Ontology-Agnostic: A Generalist’s 270,000 Hours of Data Collection Effort to Revolutionize Real-World Robot Training
 11/14 2025
11/14 2025
 596
596

The pivotal turning point in the data competition no longer hinges on the route of data solutions, but rather on whether to revert to the "first principles" of data collection: striving for reusable, scalable, and evolvable data streams. Traditional teleoperation models, which are overly focused on single-robot systems and entail costly labeling processes, not only struggle to keep pace with the data deluge required by the Scaling Law but also fundamentally deviate from the core logic of intelligent generalization.
Editor: Di Xintong
On November 4, 2025, Generalist AI, a Silicon Valley-based robotics company, unveiled a groundbreaking achievement: its GEN-0 embodied foundation model, trained on a staggering 270,000 hours of human operation video data, became the first to empirically validate the existence of the Scaling Law in robotics. This milestone has been heralded as the "ChatGPT Moment" for embodied intelligence.

Image Source: Generalist
What does 270,000 hours signify?
This data volume far surpasses all publicly available datasets for embodied robots and continues to grow at a rate of 10,000 hours per week. In stark contrast, the once-celebrated real-world teleoperation data collection model has encountered an insurmountable efficiency bottleneck, with its sluggish accumulation rate failing to meet the exponential data demands dictated by the Scaling Law.
The collection of real-world teleoperation data is inherently constrained by the physical world, following a linear accumulation pattern. Its typical model involves establishing offline data factories around specific robot hardware, where operators remotely control real robots for task demonstrations. However, several inherent characteristics of this model hinder its ability to keep pace with the Scaling Law:
The conflict between linear growth and exponential demand: The Scaling Law reveals that model performance improves in a power-law manner with increasing data volume, necessitating a continuous exponential expansion of data. Yet, real-world teleoperation data collection heavily relies on "manpower stacking" and real-machine operation, resulting in linear growth. Each data point incurs real hardware wear, physical motion time, and labor costs. Even with hundreds of collectors, the annual data output often remains at the ten-thousand-hour level, far from the "data deluge" required by the Scaling Law.
The "anchoring effect" of physical hardware: The complex deployment, debugging, and maintenance processes of real robots render the data collection system rigid and cumbersome, preventing flexible and rapid large-scale expansion. Data accumulation speed is firmly locked by the capabilities and availability of physical hardware. An industry practitioner admitted, "The data production ceiling of our physical factory is clearly visible. This model cannot support our journey toward scaled models."
Investing heavily in data collection ultimately yields only million-level datasets. "Even if we open-source the dataset we poured our hearts into, it would be a drop in the bucket for the industry's predicament," an embodied intelligence practitioner told the Embodied AI Research Community.
Thus, while real-world teleoperation data offers higher quality, we must still seek a path to address data scalability. While awaiting the unlocking of scale through real-machine data, the Generalist approach represents an alternative solution.
Indeed, there is no right or wrong technical route; what matters is whether the development path aligns with the critical divide of the AI Scaling Law. Yet, a seemingly unsolvable question arises: How do we break through the scalability bottleneck in data collection?
How to solve this problem?
To address this issue, we must first ask: What do robots need?
The first principles of solving the problem must revert to the "language" of embodied robots. The industry's core mission is not to blindly expand market scale or pursue superficial "growth" but to attentively listen to the "real needs" of embodied robots: What scenario soil, technical support, and data nutrients do they require to truly transition from "technical exhibits" to industrial tools?
The value realization of embodied robots hinges on the deep logic of "being used," meaning scenario applications must simultaneously satisfy three demands: necessity, sustainability, and economies of scale. These three factors form the underlying support for industrial adoption: necessity is the premise for scenario existence, addressing unmet core pain points; sustainability determines value longevity, avoiding short-term gimmicky applications; and economies of scale are crucial for industrial scalability, supporting the positive cycle of technological iteration and commercial closure.
