Chinese Companies Launch Initiatives to Challenge the Most Advanced Embodied AI Brain
 11/26 2025
11/26 2025
 634
634

Editor's Note: Embodied AI is not merely a breakthrough in a single technology but a global wave driven by the combined forces of capital, engineering, and scenarios. Much like the geographical discoveries five centuries ago, we are now redrawing the boundaries of the physical world under the drive of intelligence.
Galaxy Frequency presents a special series titled 'Embodied AI Great Navigation,' which adopts a global perspective and focuses on core areas such as general-purpose robots, companion robots, robot dogs, and large robot models. It provides in-depth analyses of the leading players in the industry.
Named 'Great Navigation,' the series records how explorers navigate the waves of algorithms, hardware, and capital to find their new continents.
Just as every great navigation reshaped the world, the journey of embodied AI is redefining the relationships between machines and humans, as well as between technology and society. In this series, we focus not only on who will be the first to reach the shore but also on who is guiding the course, how to navigate through the foam (bubble), and where the truly worthwhile future lies.
Previous Articles: 'The Billion-Dollar Club of Embodied AI: 10 Global Players,' 'The Chinese Version of Figure AI: Four Emerging Contenders'
Author | Mao Xinru
Seven months apart, Physical Intelligence has released two significant announcements: the launch of its new model, π*0.6, followed by the completion of a new $600 million funding round.
After the release of π0.5 in April, which enabled robots to perform household tasks in unfamiliar environments, the next-generation π*0.6 further enhances its intelligent self-evolving capabilities.
To achieve this breakthrough, the PI team adopted a novel method called Recap, based on advantage-conditioned policies. It employs reinforcement learning through experience replay and error correction mechanisms to upgrade the original end-to-end VLA model.
Recap integrates three human-like learning stages: initial demonstrations, real-time expert corrections when robots make mistakes, and self-improvement through reinforcement learning during autonomous trials.
This effectively addresses a critical flaw of imitation learning in robotics: preventing small errors from snowballing during real-world interactions, thereby enhancing reliability.
From the results, π*0.6 doubled its throughput in handling high-difficulty tasks and reduced failure rates by more than two-fold. Robots can even operate continuously for hours, tackling challenges such as making espresso for 18 hours a day and folding 50 new garments in unfamiliar home environments.
From π0 to π0.5 and now to π*0.6, Physical Intelligence has demonstrated a remarkably clear paradigm:
First, teach robots to 'work' using large-scale cross-robot data.
Next, enable them to 'understand the situation' in unfamiliar environments through heterogeneous training.
Finally, let them evolve in the real world through error correction and self-leveling, gradually growing into an Embodied Agent.
This upgrade was swift, with many researchers noting that they had not fully explored the just open-sourced π0.5 before π*0.6 was released.
Without exaggeration, Physical Intelligence stands as an undisputed leader in developing robot brains within the embodied AI industry. Some companies even fine-tune its open-source models and claim them as 'technical upgrades.'
Against this backdrop, four Chinese companies—Xinghaitu, Independent Variable Robotics, AI Squared, and Qianjue Technology—have directly benchmarked their model performance against PI in their public announcements this year.
Industry Leader PI: A Natural Benchmark
To date, in the embodied AI competition centered on China and the U.S., Figure AI from the U.S. ranks first globally with a valuation of $39 billion, followed closely by Physical Intelligence at $5.6 billion.
Backed by OpenAI, Sequoia Capital, and Amazon founder Jeff Bezos, Physical Intelligence has secured $1.07 billion in funding.
Unlike Figure AI and leading Chinese companies that pursue full-stack software-hardware integration, Physical Intelligence focuses solely on robot brains.
This unique path stems from the strong academic backgrounds of its founding team.
Among the five core members, one is a renowned tech investor, while the other four are scientists from Stanford, UC Berkeley, and other prestigious institutions. They have been deeply involved in projects such as Google's RT series robot models and the Google Aloha robot.
As a startup, Physical Intelligence aims to rapidly adapt its universal robot intelligence solutions to various hardware and application scenarios, achieving scalable technology deployment.
The PI team believes that the industry's true bottleneck lies in software rather than hardware, and focusing on software allows them to concentrate resources on tackling algorithmic and data challenges.
