New Divisions in AI Cloud: The Coexistence of Chips and Cloud Services
 11/16 2025
11/16 2025
 499
499

In the first half of 2025, China witnessed the awarding of 1,810 large-scale model projects, with a cumulative value surpassing 6.4 billion yuan. This figure not only eclipses the total for the entire year of 2024 but also underscores the substantial investments flowing into core industries such as finance, energy, government services, and manufacturing. AI has seamlessly integrated into the production system, becoming an indispensable component.
Demand has evolved, and standards have become more stringent. This year, Zhejiang's government cloud tender explicitly mandated '24/7 security operation services,' while China Merchants Bank emphasized that cloud platform availability must reach an impressive 99.999%. Customers are no longer content with merely renting a few GPU cards; instead, they seek a reliable and sustainably deliverable AI computing power system.
According to IDC data, the Chinese AI public cloud services market experienced a robust 55.3% year-on-year growth in 2024. However, the driving force has shifted from a 'dual-wheel' model of training and inference to a surge in inference demand. As AI transforms into a production factor, the metric for evaluating a cloud provider has shifted from peak computing power to the ability to maintain stable AI operations in complex environments.
Achieving this requires two fundamental pillars:
1. Self-developed AI chips
2. Deep synergy between chips and systems.
01
The foundation of AI cloud transcends mere 'GPU rental'
A common misconception is that cloud providers can offer AI computing power services simply by purchasing GPUs and installing them in cabinets. This represents a classic 'GPU rental mindset,' treating AI cloud as a hardware leasing business. However, reality has long surpassed this simplistic model. Relying solely on procuring GPUs from NVIDIA, inserting them into servers, and labeling them as 'AI cloud' for rental is no longer viable.
Firstly, costs are unsustainable. A Blackwell B200 GPU is priced between $30,000 and $40,000, while an H100 costs $20,000. In ultra-large-scale AI clusters, GPU costs account for nearly half of the total investment. According to NVIDIA's latest earnings report, cloud providers contribute 50% of its data center revenue. This indicates that the world's leading cloud service providers are heavily reliant on a single supplier for their AI expenditures.
Secondly, even with financial resources, procurement may not be feasible. Under U.S. export restrictions, domestic providers face significant challenges, while overseas cloud providers are constrained by TSMC's tight CoWoS packaging capacity.
At TSMC's recent sports meet, NVIDIA CEO Jensen Huang directly stated, 'Without TSMC, there would be no NVIDIA!' This was, in fact, an effort to secure TSMC's capacity. More subtly, NVIDIA itself has ventured into the cloud business—its DGX Cloud Lepton platform now directly rents GPUs to developers, mirroring AWS's model.
Thirdly, customers demand more than just computing power; they require efficient AI capabilities. Training large models is not a simple 'plug-and-play' task but necessitates complex engineering involving tens of thousands of GPUs working in synergy, low-latency interconnection, and high-utilization scheduling.
If cloud providers merely 'procure and integrate' without intervening at the chip architecture, communication protocol, and compiler optimization levels, even the largest clusters will only deliver 'theoretical computing power.'
Why are chips so critical for cloud providers?
Because chips, as the 'heart' of AI cloud, directly determine the quality and cost of computing power supply. This explains why top cloud providers are developing their own chips. General-purpose GPUs cannot sustain long-term computing power demands in the AI era; specialization, customization, and vertical integration are inevitable.
02
The future of cloud: Path selection
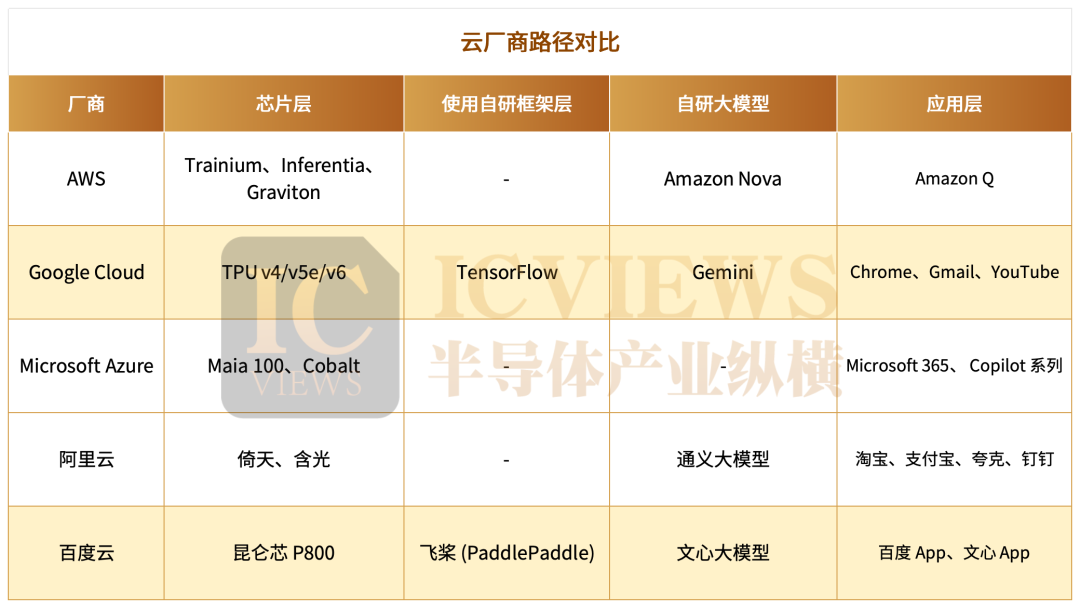
Since the beginning of the year, major cloud providers have become increasingly clear about their future paths for AI cloud. By examining their chip strategies, we can analyze the breakthrough paths of top cloud providers to date.
