''' Stanford Team Accused of Plagiarizing Chinese AI Open-Source Model
 06/11 2024
06/11 2024
 904
904
01
Recently, the Llama3-V open-source model led by the Stanford University AI team has been proven to plagiarize the domestic Tsinghua University and Mianbi Intelligence's open-source model "MiniCPM-Llama3-V 2.5," sparking heated discussions on the internet.
Coincidentally, it was a friend of Xingkong Jun, who plays with AI, who first discovered the plagiarism. Initially, they expressed indignation in the group and then shared relevant materials on Twitter, ultimately leading to the Stanford team deleting their repository on Hugging Face.
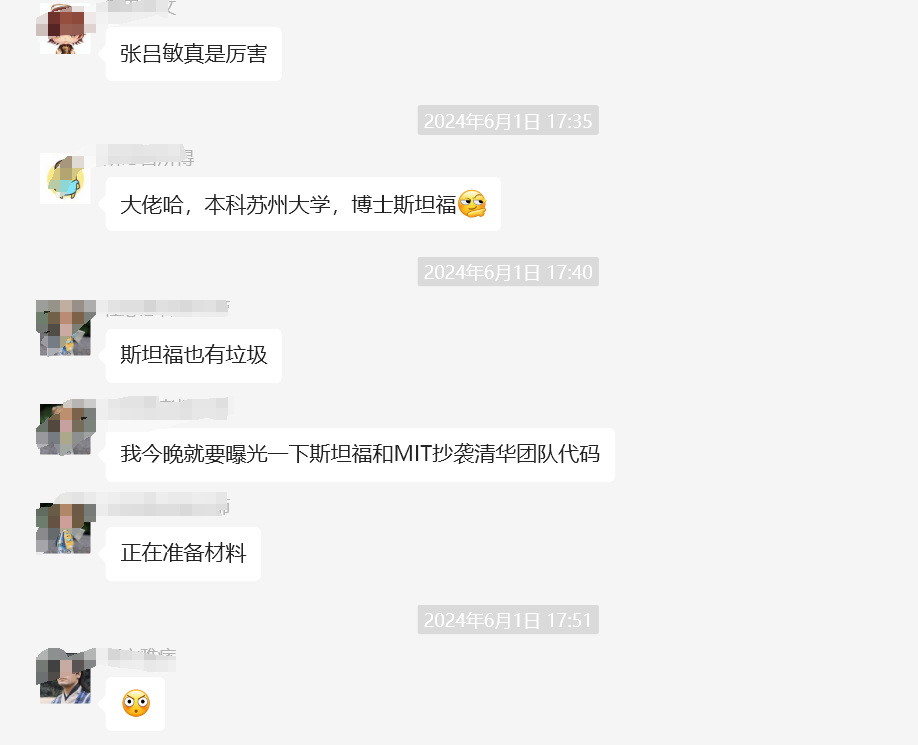
In the latest development, two authors of the Stanford Llama3-V team, Siddharth Sharma and Aksh Garg, formally apologized to the Mianbi MiniCPM team on social platforms for this academic misconduct and expressed their intention to withdraw all Llama3-V models.
On June 3rd, Li Dahai, CEO of Mianbi Intelligence, and Liu Zhiyuan, co-founder, successively issued statements responding to the plagiarism of their open-source model by the Stanford AI team, expressing "deep regret." On one hand, they were impressed that this was a way recognized by international teams, and on the other hand, they called for everyone to build an open, collaborative, and trustworthy community environment. "We hope that the team's good work will be noticed and recognized by more people, but not in this way."
In fact, this reflects the influence of Chinese AI teams from the side.
For a long time, due to reasons difficult for outsiders to understand, Chinese AI teams have been burdened with the stigma of "plagiarism" and "shell copying," with many people even saying, "As soon as foreign sources are open-sourced, China starts self-developing."
When ChatGPT was first released, domestic AI models faced vicious attacks for using foreign training sets and translating users' Chinese into English to interact with large models. Later, when Google's large model was released, people realized that almost the same issue existed, and only then did some people understand the root of the problem.
In terms of generative AI, American teams have indeed progressed faster, but this does not mean that China has nothing to offer. If you study AI-related papers in recent years, you will find a large number of Chinese teams and Chinese individuals scattered among them.
If we describe world AI as ten dou (a traditional Chinese unit of measurement), the United States accounts for eight dou, China accounts for one dou, and the rest of the world shares one dou.
Frankly speaking, such strength is not bad. China has not lagged behind in this AI revolution, not only keeping up but also leapfrogging the third place.