Currently, PI's model demonstrations utilize a 'robotic arm + wheeled' robot form, which the team considers a mature hardware combination capable of performing complex tasks.
Despite being founded less than two years ago, PI has already released end-to-end VLA models π0, π0.5, and π*0.6. The first two models have been open-sourced, with π0 hailed as one of the strongest VLA models in the open-source domain.
As end-to-end VLA models, π0 and π0.5 differ primarily in architectural design, training strategies, and generalization capabilities.
π0 employs a VLM + Action Expert architecture, where the former interprets scenes and instructions, and the latter predicts continuous action sequences through flow matching technology.
Notably, flow matching—a variant of diffusion models—has become a mainstream approach for robotic base operation strategies due to its simplicity and effectiveness, widely adopted in advanced VLA models.
Whether it's π0, π0.5, LeRobot's SmolVLA, or NVIDIA's GR00T, all utilize this technology.
In terms of training strategy, π0 primarily relies on robot demonstration data, optimizing action predictions through end-to-end training. Its action representation depends entirely on continuous action spaces, generating action trajectories through flow matching.
While π0 performs well in known tasks and environments, its generalization capabilities in open environments are limited.
To overcome this bottleneck, the PI team introduced π0.5, which achieves long-duration task execution in unfamiliar home environments through hierarchical reasoning mechanisms and multi-source data collaborative training.
π0.5 builds upon π0 by incorporating a hierarchical reasoning mechanism. High-level reasoning predicts abstract semantic subtasks, such as 'pick up the plate' or 'open the drawer,' while low-level reasoning generates joint-level continuous actions based on these subtasks.
By integrating various types of robot data, network multimodal data, language guidance data, and semantic labels, robot training no longer relies solely on demonstration data but learns from diverse data sources.
Additionally, π0.5 adopts a combined discrete-continuous action representation. Robots use discrete actions during pre-training for efficiency and introduce flow matching during post-training for high-precision continuous actions, balancing training speed and control accuracy.
Currently, PI has established collaborations with Chinese companies. On the hardware side, its robotic arms are supplied by Fangzhou Infinity, while on the software side, it has deep partnerships with Zhiyuan Robotics and Stardust Intelligence.
Furthermore, Fibocom's development platform, Fibot, has been applied in data collection for the π0.5 model.
Four Chinese Companies Publicly Benchmark Against PI
As Chinese companies rise in the embodied AI field, several have introduced their foundational models and claimed superiority over PI's π0 and π0.5 in performance announcements.
Xinghaitu's G0 Model: Outperforms π0 across multiple benchmark tasks in evaluation results.
Independent Variable Robotics' Wall-OSS Model: Surpasses π0 in multiple dimensions.
AI Squared's Open-Source Model FiS-VLA: Exceeds π0's comprehensive performance by 30% in third-party evaluations.
Qianjue Technology's Brain-Like Large Model: Enables robots to autonomously decide and execute tasks based on vague instructions, with execution times far surpassing π0.5.
Overall, the embodied AI industry has largely reached a technological consensus centered on the VLA paradigm.
