Do Large Models Truly Enhance Autonomous Driving Implementation?
 08/21 2025
08/21 2025
 663
663
With the advancement of intelligent vehicles, an array of new technologies is being integrated into automobiles. To further enhance vehicle intelligence, large model technology has begun to find its way into automotive applications. Especially as autonomous driving technology gradually becomes mainstream, the application of large models has widened significantly. So, do these large models genuinely aid autonomous driving? Is it merely a trend for automakers to adopt large models, or do they offer tangible benefits?

Advantages of Large Models in Autonomous Driving
Before diving into today's topic, let's clarify what a "large model" entails. Unlike the well-known language-based large models on mobile devices, those used in autonomous driving serve functions beyond mere chat. They refer to deep models that undergo pre-training on massive datasets, possessing robust representation and reasoning capabilities. These can be pure language models (LLMs), multimodal vision/vision-language models, or giant networks that model multimodal data such as perception, maps, and trajectories. The core strengths of large models lie in their powerful representational learning, transfer learning, and ability to adapt to tasks with minimal examples. How do these capabilities directly benefit autonomous driving scenarios?

The first notable advantage is "semantic and general representation." Traditional autonomous driving systems heavily rely on manually designed intermediate representations and specialized labels, such as various bounding boxes, lane lines, and traffic sign classifications. Through self-supervised learning, large models can jointly encode images, radar point clouds, trajectory sequences, map elements, etc., into high-dimensional semantic vectors. These vectors excel at capturing high-order relationships within scenes, such as the overall semantics of "this is a busy intersection with crowded pedestrians and occlusions," rather than local judgments based on individual pixels or points. Such representations naturally support downstream tasks (scene understanding, behavior prediction, decision-making assistance), particularly in scenarios with sparse samples or long-tail distributions, demonstrating superior transfer ability.
The second benefit is "few-shot learning and knowledge transfer." After pre-training on extensive and diverse data, large models store common-sense knowledge and driving experience in the form of distributed weights. When encountering new cities, climates, or unseen intersection designs, the model can often adapt more quickly with minimal annotation or online fine-tuning. For fleets that frequently encounter new scenarios, this significantly reduces annotation costs and model iteration cycles.
The third benefit is "multimodal reasoning and unified interface." Autonomous vehicles' understanding of the traffic environment stems from cameras, LiDAR, millimeter-wave radar, high-definition maps, V2X, etc. Large models act as a unified reasoning layer that fuses these inputs and outputs high-level semantic interpretations or candidate behavior strategies for the scene. Compared to traditional hard-coded rules or loosely coupled modular solutions, this unified reasoning can better handle information inconsistencies or local sensor failures, offering more robust alternative solutions.
Additionally, large models' value in engineering pipelines is evident. They automate annotation, generate challenging cases, synthesize training scenarios, write test cases, expand simulation scenarios, and even participate in code generation and log analysis. Delegating extensive, labor-intensive tasks to large models frees engineers from low-value work, allowing them to focus on architecture design and safety assessment.
Risks of Large Models in Autonomous Driving
Now, let's address the shortcomings. The first challenge is "real-time performance and computational power." Large models require a vast number of parameters, making it impractical to run them directly on vehicles for closed-loop control under current computational power and power consumption constraints. Even with pruning, distillation, or quantization, balancing latency and performance remains crucial. Autonomous driving demands stringent requirements for latency, determinism, and predictability. Any delay or jitter in decision-making can pose a safety hazard.

The second issue is "verifiability and interpretability." To ensure autonomous vehicles' safe operation, every action needs provable behavioral boundaries and auditable decision-making chains. Large models are essentially statistical learners, and their reasoning process does not inherently meet formal verification requirements. Integrating a black-box model into the decision-making loop complicates tasks such as safety audits, regulatory compliance, and accident attribution. Thus, it's necessary to incorporate interpretable intermediate representations, constraint layers, and redundant control fallback strategies when using large models.
Robustness and long-tail scenario handling capabilities are also concerns. While large models excel in transfer learning, they may still fail in extreme scenarios, with severe sensor distortion, or adversarial inputs. Autonomous driving risks concentrate in long-tail events, which often lack sufficient data for large models to learn during pre-training. Therefore, placing all safety hopes on the model "learning" occasional accidents is impractical.
Finally, there's the risk of "distributed responsibility and regulations." Delegating decision-making authority to a learned model raises questions about responsibility definition. Whether it's automakers, hardware and software suppliers, or service operators, determining who's responsible for model decision errors remains unclear. The legal and insurance ecosystems are still adapting. In some regions, regulators are cautious about black-box decision-making, which can hinder technology implementation.
How to Reasonably Utilize Large Models in Autonomous Driving?
So, how can large models be reasonably utilized in autonomous vehicles? A practical approach is a hybrid architecture combining "modular + large model assistance." High-frequency, rigorously validated modules handle key real-time aspects like perception (pixels to objects, geometric reconstruction), localization and mapping, and control. Large models are placed in "middle to high-level reasoning" or "offline paths" such as scene interpretation, long-term behavior prediction, complex interaction reasoning, anomaly detection, strategy suggestions, and simulation scenario generation. This leverages large models' strengths while maintaining low-latency and verifiable control paths.

