Achieving Performance Comparable to FLUX.1 and Qwen with Merely 1 Image and 1 Hour of Training, While Boosting Inference Speed by 5x! Glance Revolutionizes Diffusion Models with Its 'Slow-Fast Philoso
 12/05 2025
12/05 2025
 572
572
Insights: The Future of AI-Generated Content
Key Highlights
Ultimate Training Efficiency: Training is completed in under 1 hour using just 1 sample on a single V100 GPU. This stands in stark contrast to traditional methods that require thousands of GPU hours (e.g., DMD2 needs 3840 hours).
Non-Uniform Acceleration Strategy: Introduces a 'Slow-Fast' phased acceleration approach. Different acceleration ratios are applied to the semantic generation and detail refinement phases of diffusion models, aligning better with model characteristics compared to uniform acceleration.
Plug-and-Play Acceleration: Achieves acceleration by attaching two lightweight LoRA adapters to a frozen base model. This eliminates the need for retraining a large student network while maintaining strong generalization capabilities.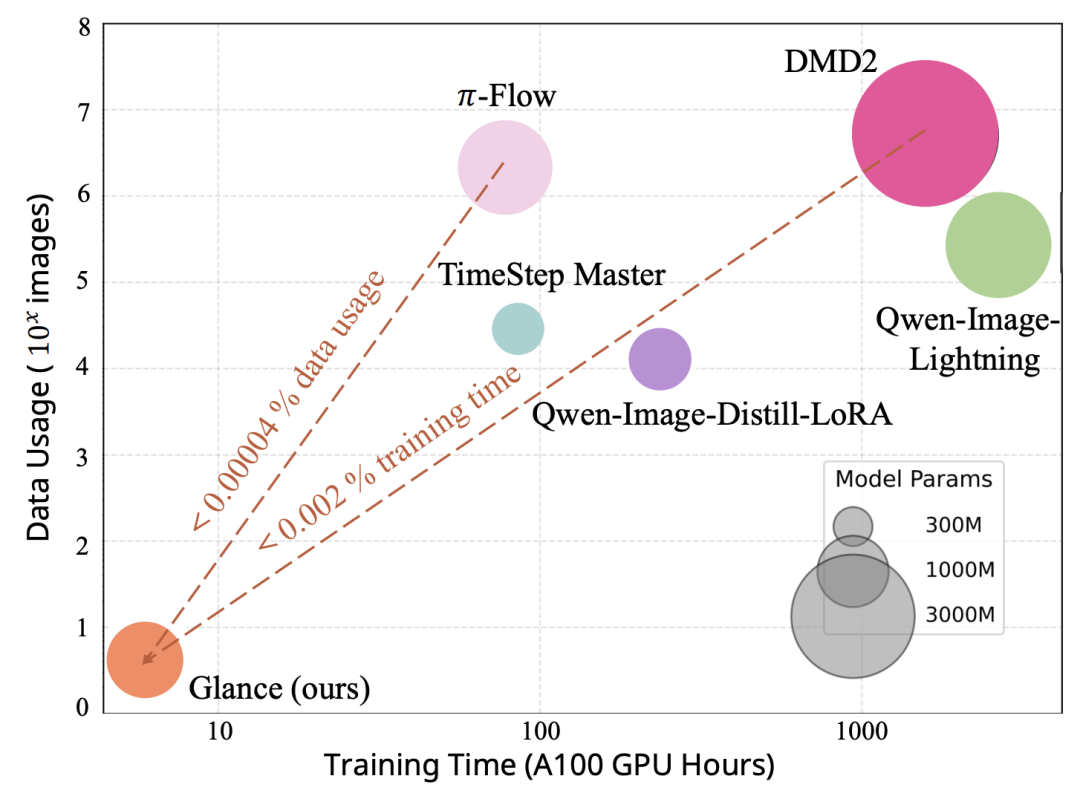 Figure 1. Comparison of data usage and training duration. Glance achieves comparable generation quality with just 1 training sample and 1 GPU hour, demonstrating extreme data and computational efficiency. Note that the x-axis uses a logarithmic scale, so zero values cannot be directly represented in the graph.
Figure 1. Comparison of data usage and training duration. Glance achieves comparable generation quality with just 1 training sample and 1 GPU hour, demonstrating extreme data and computational efficiency. Note that the x-axis uses a logarithmic scale, so zero values cannot be directly represented in the graph.