Within this consensus, the five players have formed differentiated positioning based on their strengths: PI exemplifies result-oriented, technology-driven innovation; Xinghaitu represents the data-driven + open-source ecosystem path; Independent Variable Robotics delves into software-hardware collaborative development (collaborative development); AI Squared prioritizes scenario-driven applications, emphasizing practical model value; and Qianjue Technology adopts a frontier theoretical approach.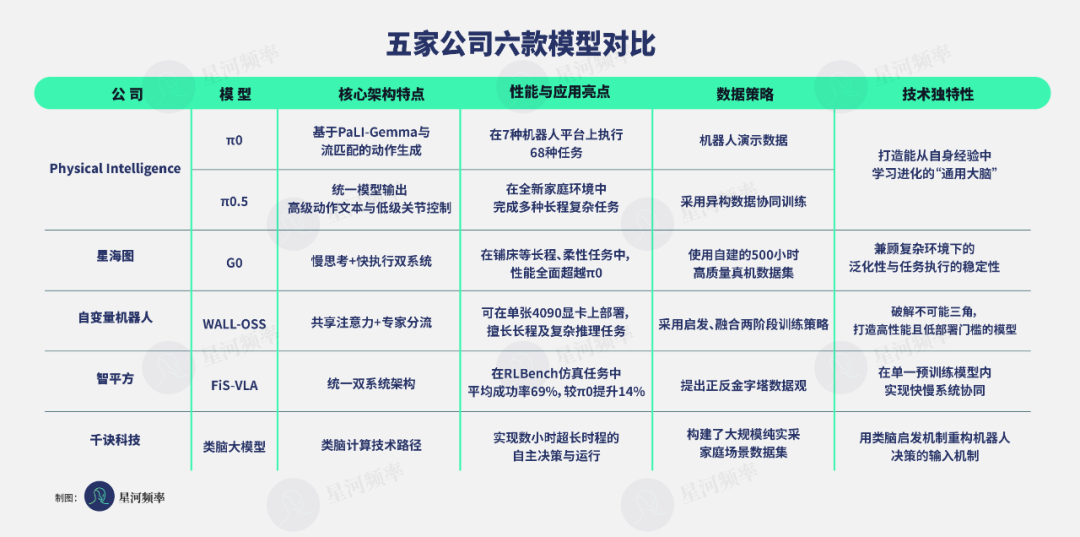
From an architectural perspective, these models exhibit two distinct paths: unified end-to-end and hierarchical decision-making.
PI's π0 and π0.5 embody the former's pursuit of simplicity and efficiency, directly outputting complete instructions from high-level action texts to low-level joint controls through a unified model, mapping semantic understanding to physical execution within a single framework.
Independent Variable Robotics' WALL-OSS emphasizes deeper unity, where shared attention and expert diversion (shunting) architectures enable language, vision, and actions to be cross-processed within the same representation space, fundamentally reducing error accumulation in multi-stage processes.
In contrast, the hierarchical path focuses on mimicking professional divisions in human cognition.
Xinghaitu's G0 Model and AI Squared's FiS-VLA Model both adopt dual-system architectures, separating complex task planning from high-frequency real-time control.
The G0 Model achieves stable coordination of 23 degrees of freedom in long-duration tasks like bed-making through explicit separation of fast and slow systems.
AI Squared's FiS-VLA goes further by embedding the fast system directly into the pre-trained slow system. By reusing the Transformer module at the end of the slow system, the fast system naturally inherits the slow system's semantic understanding capabilities, achieving organic unity of thought and action within a single model.
Qianjue Technology's Brain-Like Large Model introduces a more differentiated technical path by incorporating biological brain-inspired neural reasoning mechanisms into robot large models, offering robots a proactive adaptation capability closer to that of living organisms.
Behind these technical differences lie varying development philosophies and market positioning among the companies.
Firstly, open-sourcing has become a common choice for most players. Models like π0, π0.5, WALL-OSS, FiS-VLA, and G0 have all adopted open-source strategies, accelerating technology diffusion and feeding model iterations through developer communities, forming a virtuous cycle of 'open-source - feedback - optimization.'
Beyond commonalities, the five players differ more significantly in application scenarios and commercialization pace.
Physical Intelligence's π series focuses more on technical validation and generalization capability demonstration, with relatively limited commercial deployment; Chinese models, however, achieve deep integration of technology and commerce.
AI Squared has accumulated developer resources through its open-source ecosystem, achieving cost reduction and efficiency gains in industrial scenarios, while Xinghaitu concentrates on the scientific research and education market.
Independent Variable Robotics promotes integrated software-hardware solutions, and Qianjue Technology empowers robot manufacturers through API services, forming a commercial layout covering industrial, consumer, and edge-side scenarios.
These differences essentially stem from varying market demands: overseas markets prioritize technological universality and foresight, while the Chinese market emphasizes practical value and return on investment for technology deployment. This demand-driven divergence will continue to influence future model optimization directions.
When Will the ChatGPT Moment for Embodied AI Arrive?
One of the most frequently discussed questions at major forums this year is: When will the 'ChatGPT Moment' for embodied AI arrive?
Industry players hold differing views, with some optimistic and others cautious.
