extracting the correct news headlines.
Rating for This Round:

Test Question 3: "Please use code to simulate the simplest library book borrowing system. It needs to have the concepts of 'books' and 'readers'."
The final test question returns to pure "system design", examining the practical application of previous "object-oriented" thinking.
In fact, this is also one of the course design topics that computer science students almost invariably experience.
Therefore, we also designed the evaluation topic as open-ended, only informing AI of the most basic requirements.
In addition to completing the system design, we must also focus on observing whether AI can add and improve system functions.
Evaluation Result:
All models provided runnable code and built library systems of varying complexity.
For the logic of borrowing and returning books, all models could easily reproduce it correctly.
However, for some requirements that were not directly proposed, it exposed the shortcomings of some models.
DeepSeek-R1, Hunyuan-TurboS, Qwen3-Coder, and GLM-4.5 all conscientiously added functions to query the library's book inventory and user borrowing list.
Kimi-K2 and ERNIE-X1-Turbo only implemented simple borrowing and returning logic.
Moreover, we asked AI to design a library "system".
As the name suggests, this system is intended to interact with users.
Here, we must commend Qwen3-Coder, the only AI among the six models that adopted an interactive approach rather than test cases.
The code it generated provided two modes of operation, allowing the use of test cases for demonstration and also enabling users to operate it themselves:

At the same time, the functions implemented were also the most complete among all AIs:

Rating for This Round:
Subject 4 Results:
Without a doubt, against the backdrop of mediocre performances by other models, Qwen3-Coder's programming ability stands out in a league of its own.
It is not only able to accurately understand people's actual needs but also capable of constructing a complete microsystem based on concepts.
The design is clear, the logic is rigorous, and the functionality is powerful, making it convincing.
05
Some Basic Conclusions
The driving test ends here.
Through the scores of each subject, it is evident that Qwen3-Coder easily topped the exam.
Whether it's in theoretical knowledge, basic programming, daily applications, or project challenges, it can be a "good helper" for writing code.
Meanwhile, during the evaluation process, we also noticed some other details:
In terms of the length and speed of generating code, Qwen3-Coder demonstrated obvious advantages.
In the Subject 4 test, its generated code was dozens of lines longer than that of other models but was able to complete the writing faster.
Conversely, Kimi-K2's code style was extremely concise and short, so it could basically only implement the literal functions.
But in general, for relatively simple requirements, the current level of AI is sufficient.
So, returning to the question we discussed earlier: Can AI replace programmers?
The answer is: Not yet, but it is already thoroughly changing the definition of the profession of "programmer".
Rather than saying that AI will replace programmers, it is more accurate to say that AI is driving the "evolution" of both itself and programmers.
Not only programmers but also students and professionals who need programming, large AI models have become indispensable "plugins".
With AI's current capabilities, solving more than 80% of the repetitive and tedious "manual labor" (writing basic code, researching materials, writing comments, etc.) is no longer a problem.
At the same time, it can build a "rough framework" of a project within minutes, freeing users from racking their brains over the program framework and allowing them to focus on "interior fine decoration" (core business logic, user experience optimization, system architecture design).
More importantly, it can greatly lower the entry barrier for programming, so that those with creative ideas but no technical expertise no longer need to train themselves to become programmers to turn their ideas into reality with the help of AI.
To be honest, during the evaluation process, when I saw AI generate a fully functional program in just a few dozen seconds, as a computer science graduate from a few years ago, I was stunned and even a bit dazed.
The automatically scrolling code on the screen was structured clearly and fully commented, and what flashed through my mind was not how fast and high-quality the AI's generation was but the scenes of pulling all-nighters for a similar course project back then.
In the past, to implement a simple library borrowing system, I might have had to flip through the "abstract bible" of C++ and jump back and forth between CSDN posts due to a database bug; to implement the simplest UI interface, I might have spent an afternoon on the user manual, doubting my life because I spent hours looking for bugs. The entire course project took a few weeks from start to finish.
Now, AI completes these tasks in the time it takes me to drink a glass of water.
Mixed feelings, a sense of loss that my youth has been "dimensionally attacked". The "difficult problems" that I stayed up late to solve are now casually brushed over by AI. At the same time, there is an indescribable melancholy and awe.
Our generation of programmers has already witnessed history. We used our hands to build walls, while future programmers will directly command robots to build skyscrapers.
Of course, this is not the end of an era but the beginning of a new one.
The value of programmers will no longer be in "building walls" but in designing the "blueprint" of the building. Our goal is to think about its structure, its aesthetics, and its value.
Of course, with AI assistants.
Therefore, there is not much anxiety, but more anticipation for the future AI era.
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
Why Is Nokia Making a Comeback in the AI Era?