Challenges Addressed
High Inference Costs: Generating high-quality images with diffusion models typically requires numerous inference steps (e.g., 50 steps), leading to high computational costs and limiting applications.
Expensive Distillation and Fine-Tuning Challenges: Existing few-step distillation methods (e.g., LCM, DMD2) demand costly retraining and large datasets. Directly fine-tuning distilled models often results in blurry outputs.
Balancing Generalization and Efficiency: Achieving inference acceleration without quality loss using minimal data (even a single sample) and extremely low computational resources.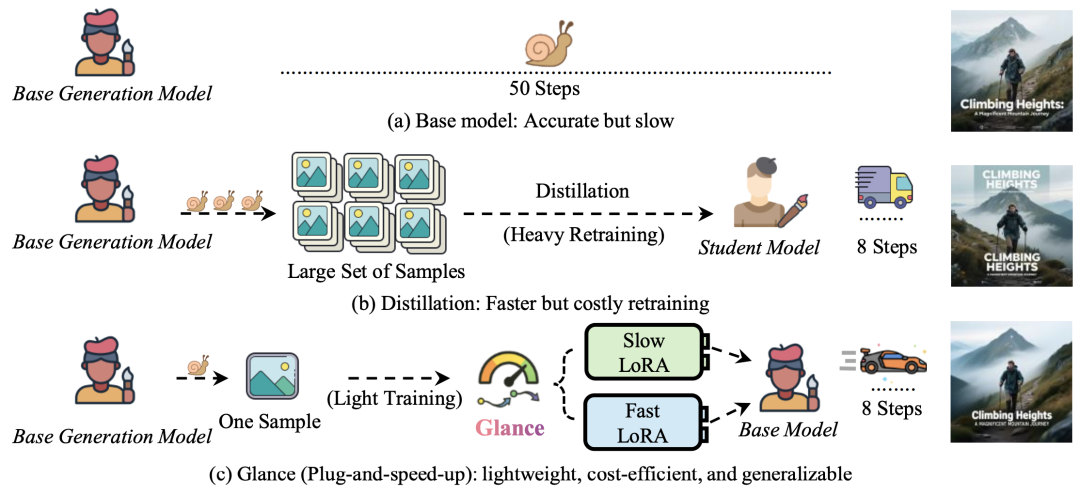 Figure 2: Comparison of distillation and acceleration strategies. Traditional distillation workflows rely on large-scale training sets and high-cost repetitive training. In contrast, Glance achieves slow and fast dual adapters with just a single sample, providing a plug-and-play acceleration solution for base generative models.
Figure 2: Comparison of distillation and acceleration strategies. Traditional distillation workflows rely on large-scale training sets and high-cost repetitive training. In contrast, Glance achieves slow and fast dual adapters with just a single sample, providing a plug-and-play acceleration solution for base generative models.
Proposed Solution
Glance Framework: Designs a phased acceleration scheme based on the observation that the diffusion process comprises an 'early semantic phase' and a 'late redundancy phase.'
Slow-Fast LoRA Experts:
Slow-LoRA: Accelerates at a lower ratio during the early phase (retaining more steps) to ensure accurate construction of global structures.
Fast-LoRA: Accelerates at a higher ratio during the late phase (skipping more steps) to rapidly complete texture refinement.
Flow Matching Supervision: Utilizes the Flow Matching objective function to enable LoRA adapters to directly learn the accelerated denoising trajectory velocity field.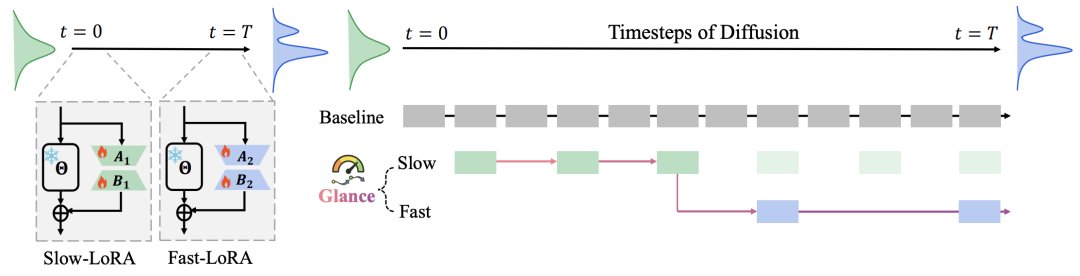 Figure 3: Visual schematic of the Slow-Fast paradigm. In the slow phase, we sample every two steps from the first 20 time steps (obtaining 5 samples in total). In the fast phase, we uniformly sample an additional 5 time steps from the remaining 40 steps. During inference, time steps in the slow phase are executed prior to those in the fast phase.