The frequent performance and exhibition scenarios in the current industry are essentially "scenario slices" in the early commercialization stage. While these applications visually demonstrate technological progress and attract market attention, they are far from a complete picture of industrial adoption. The true direction of embodied robot adoption lies in becoming "collaborative partners" for human labor:
On one hand, freeing humans from repetitive and low-value tasks; on the other, undertaking high-risk and high-load operational scenarios. Ultimately, they deeply integrate into core industrial scenarios such as factory production, commercial services, and specialized operations, achieving leapfrog improvements in labor efficiency and upgrades in production modes.
The adoption in core industrial scenarios cannot be supported by performance modes that rely on preset programs to complete standardized actions on stage. It requires embodied robots to break free from the shackles of "action replication" and deeply understand the intrinsic mechanisms and dynamic trajectories of the physical world. This includes core challenges such as real-time adaptation to environmental variables, precise perception of object properties, and error tolerance boundaries in task execution.
In other words, embodied robots must not only "know how to do" but also "understand why to do": clarifying the standards for "doing things right" in different scenarios, understanding the logical connections behind actions, rather than mechanically executing preset instructions.
This "understanding" capability essentially involves the systematic disassembly, reproduction, and optimization of human behavioral patterns. Compared to macroscopic movements like limb swings, the core difficulties in long-term industrial scenarios lie in fine-grained interactive capabilities such as tactile feedback, force control precision, and environmental perception.
"AI Godmother" Li Feifei profoundly analyzed this challenge in her latest manifesto on spatial intelligence. She pointed out that spatial intelligence plays a fundamental role in human interaction with the physical world—we rely on it daily to perform seemingly mundane actions: judging position by imagining the shrinking distance between the car's front and the curb while parking, catching a key thrown from across the room, or pouring coffee into a cup half-asleep without looking.

Image Source: A16Z Account Screenshot
However, enabling robots to master this capability poses severe challenges. Li Feifei explicitly stated, "A core challenge in developing these robots is the lack of training data suitable for various embodied forms."
This means robots need to acquire more refined physical interaction data: How to handle keyboard rebound when typing? How much force is needed to open a mineral water bottle that deforms slightly as it is not a purely rigid body? Sufficient and high-quality refined data are the "nutrients" for embodied robots to perform tasks precisely. This tacit human knowledge has become a critical pain point restricting their large-scale adoption.
Without a complete data feedback loop, their interactive execution easily spirals into an out-of-control state, which is the root cause of many "trial-and-error cases" in the industry. The "black history" of embodied robots circulating on social media essentially reflects the direct consequences of lacking refined capabilities: excessive force due to the inability to precisely control different materials and tightness levels when twisting bottle caps, accidentally knocking over entire rows of blocks due to inaccurate perception of object spatial positions and dynamic collisions during block stacking, and part damage or misassembly due to the inability to process tactile feedback for fine components during industrial assembly.
These seemingly trivial mistakes precisely expose the industry's core weakness: the lack of refined capabilities prevents embodied robots from handling the complexity and uncertainty of real-world scenarios. The root cause of this capability gap lies in the absence of training data that simultaneously satisfies physical authenticity and scalability requirements. When the industry is trapped by this capability deficiency, any superficial growth in orders or shipments cannot translate into tangible large-scale adoption. The true inflection point for the industry will only arrive after achieving fundamental breakthroughs in data supply for core capability cultivation.
Real Machines Are Not a Panacea
Scalable Data Meets the Scaling Law
After identifying refined interactive capabilities as the core bottleneck for embodied robot adoption, we must further examine the data system structure supporting these capabilities. The industry has long recognized a rating standard known as the "data pyramid."
This pyramid consists of three layers: the base layer comprises internet-scale public data and human operation video data, the middle layer consists of synthetic simulation data, and the apex holds the highest value density of real-world teleoperation data.
Currently, the data that truly enables embodied robots to deeply interact with the physical world and perform work tasks mainly relies on real-world teleoperation data and physics-parameterized synthetic simulation data from the middle layers of the pyramid.