Wang Xingxing of Unitree believes that the current development stage of robot large models resembles the 1-3 years before ChatGPT's release, suggesting this moment may not be far off; Chen Jianyu of Star Motion Era, however, argues that achieving a high-standard ChatGPT Moment will still take over three years.
Wang He from Galaxy General pointed out that despite the high calls for the comprehensive application of humanoid robots, there is still a long way to go before they reach the ChatGPT moment.
Leng Xiaokun from RoboSense proposed that replicating the ChatGPT moment of large language models in the embodied intelligence field may be difficult to fully achieve.
In today's world where AI is deeply integrated into daily life, large language model AIs like ChatGPT and Deepseek have already provided us with great convenience. Humans ask AI questions, and AI can provide decent answers.
Applying this standard to the embodied intelligence field means: placing a robot in any scenario and asking it to complete various chores, and the robot can perform them well. 
Obviously, with current technology, achieving this goal still faces three major bottlenecks.
The first is the data bottleneck. The 'data shortage' in the embodied intelligence industry is already a well-worn topic.
For example, ChatGPT fed the model with a learning data volume equivalent to 400,000 years of continuous human learning, but the effective data in the embodied intelligence industry is roughly equivalent to only one year of continuous human learning.
The industry requires a large amount of multimodal data for training, but real-world data collection is costly and inefficient, and data from different robot hardware is difficult to reuse. Although simulation data can be generated in batches, it is prone to the Sim2Real Gap, which affects the model's generalization ability.
Therefore, the current industry generally adopts a combination of simulation + real data + open-source datasets to expand the data scale.
Quantity is the foundation, while quality is another major challenge.
Although more and more companies are beginning to collect data, there is a lack of effective assessment standards for data quality. Even if data is collected, if its quality is not high, it is still difficult to use for training robots.
Additionally, with the vast amount of internet video data, its physical correctness cannot be guaranteed, making it difficult to directly use for robot training.
The second bottleneck is the model. The existing model architectures are not mature enough, with significant obstacles in generalization ability, and there is a lack of unified and efficient models.
At the same time, in the field of robot reinforcement learning, a scaling law like that of large language models has not yet emerged, resulting in low efficiency for robots in learning new skills, with input and output returns not fully proportional.
The last issue is the system engineering problem. The insufficient generalization ability of models leads to a significant drop in task success rates when robots enter unfamiliar, unstructured environments.
Moreover, different robots lack unified standards in joint degrees of freedom, drive technologies, and material selection. Data and models from different hardware architectures are difficult to generalize, increasing research and development as well as deployment costs.
Currently, the power consumption that robot bodies can handle is limited, making it impossible to deploy large-scale computing power. Cloud computing also faces latency challenges, posing restrictions on computing power deployment. 
Overall, for embodied intelligence to reach its ChatGPT moment, robots need to adapt to unstructured real-world environments, achieve multi-sensory linkage (linked interaction), and possess human-like thinking abilities.
Correspondingly, robots also need to break free from the limitations of mechanical execution, enhance metacognition, and endow them with the ability to reflect and continuously learn, enabling them to adapt to new environments and tasks.
The 'benchmarking against PI' is essentially an inevitable stage in China's embodied intelligence industry during its technological catch-up process—quickly identifying gaps through a clear reference frame and concentrating resources to break through bottlenecks.
However, when PI has already iterated to π*0.6 and is actively open-sourcing to build an ecosystem, Chinese players need to go beyond simple performance benchmarking and seek differentiated breakthrough paths.
Whether it is StarHippo's data-first approach or AI Squared's scenario binding, both have already demonstrated development approaches with Chinese characteristics.
Although different paths have their own focuses, they all point to the same core: the competition in embodied intelligence is ultimately a synergistic competition of technology-data-scenario, rather than a performance competition of a single model.
As industry insiders have said, the explosion of ChatGPT was not due to a breakthrough in a single model but rather a triple resonance of language data, algorithmic architecture, and computing power support. The inflection point of embodied intelligence also requires such a synergistic effect.
Perhaps, the ChatGPT moment for embodied intelligence is not far away, but this critical juncture may quietly arrive amidst repeated model iterations and machine debugging.
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






