Why Directly Applying VLA to Autonomous Vehicles Isn't Straightforward?
 09/23 2025
09/23 2025
 628
628
In the realm of autonomous driving, there's a recurring suggestion to integrate VLA (Vision-Language-Action Model) into autonomous vehicles. The essence of VLA is to delegate three core tasks—seeing, understanding, and decision-making—to a large model. The camera captures the scene, and the model leverages 'vision + language' to comprehend the scenario and intent, ultimately directly determining actions like steering or braking. The merits of this model are apparent. It can utilize richer semantic understanding to aid decision-making, theoretically being more adaptable and closer to the ideal of 'mimicking human-like decisions.' However, from the perspectives of practical implementation and safety, directly entrusting the entire driving process of an autonomous vehicle to VLA presents numerous real-world challenges and pitfalls.
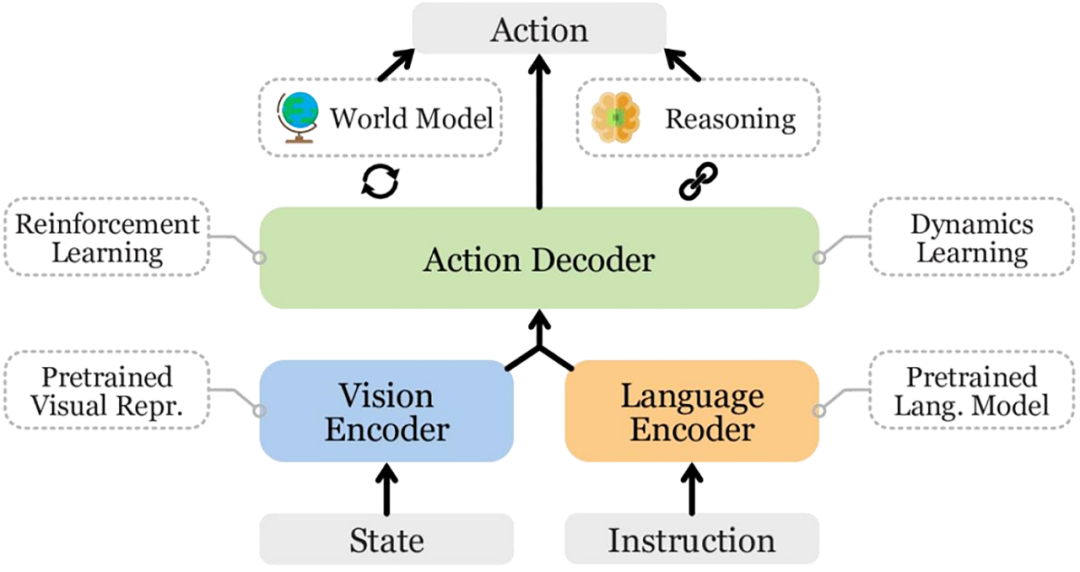
Edge Scenarios May Be Hard to Grasp
Large models learn to 'see' and 'interpret' through vast datasets, but autonomous driving demands not just 'seeing' but also executing the right actions. Common traffic scenarios are easily mastered by models, yet the truly perilous situations often arise from uncommon extremes, such as temporarily placed obstacles, unconventional construction signs, suddenly darting pedestrians, uneven or slippery road surfaces, and complex multi-vehicle interactions. Collecting all these long-tail scenarios is virtually impossible, especially when it comes to pairing them with high-quality action labels (i.e., 'what should be done' in those scenarios), which poses an even greater challenge.
Some technical solutions propose using simulation to supplement samples for edge scenarios, but a gap always exists between simulation and reality. Modeling lighting, materials, and pedestrian behavior is difficult to perfectly replicate in the real world. Sometimes, strategies that perform well in simulation may exploit loopholes within the simulation environment, and if these strategies are applied to real vehicles, they could be hazardous. Another crucial aspect of large model learning is that the labels used for training control must be physically feasible. Not all human operation examples are suitable as direct supervision signals; some seemingly 'clever' human reactions actually rely on human intuition and physical compensation (such as body adjustments during sharp turns), and direct imitation by the model could exceed the vehicle's dynamic limits.
Therefore, simply relying on amassing data and computational power cannot eliminate all potential dangers. A more feasible approach is to employ VLA to enhance semantic understanding and anomaly detection rather than entrusting it with complete control all at once. Treating it as a brain capable of providing 'high-level advice' while having a verified low-level controller handle the final execution would be much safer.
Just Because You Can Think It Doesn't Mean You Can Do It
Language models excel at reasoning and generation, but vehicles are bound by clear physical constraints. An excellent driving 'idea' may require specific steering angles, accelerations, or vehicle tilts that are simply unattainable in reality. If these physical constraints are not forcibly integrated into the output process, the model may propose infeasible or dangerous trajectories. To address such issues, either physical constraints or post-hoc corrections must be incorporated into the model's output, or the action space must be discretized so that the model only selects from a 'limited set of feasible actions.' The former approach maintains fluency but increases engineering complexity, while the latter is simpler but sacrifices naturalness and efficiency.

There's also the issue of timing. The control loop in autonomous driving has stringent frequency and delay requirements. If the model runs too slowly on the computationally limited vehicle side or if critical reasoning is offloaded to the cloud and encounters network fluctuations, decisions will be based on outdated visuals, posing driving risks. The situation where 'decision-making lags behind reality' is even more dangerous than making incorrect decisions. Many common solutions involve a 'fast thinking + slow thinking' architecture, where a small and stable model handles basic perception and closed-loop control on the vehicle side, while complex semantic reasoning and strategy optimization occur in the background or cloud, providing advice only during non-critical moments. However, this requires meticulous architectural design to ensure that the conclusions of background reasoning do not disrupt immediate control paths during critical moments.