For real-world teleoperation data, it is obtained through testing embodied robots in real industrial scenarios, covering refined data such as tactile feedback, force control parameters, and environmental interaction dynamics. In short, real-world teleoperation data serves as a "one-on-one handholding" guide for embodied robots, with data annotation conducted in remote operation collection fields involving hundreds of operators around a single robot form. It achieves high success rates in individual work tasks, with each motion trajectory bearing human imprints.
The core value of real-world teleoperation data lies in its high-fidelity recording of the real physical world. Complex physical interactions such as contact dynamics, friction changes, object deformations, and force feedback in real environments are fully captured in real-world teleoperation data. These physical details from the real world—especially nonlinear dynamic parameters like contact and friction—provide robots with the most direct and authentic physical world interaction experience, which is the fundamental reason real-world teleoperation data is considered the "pyramid apex."
However, precisely due to its collection methods, real-world teleoperation data suffers from several pain points.
Currently, embodied robot forms in the industry have not converged. Even robots of the same height may have different arm lengths, leading to variations in motion trajectories. This makes data collection difficult to deploy across different forms. When robot forms iterate or customer demands change, previously collected data assets become difficult to reuse, forming a "selling bodies"-driven data collection model rather than a "data-driven" scalability model.
Secondly, data collection often consumes significant manpower and material resources, with few enterprises able to bear the financial pressure. Most data collectors are part-time workers, and even entire scenario data collections are outsourced to third-party companies, which to some extent affects data collection quality.
Thus, numerous objective factors make real-world teleoperation data difficult to align with the Scaling Law, which states that model performance predictably improves with increasing data volume and computational power—the primary solution for embodied robot data.
Generalist AI's breakthrough precisely validates the possibility of scalable data. Generalist's released GEN-0 embodied foundation model used 270,000 hours of human operation video data to become the first to validate the existence of the Scaling Law in robotics. More critically, Generalist adopted the UMI (Universal Manipulation Interface) solution, decoupling data collection devices from robot forms, enabling flexible deployment across thousands of households, warehouses, and workplaces globally, achieving truly scalable data collection.
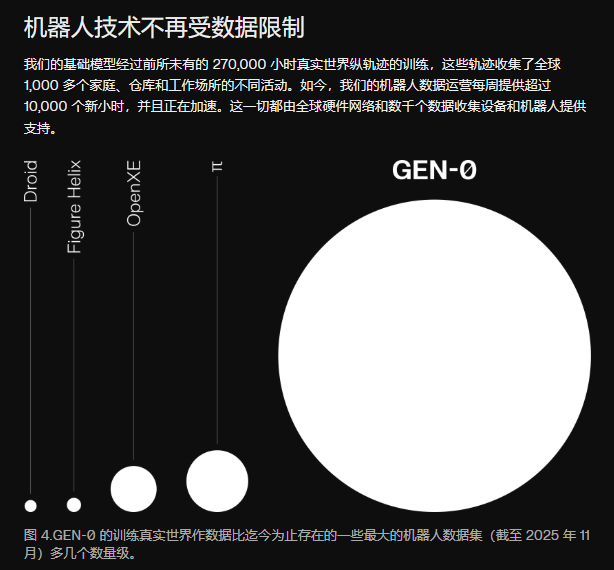
Image Source: Generalist
On another path to data scalability, synthetic simulation data also demonstrates the potential to align with the Scaling Law while offering greater economic efficiency. The same set of simulated scenario assets can be adapted to train robots of different forms without rebuilding environments for each form.
More critically, simulated data can rapidly generate massive and diverse training data in virtual environments, offering unique advantages in cost control and deployment flexibility. For the embodied intelligence field, which has almost no pre-existing datasets—lacking millions of robots continuously collecting data in factories, workshops, and households—this massive data gap precisely requires scalable and cost-controllable solutions like synthetic simulation data to fill.