Figure 3: Visual schematic of the Slow-Fast paradigm. In the slow phase, we sample every two steps from the first 20 time steps (obtaining 5 samples in total). In the fast phase, we uniformly sample an additional 5 time steps from the remaining 40 steps. During inference, time steps in the slow phase are executed prior to those in the fast phase.
Technologies Applied
LoRA (Low-Rank Adaptation): Leverages low-rank matrix fine-tuning techniques to avoid full-parameter training, significantly reducing memory and computational requirements.
Flow Matching: Directly regresses the target velocity field, enabling more efficient extraction of structural knowledge with fewer samples compared to score matching.
Phase-Aware Strategy: Divides the denoising process into distinct regions based on the signal-to-noise ratio (SNR) or time steps, training specialized expert models for each region.
Achieved Results
Acceleration Ratio: Achieves 5x acceleration (8-10 step inference) on FLUX.1-12B and Qwen-Image-20B models.
Quality Preservation: Performs at 92.60%, 99.67%, and 96.71% of the teacher model's performance on OneIG-Bench, HPSv2, and GenEval benchmarks, respectively, with nearly no loss in visual quality.
Generalization Capability: Despite training on just 1 image, the model demonstrates remarkable generalization to unseen prompts and complex scenarios (e.g., text rendering, various styles).
Methodology
Glance, a phase-aware acceleration framework, aims to enhance both the efficiency and adaptability of diffusion models through a 'Slow-Fast' paradigm. We begin by reviewing the formulations of diffusion models and flow matching as preliminary knowledge. Then, we describe the proposed phase-aware LoRA experts and their learning objectives.
Preliminary Knowledge
Diffusion and Flow Matching: Diffusion models learn to fit data distributions by progressively transforming noise into data through a parameterized denoising process. The flow matching formulation interprets diffusion as learning a continuous velocity field that transports samples from Gaussian noise to clean data. At time step t, the intermediate state is defined as x_t, and the model predicts the transport velocity given conditions (e.g., text embeddings) c. The objective is to minimize the mean squared error between predicted and target velocities:
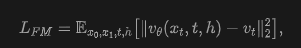
where v*(x_t, c) denotes the ground truth velocity. To achieve superior performance, diffusion models are typically designed with a large number of network parameters and pretrained on massive web-scale data. Evidently, distilling such enormous models to reduce steps is computationally expensive.
Low-Rank Adaptation (LoRA): To alleviate these challenges, LoRA has recently been applied for rapid distillation of diffusion models on target data. Specifically, LoRA introduces a low-rank decomposition of an additional matrix, A = B * C, where A represents frozen pretrained parameters, and low-rank matrices B and C (where rank(B) = rank(C) << dim(A)) constitute learnable LoRA parameters.
Phase-Aware LoRA Experts for Phased Denoising
To accelerate the denoising process of pretrained diffusion models while preserving generation quality, we retain the pretrained parameters and introduce a compact yet effective enhancement scheme: a set of phase-specific LoRA adapters. Each adapter specializes in a particular phase of the denoising trajectory, enabling the model to dynamically adjust during inference based on varying noise levels and semantic complexities.
Beyond Uniform Timestep Partitioning: Prior work, such as Timestep Master, has demonstrated the potential of using multiple LoRA adapters trained at different timestep intervals. However, uniform partitioning assumes equal contributions from all timesteps, contradicting the inherent non-uniformity of diffusion dynamics. Empirical analyses and previous studies reveal that different timesteps exhibit markedly distinct levels of semantic importance: during early, high-noise regimes, the model primarily reconstructs coarse global structures and high-level semantics (low-frequency information); in contrast, later, low-noise regimes focus on refining textures and details (high-frequency information).
Phase-Aware Partitioning via SNR: To better align expert specialization with the intrinsic dynamics of the diffusion process, we introduce a phase-aware partitioning strategy guided by the signal-to-noise ratio (SNR). Unlike timestep indices, SNR provides a physically more meaningful measure of the relative dominance of signal versus noise and decreases monotonically as denoising progresses. At the process's initiation (t large, high-noise phase), latent representations are dominated by low-SNR noise, making coarse structure recovery the primary objective. Conversely, as t decreases and SNR rises, the model transitions to a low-noise regime focused on texture refinement.