Let's start with AWS. As the global cloud computing leader with a 32% market share in Q3 2025, AWS boasts the most comprehensive self-developed chip portfolio—Graviton (general-purpose computing), Trainium (training), and Inferentia (inference). The Graviton series alone contributed over half of AWS's global new CPU computing power last year, improving energy efficiency by over 40% compared to traditional platforms and significantly reducing unit computing power costs.
Trainium has also performed impressively. At its Q3 earnings call, AWS stated that its self-developed AI chip Trainium2 has grown into a multi-billion-dollar business, offering a 30%–40% price-performance advantage over alternative GPU options. The liquid-cooled version of Trainium v2 cabinets will launch by the end of this year, with Trainium v3 mass production scheduled for 2026, indicating accelerated iteration of its AI infrastructure. However, the issue lies in the fact that technological leadership has not translated into market dominance in AI. In Q3 2025, AWS's cloud business grew by 20%, far below Azure (40%) and Google Cloud (34%), with AI revenue accounting for just 18%.
Currently, AWS adopts a dual-track 'hedging strategy.' Firstly, it follows the traditional cloud provider path to secure high-end clients. Recently, AWS secured a seven-year, $38 billion deal with OpenAI, granting OpenAI scheduling capabilities for hundreds of thousands of B200 GPUs. Although OpenAI has also signed agreements with Microsoft, Google, and Oracle for diversified supply, AWS has achieved 'breakthrough access' to high-end AI clients. Secondly, it leverages self-developed chips to bind core partners. AWS attempts to replicate the 'OpenAI + Microsoft' model by betting on Anthropic, but with a key difference: besides investment, Amazon insists that Anthropic transition its model training and deployment from NVIDIA GPUs to AWS. Amazon founder Jeff Bezos stated in an internal memo, 'Dual bets not only diversify risks but also optimize infrastructure through comparison.'
Additionally, AWS has prioritized Bedrock for large model aggregation. AWS's true goal has never been to become the best model company but to make all AI dependent on its computing power foundation. In the author's view, AWS is 'not vying for the title of model leader but seizing control of computing power.'
Now, let's examine Microsoft Azure. This year marks a turning point for Microsoft's AI strategy, as its once-unbreakable 'model + cloud' golden combination begins to loosen. Three landmark events clarify this trend. Firstly, OpenAI has explicitly shifted to a multi-cloud deployment strategy. After signing large-scale computing power agreements with AWS, Google Cloud, and Oracle, OpenAI CEO Sam Altman publicly stated, 'The lessons from GPT-4 training delays in 2023 must be learned. Diversified supply protects us from single-vendor capacity fluctuations.' This is a public questioning of Microsoft's computing power supply capabilities. Secondly, Microsoft's self-developed chip progress has fallen short of expectations. Maia v2, originally planned for mass delivery in 2025, has been delayed to the first half of 2026, while Maia v3's mass production has been postponed due to design adjustments. Self-developed chip shipments will remain extremely limited in the short term, meaning Azure cannot divorce itself from NVIDIA GPU dependency for at least the next two years. Thirdly, behind the apparent positives lies a passive reality. This year, Microsoft also signed a multi-billion-dollar AI infrastructure agreement with Lambda, but the deal specifies that Lambda will deploy NVIDIA-provided AI infrastructure on Microsoft Azure to support large-scale model training and inference tasks.
Microsoft now finds itself in an awkward position. It possesses the strongest AI gateway but lacks the most stable computing power foundation. Having previously relied on 'clinging to OpenAI,' it must now confront the reality that 'OpenAI no longer clings exclusively to it.' Without robust chip support, Microsoft risks sliding from an AI ecosystem definer to a computing power service competitor.