One common method for training end-to-end systems is reinforcement learning or optimization with rewards. If the reward function is improperly designed, the model may learn strategies that score high in training or simulation but are dangerous in reality. For example, it may exploit certain rule loopholes to complete tasks quickly or rely on risky maneuvers to win in simulation. Addressing such issues requires explicitly incorporating safety constraints into the training objectives or adopting hybrid supervision (having the model learn from both expert demonstrations and safety constraints), as well as introducing more adversarial and perturbative scenarios into training. However, these measures significantly increase training costs and validation complexity.
In fact, for models, computational power and cost are also issues that must be directly addressed. Larger models entail higher costs, greater power consumption, more heat generation, and the need for stronger cooling designs, all of which directly affect vehicle costs and reliability. This necessitates manufacturers to adopt 'cost-effective and reliable' compromise solutions rather than blindly stacking model parameters.
Black Boxes Are Hard to Audit, and Liability Is Difficult to Assign
Traditional autonomous driving systems clearly separate modules such as perception, prediction, planning, and control, allowing each module to be independently validated, tested, and formally verified. End-to-end VLA can couple these processes together, improving efficiency but making it difficult to trace the source of problems when they occur. Regulatory agencies, insurance companies, and legal systems place greater trust in decision-making paths that are auditable, replayable, and provable. A black-box model that cannot explain why it made an emergency turn or failed to brake at a certain moment would be extremely disadvantageous in accident investigations and liability determinations.
This necessitates the design of logging mechanisms, preservation of key intermediate states, and traceable decision-making evidence. Using VLA to generate explanatory text (e.g., 'I recommend slowing down due to a temporary construction sign ahead') is a viable path, but such explanations must be genuinely verifiable and not just post-hoc 'excuses.' Additionally, formal safety constraints and assurance testing are more challenging in end-to-end systems, requiring new verification methodologies and more experimental data. In the short term, regulatory adaptation also poses a hurdle.
Vision Is Useful but Doesn't See Clearly in All Scenarios
The 'V' in VLA stands for 'Vision,' indicating that the camera will be the primary sensor. Cameras provide rich semantic information, but their performance significantly declines in low light, backlight, fog, rain, snow, or when obstructed. Radar and lidar have advantages in range finding and penetration but provide information that is not 'semantically friendly,' offering less intuitive explanations for 'who this is' or 'what this sign means' compared to vision. Integrating the semantic understanding of vision with the physical measurements of radar/lidar is technically complex but highly necessary.

Furthermore, the same visual targets may look significantly different in various cities or countries, with variations in standard traffic signs, road materials, and vehicle styles. Model adaptation across domains requires extensive localized data and meticulous fine-tuning; otherwise, the model may perform poorly in new environments, as seen in the early days of Tesla's FSD in China. In short, making a large model capable of 'driving anywhere in the world' is not yet realistic at this stage.
How to Safely Return Control to Humans?
One of the greatest advantages of VLA is its ability to interact with humans using natural language, which is crucial for user experience. However, natural language is highly ambiguous and prone to misunderstandings. Users may provide contradictory or incomplete instructions, and the system must balance understanding intent with adhering to safety constraints. A more practical concern is how to safely return control to humans when the system encounters edge scenarios. The transition from a passive passenger role to active control requires time and attention shifting, and if this process is poorly designed, it increases risk. Therefore, clear trigger conditions for taking over control, sufficient time windows, and clear prompting methods are necessary, while minimizing reliance on users' immediate high-complexity decision-making in design.
For consumers, trust in autonomous vehicles is also crucial. A single dangerous maneuver could erode user confidence in the system. To build trust, the system must consistently perform reliably and explain its actions. VLA has a natural advantage in explanatory output, but the explanations must be accurate, verifiable, and easy to understand.
Pragmatic Compromise Strategies for Implementation
Given the challenges that VLA models must face, the most pragmatic approach at this stage is a gradual and hybrid implementation. Use VLA for functions that are less sensitive to real-time performance but require high semantic capabilities, such as semantic understanding, anomaly detection, scenario annotation, and human-machine interaction, making it an 'intelligent assistant.' For critical high-frequency control, rely on verified low-level controllers. Another approach is to treat VLA as slow thinking: performing long-term strategy optimization, driving style learning, and complex scenario analysis in the background, then delivering constrained conclusions in an explainable and constrained manner to the vehicle-side control system.
For commercialized models, fallback mechanisms, logging, and auditable modules must also be designed and incorporated into the acceptance criteria for each version. Data collection strategies should prioritize covering long-tail scenarios that affect safety, and simulation and real-world testing should be combined to provide a verification system capable of generating quantifiable safety evidence rather than just performance curves.
-- END --
-
![]()
Enflame Tech's IPO Journey: Navigating Over 5.9 Billion Yuan in Losses and Soaring Debt in Q1 This Year
-
![]()
Trillion-Yuan Giant Li Shufu 'Streamlines': Could Levc Be the Casualty?
-
![]()
AI Competes for Electricity and Generates Power in the Gobi Desert
-
![]()
The First Batch of Victims of the AI Bubble: Programmers
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'