Within less than a year of ChatGPT's launch, China's generative AI has rapidly gained popularity. In addition to Baidu's Wenxin Yiyan, models like Kimi, Tongyi Qianwen, and ChatGLM have all achieved good results, with positive user feedback.
Both Tongyi Qianwen and ChatGLM have recently been open-sourced, and they are deeply loved by AI enthusiasts.
MiniCPM-Llama3-V 2.5 is not a well-known model and was copied by Stanford students. This incident is a bit absurd, but it also proves that shell copying open-source models is actually not feasible, as there are countless ways to verify whether a large model is self-developed.
Of course, there is no need to blame Stanford University for this incident. It is merely academic misconduct committed by some members of the team and should not be taken too seriously.
The conclusion is a belated vindication for Chinese AI large model developers: they did not rely on copying open-source shells to achieve self-development.
02
Shortly after the incident of Stanford's team plagiarizing the Chinese team's AI open-source large model, Kuaishou released the Wensheng video large model: Keling.
Judging from the experience of early beta users, Keling is almost on par with Sora, and some details are even superior.

Remarkably, Keling has already started large-scale beta testing, while Sora, which was released half a year ago, is still only in PPT form.
I have always said that Chinese AI is indeed behind the United States, but there is no generation gap, and it is firmly in second place, far ahead of third place.
When viable business models are implemented, China's AI scenarios will not be fewer than those in the United States, and may even be more.
Because China's self-media industry is highly developed, the use of AI tools to create graphics, text, and video materials has begun to gain popularity.
Friends who have obtained beta accounts and used the prompts released by Sora previously to generate videos with Keling have found the results to be astonishing.

From a technical perspective, there are currently no high technical barriers in AI technology.
Although OpenAI is indeed impressive, their first-mover advantage is minimal. ChatGPT's 3.5 version led for nearly a year, and 4.0 led for at most half a year, but now it has been caught up by various open-source large models.
Large models like China's Kimi, Tongyi Qianwen, and ChatGLM have recently achieved results that are not inferior to ChatGPT 4.0.
On the one hand, the main technical routes of large models (even closed-source) are public, and some unique training techniques can be inferred through high-intensity and wide-ranging use. Optimization based on this allows large models to "catch up." On the other hand, the talent mobility in the large model industry is very frequent, which also promotes the spread of technology.
OpenAI has a total of 770 employees, and the ChatGPT team consists of less than 100 people, with doctors, masters, and bachelors accounting for one-third each.
With the acceleration of catch-up, perhaps inadvertently, a large model will achieve a "curve overtaking" of ChatGPT.
Traditional industrial-era technologies that often lead for decades do not exist in the AI era.
Due to ByteDance and Xiaohongshu's previous flamboyance, many people have almost forgotten about Kuaishou's existence.
The biggest advantage of these short video companies is that they have a vast amount of audio and video materials, which can be conveniently used for training. I firmly believe that there is nothing profound about AI large models; it is simply a matter of effort yielding miracles.
Facts have proven this to be true. When ChatGPT 3.5 became a hit, people realized that it was possible to use 10,000 graphics cards for training, which would only be a dream for other companies. But once the model is implemented, many big players have begun scrambling to purchase graphics cards.
It is amusing that Keling quickly gained popularity on Twitter, but Kuaishou's related apps do not have a pure English version, leading many foreigners to inquire on Twitter about how to register and apply for beta access.