Based on this observation, we define a transition boundary corresponding to an SNR threshold (e.g., half of the initial SNR value). Two phase-specific experts are then employed: a slow expert dedicated to the high-noise phase (t > t_threshold), focusing on coarse semantic reconstruction, and a fast expert for the low-noise phase (t ≤ t_threshold), enhancing fine-grained details. This SNR-guided partitioning allows each expert to operate in its most effective regime, forming a semantically meaningful decomposition of the denoising process.
Surprising Effectiveness of Extremely Small Training Sets: To evaluate whether phased LoRA could recover accelerated inference, we initially conducted an overfitting-style experiment using just 10 training samples. Surprisingly, the model rapidly learned a faithful approximation of the accelerated sampling trajectory. More notably, reducing the dataset to a single training sample still yielded a stable acceleration behavior.
We attribute this data efficiency to the nature of flow matching. By directly predicting the target velocity field along the diffusion trajectory, the training objective bypasses redundant score-matching steps. Consequently, even with few examples, essential structural knowledge for rapid inference can be extracted.
Necessity of Carefully Designed Timestep Skipping: Despite promising data efficiency, subsequent ablation studies revealed that timestep skipping is far from arbitrary. While a few-step student model can broadly mimic the teacher model's behavior, not all timesteps contribute equally to reconstructing dynamics; naive skipping strategies may severely degrade performance. To address this, we conducted a comprehensive investigation of various specialization schemes. We first explored allocating multiple timesteps to the slow-phase LoRA adapter while reserving a single adapter for the fast phase, and vice versa. We also tested a degenerate configuration training a single LoRA across the entire trajectory. However, these variants either lacked the expressive capacity to capture high-noise complexities or failed to exploit the temporal locality of low-noise refinement phases.
Experiments ultimately demonstrated that separating the trajectory into dedicated slow and fast regions produces the most robust specialization effect. This design retains sufficient capacity to model challenging high-noise dynamics while enabling lightweight refinement in subsequent steps, achieving a compact yet effective acceleration mechanism.
Flow-Matching Supervision: Each phase-specific LoRA expert is trained under a flow-matching supervision scheme, aligning its predicted denoising direction with the underlying data flow. Given a noisy latent variable x_t obtained during the diffusion process, the model predicts a velocity field v_θ(x_t, c) supervised by the ground truth flow vector v*(x_t, c). The training objective is defined as a weighted mean squared error:
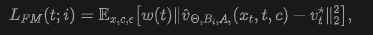
where w(t) denotes an optional timestep-dependent weighting function. By restricting each expert's training samples to its assigned denoising phase, the model effectively learns to focus on distinct noise levels. The resulting mixture of phase-aware LoRA experts collectively enhances denoising speed and generation quality, forming the foundation of our proposed Slow-Fast paradigm.
Experiment
This section presents a comprehensive evaluation of Glance on text-to-image generation tasks. Quantitative comparisons with competitive baselines are reported first, followed by detailed ablation analyses. The model’s generalization behavior and sensitivity to data scale are then discussed.
Experimental Setup
Distillation Setup: Two large-scale text-to-image generators, FLUX.1-12B and Qwen-Image-20B, are distilled into compact Slow-Fast student models. During distillation, base parameters inherited from teachers remain frozen, with only LoRA adapters optimized. Following Qwen-Image-Distill-LoRA, adapter placement is extended beyond standard attention projections. Specifically, LoRA modules are injected not only into query, key, value, and output projections but also into auxiliary projection layers of visual and text branches and modality-specific MLPs. This broader integration enables students to more effectively capture cross-modal dependencies and maintain generation fidelity despite compact capacity.