On one hand, synthetic simulation data addresses the pain points of data scarcity and difficulty in scaling; on the other, it significantly reduces the cost of data asset accumulation through simulation. Together, these factors open the door for synthetic simulation data to empower embodied robots with massive data for application.
More crucially, synthetic simulation data precisely meets the refined demands for data and boasts robust generalization capabilities. Simulated environments can precisely replicate refined parameters that are challenging to capture during real-machine testing, such as tactile feedback and force control thresholds. Additionally, by adjusting scenario variables (e.g., object materials, environmental lighting, task workflows), these environments can generate scenario-generalized data, enabling robot algorithms to adapt to a wider array of real-world scenarios.
The commercial value of synthetic simulation data has been substantiated through practical cases. Galaxy General has remained steadfast in its commitment to simulation technology as a core research path, successfully launching the 'Galaxy Space Capsule' and achieving widespread adoption across the nation. The company's deep interaction with every guest and tangible industrial outcomes underscore the immense potential of simulation routes in commercial translation. This adoption is not a mere coincidence but rather the inevitable outcome of aligning the advantages of simulation data with industrial demands. The massive data amassed through simulation facilitates more stable and precise robot execution in real-world scenarios, paving the way for commercial scalability.
From the perspective of industrial development patterns, both Generalist's validation of the Scaling Law using 270,000 hours of human operation video data and the scalability potential demonstrated by synthetic simulation data converge on a core proposition: how to efficiently acquire massive and high-quality training data.
The industry should adopt an objective and prudent stance, reverting to the core logic of 'demand-driven' approaches. Achieving data scalability has become paramount. Enterprises that continue to construct remote operation collection fields centered around single robot forms are essentially repackaging 'selling bodies' as data collection businesses, with their data struggling to gain a competitive edge in the Scaling Law competition.
Simulation as a Pathway: The Co-Evolution of Physical Authenticity and Scalability Efficiency
Generalist's utilization of human operation video data to validate the Scaling Law in robotics shares an underlying data logic with synthetic simulation data—both aim to transcend the physical constraints of data collection and achieve high reusability and scalability efficiency. The distinction lies in Generalist's achievement of cross-form data collection in the real world through the UMI solution, whereas synthetic simulation data constructs data pipelines within virtual environments.
It is noteworthy that synthetic simulation data is demonstrating scalability potential on par with, if not surpassing, that of human-operated video data. In her article titled 'From Language to World: Spatial Intelligence as the Next Frontier of AI,' published three days ago, 'Godmother of AI' Fei-Fei Li highlighted that robots have long been a dream in the field of embodied intelligence, and World Models will be pivotal in realizing this dream. She specifically remarked, 'I would not underestimate the power of high-quality synthetic data...they complement internet-scale data in crucial steps of the training process.'
Recently, Fei-Fei Li and NVIDIA AI scientist Jim Fan engaged in a profound discussion on simulation and World Models during an NVIDIA Omniverse live stream. Coincidentally, in the upcoming Omniverse live stream, Madison Huang, Senior Director of Omniverse & Physical AI Product Marketing, and Dr. Chen Xie, Founder and CEO of Intelligen Wheel, will also engage in a deep dialogue on how synthetic simulation data can bridge the Sim-to-Real gap, further underscoring the growing prominence of simulation approaches in mainstream technology routes.
Image source: Live stream screenshot
During the live stream, Chen Xie stated, 'We have now entered a critical stage in data development. With simulation technology and simulation assets, multiple breakthroughs can be achieved in the field of robotics.' Behind this judgment lies Intelligen Wheel's systematic layout in the synthetic simulation data system—ranging from highly physically realistic simulation assets to standardized and industrialized data production processes, ultimately forming a reusable toolchain and an open ecosystem.
At the technical implementation level, Intelligen Wheel showcased its cable simulation solution, co-developed with NVIDIA, capable of handling the dual physical properties of 'deformable bodies + rigid bodies,' providing high-fidelity data for robots performing complex tasks such as manipulating cables and hoses. Madison Huang pointed out, 'Cable manipulation is the 'Holy Grail' problem in the field of robotics.' In NVIDIA's production environment, a single NVL72 rack requires the installation of 2 miles of copper cables, posing extremely high demands on robots' force control and tactile feedback capabilities.