Google Cloud, previously low-key, has now stunned everyone with its full-stack self-development strategy. Let's start with chips. This year, Google released its self-developed TPU v7 (Ironwood), whose overall performance closely approaches that of NVIDIA's B200. More critically, Google has begun selling TPUs externally, implying two things: confidence in capacity and performance benchmarks. This year, Anthropic partnered with Google Cloud to secure exclusive access to up to 1 million TPU chips over the next few years, with a computing capacity exceeding 1 gigawatt and a value of tens of billions of dollars.
Google has now achieved synergistic evolution across all levels: TPU v7 chips at the foundation, TensorFlow compilation stacks in the middle, Gemini series models at the upper layer, and a peripheral network of neural endpoints comprising billion-user applications like Chrome, Gmail, Maps, and YouTube. This complete and self-contained technological ecosystem has enabled Google Cloud to truly demonstrate accumulated strength.
Full-stack AI capabilities have driven Google Cloud's outstanding performance. In Q3, its revenue grew 34% year-on-year, with a backlog increasing 79% to $155 billion and an operating margin of 23%. Management revealed that the number of $1 billion-plus deals signed in the first three quarters of this year already exceeds the total of the previous two years, indicating robust enterprise AI demand.
03
Who are the true powerhouses in cloud?
Some believe that cloud providers developing self-developed chips are 'strong.' However, a single chip breakthrough represents at most 'point strength,' not a true industry barrier. For cloud providers, genuine strength lies in end-to-end autonomous delivery capabilities: from chip design to software stack adaptation, large-scale cluster deployment, actual business workload bearing, and commercial service output. This tests not individual breakthroughs but a systematic engineering capability. Globally, few have navigated this path successfully; Google, as previously analyzed, is a prime international example.
In China, only two providers demonstrate similar potential: Alibaba Cloud and Baidu Intelligent Cloud.
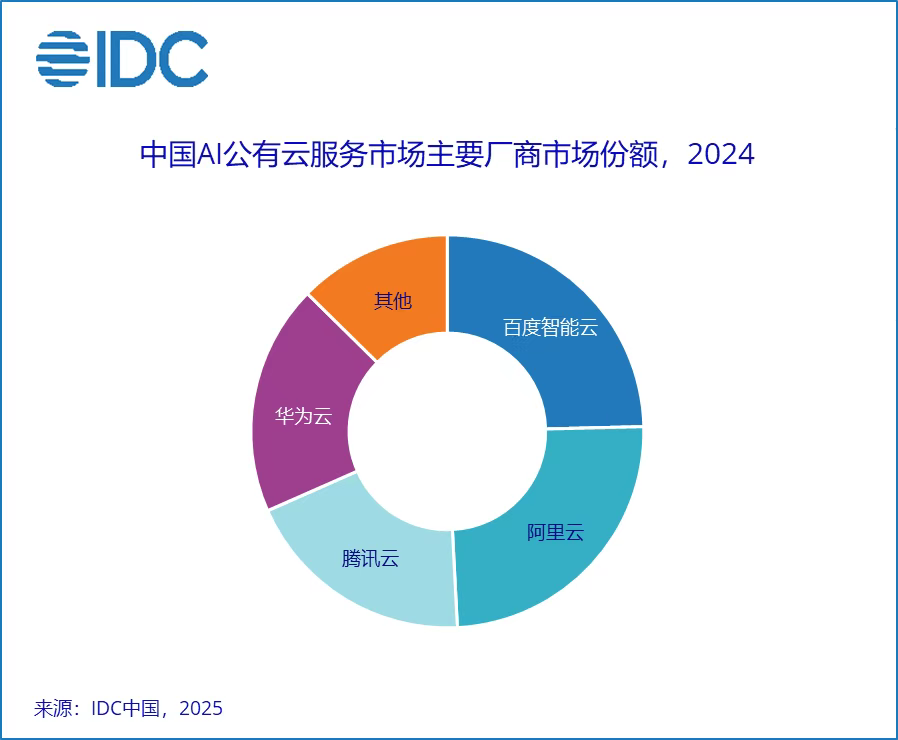
According to IDC's latest report, the Chinese AI public cloud services market reached 19.59 billion yuan in 2024, with Baidu Intelligent Cloud and Alibaba Cloud tied for first place. The market share chart reveals that these two providers alone account for nearly half of the entire market.
Alibaba has built a 'multi-chip cloud' system around 'Yitian + HanGuang + LingJun platform,' adhering to a full-stack self-development route and achieving large-scale inference deployment in government and financial trust scenarios. Its strategy is clear: trading full-stack synergy for efficiency and autonomous core components for controllability.