For industrial-grade implementation, distillation and hierarchical deployment can be employed. First, large models in the cloud perform complex reasoning or strategy search to generate stable strategy candidates or structured instructions. These are then distilled into lightweight, real-time runnable models (or rule-based controllers) and deployed on vehicles. This transfers general knowledge to edge devices while ensuring each decision's controllability and timeliness.
In terms of training methods, large models have altered data strategies. Self-supervised learning (e.g., contrastive learning, masked modeling) learns general features from multimodal data, reducing reliance on expensive labels. Simulation-generated and synthetic data are crucial for completing long-tail scenarios but require good domain adaptation (sim2real). Behavioral-level training combines demonstration learning, offline reinforcement learning, and human expert validation to avoid dangerous real-world online trial and error. Data governance, annotation quality control, and scenario coverage assessment remain key to successfully deploying models at scale.
When evaluating and verifying, using large models does not mean testing can be lax. Instead, more rigorous scenario coverage indicators, scenario-based safety indicators, and model uncertainty quantification are required. Uncertainty estimation (e.g., confidence intervals, Bayesian approximations, or deep ensembles) can trigger strategy switches or request human intervention during runtime. Coverage testing should include long-tail scenarios like sensor failure, occlusion, severe weather, and rare actors, combined with coverage-guided adversarial testing to identify potential failure modes.
Using large models doesn't mean autonomous vehicles can be fully intelligent; redundancy and monitoring remain essential. Even if large models provide high-quality suggestions, the system should have two independent chains to verify outputs and execute simple, safe stop or degradation measures when inconsistencies arise. Runtime monitoring should include model input pipeline integrity checks, output consistency checks, and performance regression detection over time. Online logs and playback mechanisms are also crucial. After an accident, it must be possible to trace back every step of the decision-making and model input to support liability determination and model improvement.
For R&D teams, the cost and workload of implementing large models cannot be overlooked. Model training demands significant computational power and storage, and data annotation and cleaning remain major expenses. Teams can first verify large models' reasoning ability on simulations and closed-loop test benches, then perform safety sinking during road tests in closed venues and limited scenarios.

Final Thoughts
For partners specializing in large models for autonomous driving and newcomers to the field, ZhiJiaZuiQianYan offers some advice. First, mastering basic perception and geometric knowledge remains fundamental. Regardless of future model advancements, cameras, LiDAR, and radar's physical measurement characteristics and geometric constraints will always dictate the upper limit of obtainable information. Second, understanding model uncertainty is crucial. Being able to use large models and knowing when not to use them is equally important engineering capability. Third, start small and use large models in non-critical paths like assisted annotation, generating training scenarios, performing log analysis, or providing multimodal retrieval to accumulate engineering experience and demonstrate safety. Fourth, prioritize data governance and scenario coverage. A sound data strategy can enhance system safety more than simply stacking model parameters. Fifth, if leading a team, establish an interdisciplinary team comprising algorithm engineers, system engineers, functional safety engineers, and verification engineers within the same project to ensure mutual checks and balances in model development and verification.
In essence, large models do not offer a singular "universal solution" but a new toolbox that significantly enhances cognitive, generative, and reasoning abilities. They can accelerate data closed loops, improve complex scenario understanding, enhance human-computer interaction, and boost engineering process efficiency. However, they are not a shortcut to replacing all traditional modules; in safety-critical closed-loop control, black-box large models still struggle to meet verifiability and determinism requirements. A reasonable approach is to view large models as "cognitive enhancers" and "engineering amplifiers" gradually penetrating upper layers of perception, prediction, and planning, as well as data and simulation pipelines, without compromising system controllability.
-- END --
-
![]()
The Unstoppable Rise of 'Optical Progress and Copper Decline': Sunny Optical’s Strategic Vision for the Next Decade
-
![]()
AI + Going Global in the Second Half: No Intermission for Robot Vacuum Cleaners
-
![]()
The Suffering Endured in E-commerce, Walmart Doesn't Want to Repeat in AI
-
![]()
What Does the Doubling of New Energy Vehicle Exports Mean?
-
![]()
Ghosn: 'Only I Can Save Nissan'
-
![]()
Volkswagen Lays Off 100,000 Employees, The Elephant Sits Down
-
![]()
Expanding Production Capacity! Yutong Optics Acquires Approximately 1.5 Hectares of Industrial Land in Chang'an, Dongguan
-
![]()
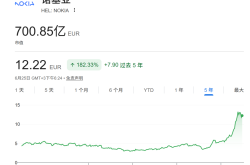
Why Is Nokia Making a Comeback in the AI Era?