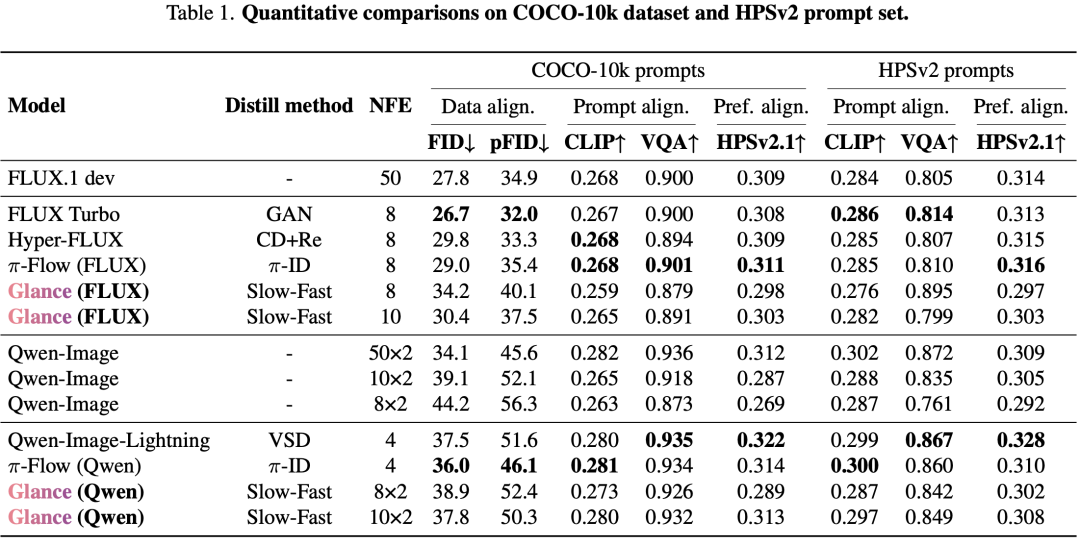
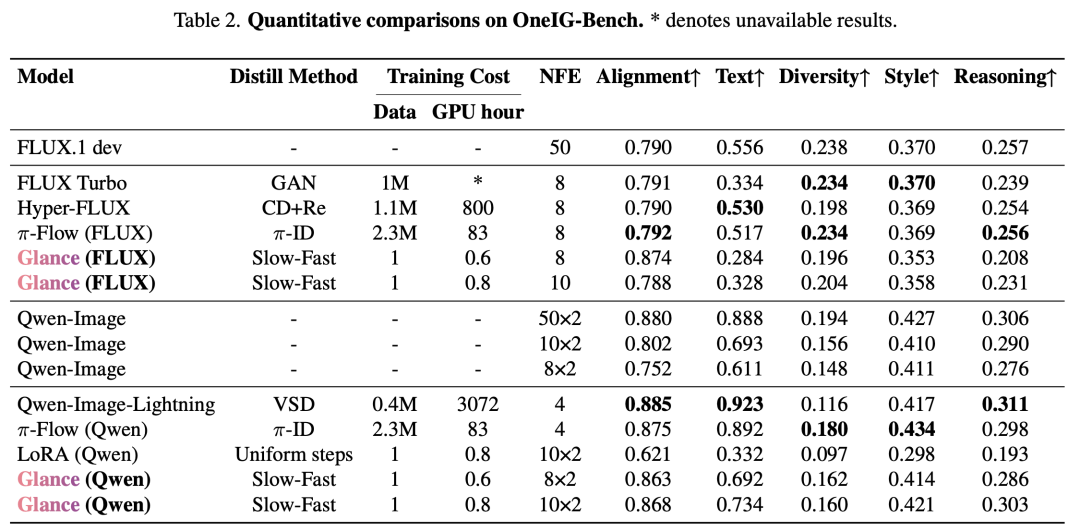
Evaluation Protocol: High-resolution image generation is comprehensively evaluated using prompts from six distinct sets: (a) 10K captions from the COCO 2014 validation set, (b) 3,200 prompts from the HPSv2 benchmark, (c) 1,120 prompts from OneIG-Bench, (d) 553 prompts from GenEval benchmark, (e) 1,065 prompts from DPG-Bench, and (f) 160 prompts from LongText-Bench. For COCO and HPSv2 sets, common metrics are reported, including FID, patch FID (pFID), CLIP similarity, VQAScore, and HPSv2.1. On COCO prompts, FID is computed against real images, reflecting data alignment. On HPSv2, CLIP and VQAScore measure prompt alignment, while HPSv2 captures human preference alignment. For OneIG-Bench, GenEval, DPG-Bench, and LongText-Bench, their official evaluation protocols are adopted, and results are reported based on their respective benchmark metrics.
Main Results
Performance Curve: Glance’s performance curve (Figure 4) closely aligns with the base model, indicating highly consistent accelerated behavior.