Baidu, meanwhile, is forging a different path. At Baidu World 2025, founder Robin Li discussed the need for an 'inverted pyramid' AI industry structure, stating, 'In this structure, while chipmakers may earn significant profits, models built atop chips must generate 10 times more value, and applications developed from those models must create 100 times more value. That is a healthy industrial ecosystem.'
The author wishes to highlight Baidu Intelligent Cloud's uniqueness this year.
Let's begin with chips. At Baidu World 2025, Baidu unveiled its next-generation chip alongside the 'Tianchi 256' and 'Tianchi 512' super-node solutions, supporting up to 512-card interconnection and enabling single 512-super-node training of trillion-parameter models.


Baidu Executive Vice President Shen Dou stated on-site, 'By launching these new chips and super-node products, we aim to provide enterprises with powerful yet low-cost AI computing power.' More critically, Shen revealed that besides supporting most large model inference tasks, the platform can 'cost-effectively train a multimodal model' using a 5,000-card single cluster. This demonstrates that Kunlun chips are not experimental products but have become the primary computing power foundation for Baidu's AI system.
In terms of applications, Kunlun chips have achieved scale and systemization. In the first half of this year, a 30,000-card cluster based on P800 was successfully deployed, while Kunlun chips have already been implemented beyond Baidu in industries such as fintech, energy, manufacturing, transportation, and education.
Baidu's chip strategy has long been methodical. In 2011, Baidu initiated its AI accelerator project; in 2017, it released the Kunlun XPU architecture; and in 2018, it formally began AI chip product design. While most cloud providers were scrambling for GPUs, Baidu had already deployed self-developed chips in core business scenarios like search and recommendations. By grounding its approach in practical scenarios and industrial applications, Baidu avoided the risks of blind chip development detached from market needs.
In model support scenarios, Baidu Intelligent Cloud AI Computing Chief Scientist Wang Yanpeng explained that Kunlun chips have successfully supported the training and inference of complex models like Qianfan 70B VL, Qianfan 30B-A3B-VL, and Baidu Steam Engine in large-scale deployments, accumulating mature implementation cases for both multimodal models and MoE architectures.
The true enabler of this hardware potential is the Baige AI Computing Platform 5.0.
Unlike traditional resource pools, which are limited to merely scheduling tasks, Baige revolutionizes efficiency at the fundamental levels of network architecture, memory management, and communication protocols. For instance, its proprietary HPN network enables RDMA interconnection for up to 100,000 cards, with end-to-end latency slashed to a mere 4 microseconds. Additionally, its X-Link protocol, tailored for Mixture-of-Experts (MoE) models, dramatically boosts inter-expert communication efficiency. What sets Baige apart is its seamless compatibility with the CUDA ecosystem, empowering enterprises to effortlessly migrate their existing models to Kunlun chip clusters without the need for code rewrites. Notably, empirical tests have demonstrated substantial enhancements in training efficiency.
If chips and platforms serve as the bedrock, Baidu's true competitive edge lies in its burgeoning four-tier ecosystem: 'computing power—framework—model—application.' Spanning from its in-house Kunlun chips to the PaddlePaddle deep learning framework, the Wenxin large language models, and the Qianfan platform and application ecosystem, Baidu stands as the sole domestic cloud provider boasting end-to-end self-developed capabilities across all four layers.
The merits of this ecosystem are vividly illustrated through numerous client success stories. The Shenzhen Power Supply Bureau of China Southern Grid harnessed Baidu Agent technology to intelligently monitor distribution networks and streamline operation ticket audits. Meanwhile, the Beijing Humanoid Robot Innovation Center's recently unveiled embodied multimodal large model, Pelican-VL 1.0, leverages Baige as its foundational infrastructure, significantly elevating data collection and training efficiency. Ju Xiaozhu, the project lead at the center, remarked, "Thanks to the collaborative efforts of Baidu Intelligent Cloud, we've surpassed the average scores of GPT-5."
Echoing Li Yanhong's sentiment, "When AI capabilities are seamlessly integrated and become an innate part of the system, intelligence ceases to be a cost and transforms into a productive force." The era of competing solely on hardware card counts has drawn to a close, ushering in a new age of competing on foundational strengths.
In China, Alibaba and Baidu are converging on the same conclusion through distinct paths: a genuine AI cloud must command full-stack control, spanning from chips to applications. Consequently, a new dichotomy is emerging. The AI clouds of tomorrow will be categorized into two distinct groups: those equipped with self-developed chips and deep synergy capabilities, and those lacking such attributes. However, this is not merely a technical route selection; it represents a strategic endurance test.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