Image source: Live stream screenshot
To ensure the effectiveness of synthetic simulation data, Intelligen Wheel has established a comprehensive benchmarking process: from physical property calibration and remote operation verification to reinforcement learning stress testing, and comparing physical parameter curves between simulation and the real world to ensure consistent data trends. Chen Xie emphasized that the goal of simulation is not to pursue a 'digital twin' that is entirely consistent with reality but to generate diverse and representative 'digital cousins' to cover the data distribution in real-world scenarios.
In terms of scalability, Intelligen Wheel rapidly transforms existing digital assets into simulation-ready assets through standardized processes. For instance, the conversion time for a refrigerator model can be shortened to approximately 20 minutes. Meanwhile, it deeply optimizes simulation assets to support running hundreds or thousands of environments in parallel on a single GPU, providing large-scale, low-cost training conditions for reinforcement learning.
In architectural design, Intelligen Wheel constructs a reusable toolchain layer based on a simulation engine as the foundation—including modules such as generalized learning and reinforcement learning, all of which have been productized. On this basis, the adaptation layer is customized according to different clients' sensor and annotation requirements, enabling rapid responses to multi-scenario demands.
To expand the boundaries of data generation capabilities, Intelligen Wheel and NVIDIA jointly promote the development of the Isaac Lab Arena open-source framework for benchmarking, data collection, and large-scale reinforcement learning, integrating World Models such as Cosmos to enhance the diversity and complexity of synthetic data. This closed loop of 'simulation-assets-toolchain-ecosystem' lays the foundation for its scalable client services.
Currently, Intelligen Wheel's clients, in addition to NVIDIA, include enterprises and institutions such as DeepMind, Stanford, Genesis AI, Figure, 1X, Yinhe, Zhiyuan, Alibaba, ByteDance, and others, gradually establishing technical credibility in the industry. Madison Huang evaluated during the live stream that collaboration with these top-tier teams 'itself proves Intelligen Wheel's foresight in popularizing simulation assets and synthetic data.'
Fei-Fei Li emphasized in her spatial intelligence manifesto that spatial intelligence requires handling the complex coordination among 'semantics, geometry, dynamics, and physics,' a difficulty far exceeding the one-dimensional sequence modeling of language models. Synthetic simulation data is precisely the key path to addressing this challenge—it not only provides data but also constructs a controllable and scalable physical learning environment.
Intelligen Wheel's practice demonstrates that simulation data systems are gradually becoming the infrastructure connecting the virtual and real worlds, supporting robots' transition from 'perception' to 'operation.' It is reported that Intelligen Wheel has achieved revenue exceeding 100 million yuan, also validating from a commercial perspective that the scalable value of synthetic simulation data is being recognized by the market.
Conclusion
Generalist validated the Scaling Law in the field of robotics with 270,000 hours of human-operated video data, and its UMI solution further points out a practical path for data scalability. While most companies are still trapped in building teleoperation factories for single robotic bodies, the fact that Generalist secured $140 million in funding based on human-operated videos or that Intelligen Wheel achieved revenue exceeding 100 million yuan with synthetic simulation data proves that the door to scalability has long been open to players capable of breaking through data bottlenecks.
The key watershed in this competition is no longer a debate over data solution routes but rather lies in reverting to the 'first principles' of data collection: pursuing reusable, scalable, and evolvable data streams. Traditional teleoperation models that cling to single robotic bodies and high-cost annotation not only struggle to support the data deluge required by the Scaling Law but also fundamentally deviate from the basic logic of intelligent generalization.
Generalist's breakthrough has rewritten the data rules of the embodied intelligence era: breaking free from robotic body dependence and establishing reusable and scalable data flywheels is the key to embracing the Scaling Law era.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