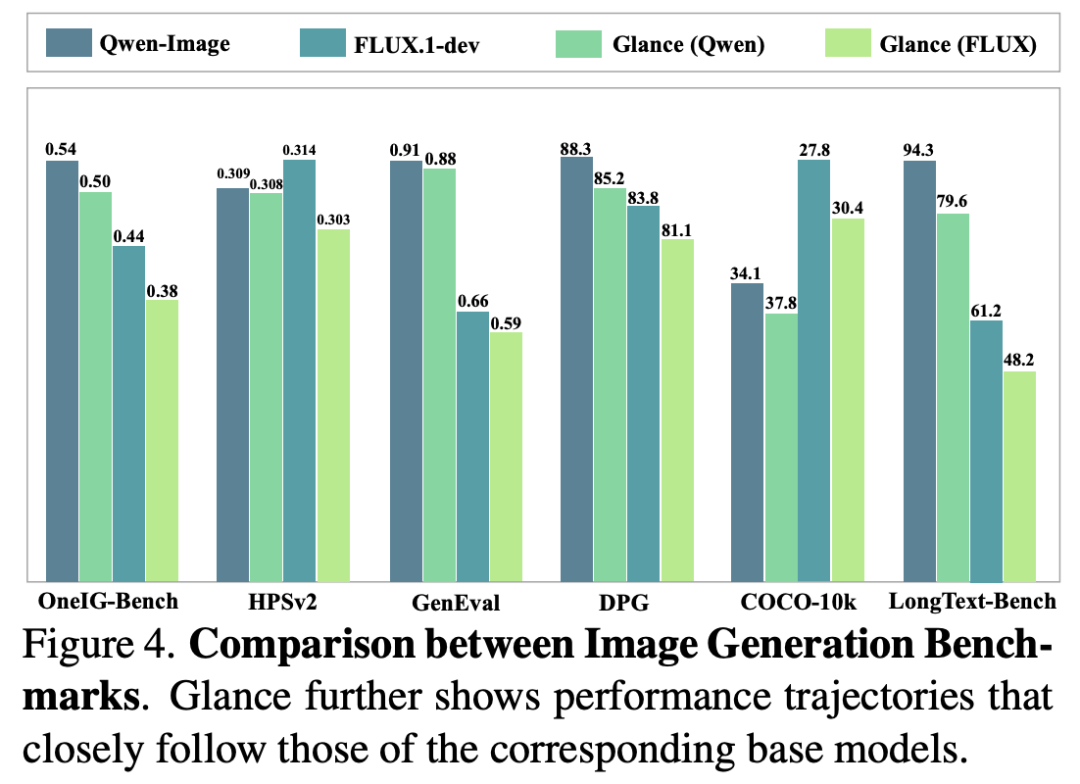
Quantitative Comparison: On OneIG-Bench, HPSv2, and GenEval, Glance achieves 92.60%, 99.67%, and 96.71% of the teacher model’s performance, respectively. Even compared to methods requiring thousands of GPU hours of training (e.g., DMD2, Qwen-Image-Lightning), Glance, trained for just 1 hour, demonstrates comparable or superior results.
Visual Quality: Qualitative comparisons (as depicted in Figure 5) reveal that the Glance model maintains semantic integrity during 8-step inference. In contrast, other models employing only 4 steps (such as Lightning) may exhibit a deficiency in detail.


Ablation Study
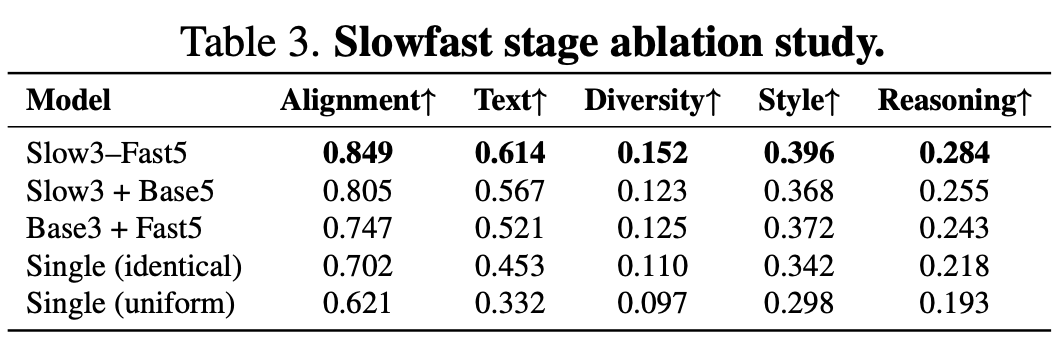
Slow-Fast Design: When comparing various time step allocation strategies, it becomes evident that the asymmetric configuration of “3 slow steps + 5 fast steps” surpasses uniform distributions or single-model configurations. This highlights the necessity of targeted acceleration.