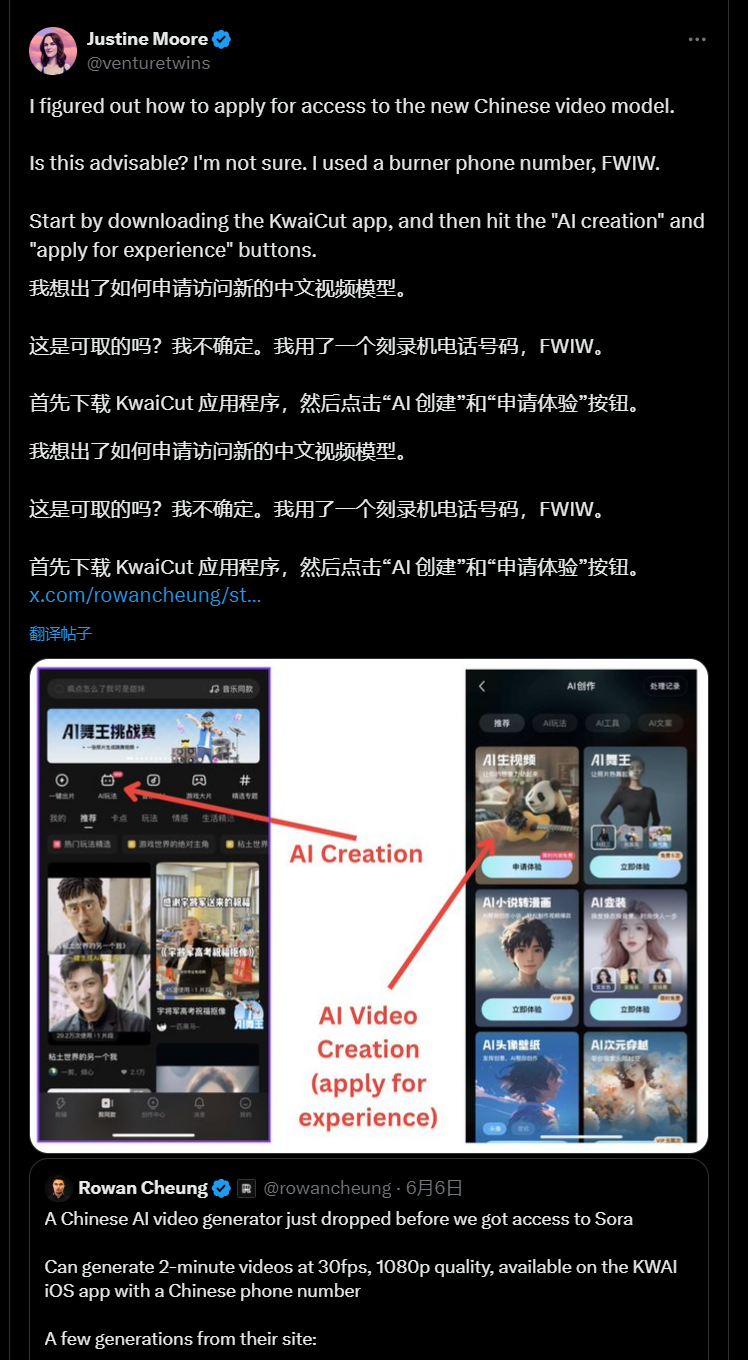
This has also allowed China's AI technology to reverse export.
Xingkong Jun's application was approved within a day. Please enjoy the videos created by Xingkong Jun using Keling:
Prompt: A giant rocket slowly taking off from a valley, with peach blossoms everywhere.
Prompt: A girl with shoulder-length hair standing under a shimmering Milky Way.
Prompt: An astronaut stepping out of a spaceship, facing a snowy planet.
Prompt: A giant panda playing the guitar by the seaside.
03
At midnight on June 7th, Alibaba Cloud Tongyi Qianwen released a technical blog post announcing the launch of Qwen2-72B, the world's most powerful open-source model, surpassing the United States' strongest open-source model, Llama3-70B.
Two hours later, Clement Delangue, the co-founder and CEO of the world's largest open-source community Hugging Face, announced that Qwen2-72B had topped the Hugging Face open-source large model ranking, Open LLM Leaderboard, achieving the highest global ranking.
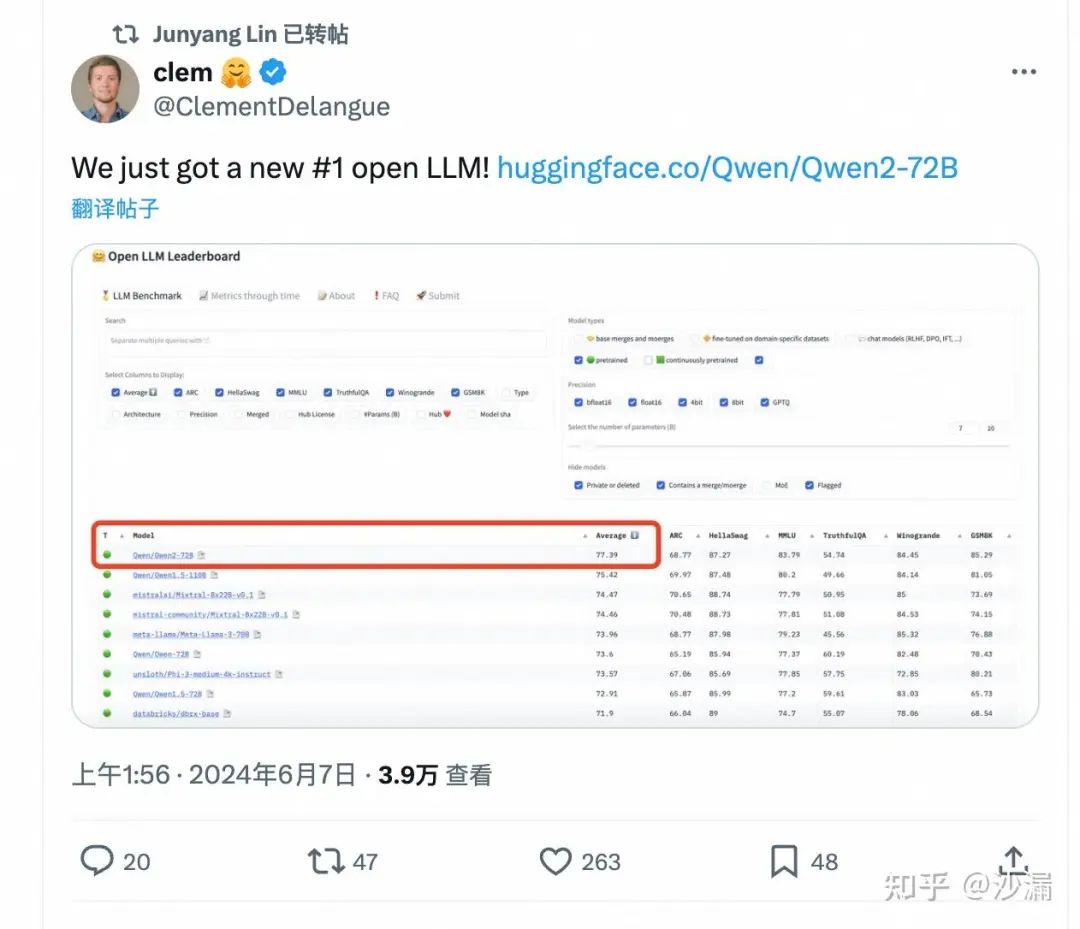
Compared to Tongyi Qianwen Qwen1.5, which was launched in February, Qwen2 achieves an intergenerational leap in overall performance. The Tongyi Qianwen Qwen2 series of models has significantly improved capabilities in areas such as code, mathematics, reasoning, instruction compliance, and multilingual understanding.
The Tongyi Qianwen team disclosed in their technical blog that the Qwen2 series includes five sizes of pre-trained and instruction fine-tuning models: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B, and Qwen2-72B, with Qwen2-57B-A14B being a Mixture of Experts (MoE) model.
All sizes of Qwen2 models utilize the GQA (Grouped Query Attention) mechanism to allow users to experience the advantages of reasoning acceleration and reduced memory usage brought by GQA.