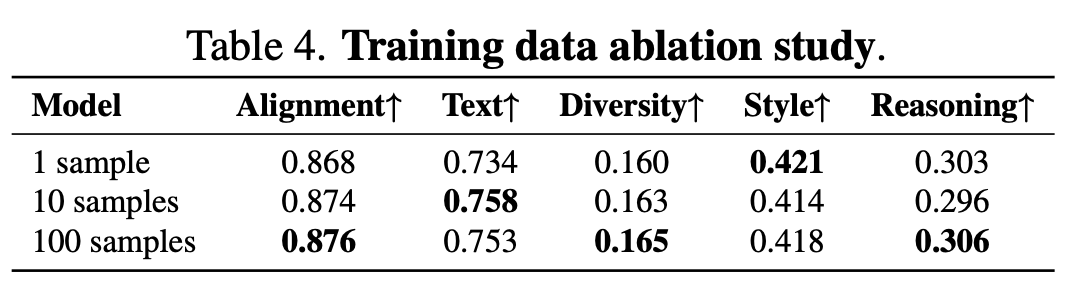
Data Scale: Doubling the number of training samples from 1 to 100 does not result in substantial improvements. This suggests that data quality and phase alignment hold greater significance than mere data volume.
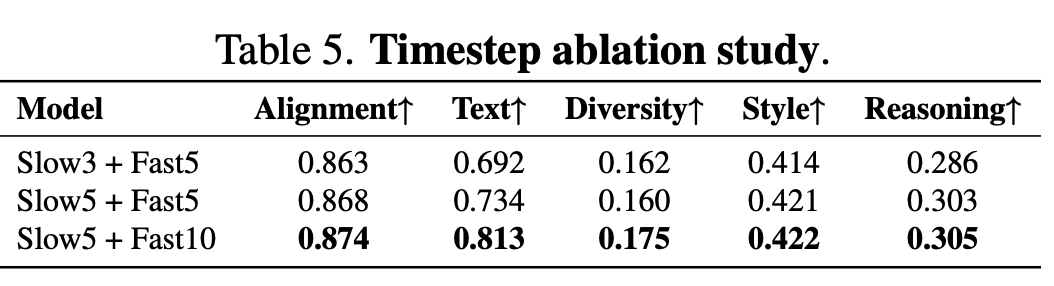
Time Step Coverage: Incorporating more LoRA-adapted time steps leads to enhanced text rendering and an overall improvement in quality.
Conclusion
The Glance framework leverages a lightweight distillation architecture to expedite diffusion model inference through a phase-aware “slow-fast” design. Research findings indicate that LoRA adapters effectively differentiate between various stages of the denoising process, thereby efficiently capturing both global semantics and local details. The framework achieves high-quality image generation in a mere eight steps, offering a 5× speedup compared to base models. Despite utilizing only a single image and a few hours of GPU training, Glance maintains comparable visual fidelity and exhibits strong generalization capabilities when faced with unseen prompts. These results underscore that data- and compute-efficient distillation methods can preserve the expressiveness of large diffusion models without compromising quality. Glance is poised to emerge as a preferred solution for accelerating large-scale diffusion models, especially in scenarios where data is scarce.
References
[1] Glance: Accelerating Diffusion Models with 1 Sample
-
![]()
ByteDance, DJI, and Xiaohongshu Secure Top Three Positions Among China’s Fastest-Growing Unicorns
-
Tesla's in-car voice system in China is finally learning to 'understand human language'
-
![]()
Foreigners Are Amazed: Chinese Electric Vehicle Drive Systems Unveil Innovative 'Poses'
-
![]()
700,000 Brothers and the Future of Robots: Behind JD.com's 'Nirvana Plan'
-
![]()
Zhipu's Trillion-Dollar Valuation: A New Chapter for China's AI
-
![]()
Is Laifen, a 'Dyson Alternative' on the Rise, Now Ensnared by the 'Alternative Curse'?
-
![]()
Beyond Patents: Insta360 and DJI Compete in Retail
-
![]()
Piercing Through Industry Chaos: The Curtain Rises on Compliance for Autonomous Driving