Alibaba has a very broad layout in AI, and Xingkong Jun even believes that in the field of AI innovation, Alibaba has more promising prospects than OpenAI: Alibaba's AI research and development directly connects to business models, and OpenAI's core technologies are almost all open-source at Alibaba!
Just like navigation software, in the future, it is highly possible that OpenAI's core technologies will want to sell, only to find that Alibaba's offerings are all free.
For example, Xingkong is using the EasyPhoto open-source component (which is also funded by Alibaba) to help friends train AI painting models. The modelscope used in the code is Alibaba's Modat Community, and many of Alibaba's AI-related works have become one of the standards in the open-source community. The Modat Community is also the most active AI open-source community in China, where most open-source models can be exchanged.
Xingkong Jun, who is currently using the ChatGLM open-source model for financial data training, said that his previous work was wasted and that he would switch to Qwen2 in the future.
Trivia: Domestic users cannot directly access HuggingFace.co, but they can access it through the mirror site hf-mirror.com.
Speaking of open-source, thanks to Musk, oh no, thanks to Ma Yun for open-sourcing!
'''-
![]()
Hunan’s Wealthiest Entrepreneur Eyes Comeback with Apple’s Foldable iPhone
-
![]()
Planning to Secure 1.055 Billion Yuan to Propel AR Optics Forward! Lante Optics Receives Green Light for Private Placement on the Science and Technology Innovation Board
-
![]()
MiniMax: At the Heart of the AI Maelstrom
-
![]()
Securing 600 Million Yuan in Funding: This AR Optics Company Steps into the Limelight!
-
![]()
From a 706% Surge to a $340 Billion Market Cap Plummet: Has MiniMax's Moment Passed?
-
![]()
High Demand, Low Stock Price: Can the Emotional Companion Robot Ease UBTECH’s Worries?
-
![]()
Why Does Yin Qi, Who 'Doesn't Listen to Advice,' Insist on Making AI Agent Smartphones? | Interview with Jieyue Xingchen
-
![]()
AI-Generated Code Reveals Surprise That Thrills China