Defining the Next Generation of Robot Training: A Key Breakthrough in Zhiyuan SOP: VLA Model's Real-World Distributed Online Post-Training
 01/07 2026
01/07 2026
 491
491
Currently, VLA models possess excellent generalization capabilities through large-scale pre-training. However, in real-world deployment scenarios, besides requiring broad versatility, they also need to achieve expert-level task execution. Take household robots as an example: they must be able to fold clothes, organize shelves, assemble furniture, while demonstrating reliability and precision comparable to specialized equipment.
To enable robots to truly perform tasks, the remaining challenge lies in how to endow these models with expert-level proficiency without sacrificing the versatility gained through large-scale pre-training.
Thus, the key lies in post-training—adapting pre-trained models to specific downstream deployment scenarios. In fields like Large Language Models (LLMs), post-training through online reinforcement learning (RL) and human feedback has proven highly effective, enabling continuous improvement through large-scale distributed training. However, for VLA post-training in the physical world, the system-level implementation of online learning combined with distributed data collection remains largely underexplored.
Existing post-training methods for VLA models are mostly offline, single-robot adaptation, or task-specific. In this mode, data collection and policy improvement are structurally disconnected.
Offline training on pre-collected demonstration data inevitably suffers from distribution shift, where minor execution errors accumulate over long-duration tasks. This limits efficient online policy adaptation and scalable learning in real-world interactions.
To address this, Zhiyuan Robotics proposes a Scalable Online Post-training system—SOP (Scalable Online Post-training)—a closed-loop agent-learner architecture capable of adapting and optimizing pre-trained VLA models using continuous real-world interaction data from heterogeneous robot clusters.

SOP System Workflow
Robot clusters continuously collect empirical data across various tasks, transmitting interaction data in real-time to a centralized cloud server and asynchronously receiving updated control policies—enabling VLA models to enhance task execution proficiency while maintaining versatility.
1. What is SOP?
The SOP system adopts a closed-loop architecture that tightly couples execution and learning: continuous interaction between the robot cluster and the centralized cloud learner—where the former transmits online policy trajectory data and human intervention signals to the latter, which asynchronously sends updated control policies back. This 'collect-train-deploy' closed-loop model enables low-latency model adaptation, with adaptation efficiency naturally increasing with the scale of the robot cluster.
The SOP framework comprises three core modules:
1) Distributed online policy data collection by robot agents;
2) Centralized cloud optimization based on online-offline hybrid data;
3) Low-latency model synchronization mechanism for returning updates to the agents.

SOP System Architecture
SOP adopts an Actor–Learner asynchronous architecture:
1) Actor (Robot Side) Parallel Experience Collection
Multiple robots (actors) deployed with the same policy model execute diverse tasks simultaneously at different locations, continuously collecting interaction data from successes, failures, and human takeovers. Each robot's empirical data is aggregated and transmitted to the cloud Experience Buffer.
2) Learner (Cloud Side) Online Learning
All interaction trajectories are uploaded in real-time to the cloud learner, forming a data pool composed of online data and offline expert demonstration data.
The system dynamically adjusts the online/offline data ratio through resampling strategies based on task performance, enabling more efficient utilization of real-world experience.
3) Instant Parameter Synchronization
Updated model parameters are synchronized back to all robots within minutes, enabling consistent cluster evolution and maintaining online training stability.
SOP is a scalable Actor–Learner framework suitable for online multi-task post-training of general policies. The robot cluster transmits online policy trajectory sampling data in real-time to the cloud learner.
When system failures or questionable judgments occur, an optional human intervention process is triggered, with human-corrected trajectories or actions incorporated into the buffer. The cloud learner generates task-balanced update parameters by fusing data from the online buffer and static offline buffer, then incorporates plug-in post-training modules (e.g., HG-DAgger/RECAP) and asynchronously broadcasts updated weights to all Actors (agents), forming a low-latency online training closed loop.
2. How Effective is SOP in Implementation?
Notably, SOP is algorithm-agnostic: the framework only defines system-level data flow and synchronization rules, with specific parameter update methods replaceable by any post-training algorithm.
In this study, the Zhiyuan team built an instantiated model of SOP based on two existing post-training methods—HG-DAgger and RECAP—and validated that SOP could upgrade these methods into deployable online policy-based post-training solutions by continuously inputting real-time interaction experience and executing high-frequency asynchronous model updates.
In tests across a series of real-world manipulation tasks (including cloth folding, box assembly, and grocery restocking), Zhiyuan Robotics verified that the SOP system significantly enhances the performance of large-scale pre-trained VLA models while maintaining a single shared policy across tasks. Efficient post-training can be completed with just a few hours of real-world interaction, and model performance scales approximately linearly with the size of the robot cluster. These results indicate that tightly integrating online learning with cluster-level deployment is the key technical pathway for achieving efficient, reliable, and scalable post-training of general-purpose robot policies in the physical world.
Overall, the research team systematically evaluated SOP around three questions:
1) How much performance improvement can SOP bring to pre-trained VLA?
2) How does robot scale affect learning efficiency?
3) Is SOP stable and effective under different pre-training scales?
1. How Much Performance Improvement Can SOP Bring to Pre-Trained VLA?
Experimental results demonstrate significant performance improvements across various test scenarios when combining SOP with post-training methods. Compared to the pre-trained model, the HG-Dagger method combined with SOP achieved a 33% overall performance improvement in complex retail environments. For dexterous manipulation tasks (cloth folding and carton assembly), SOP not only improved task success rates but also significantly enhanced policy operation throughput through error recovery capabilities learned from online experience.
The HG-Dagger method combined with SOP increased cloth folding throughput by 114% compared to HG-Dagger alone. SOP generally elevated multi-task generalist performance to near-perfection, with success rates exceeding 94% across tasks and reaching 98% for carton assembly.
 SOP Performance Improvement
SOP Performance Improvement
To further test whether the VLA model trained with SOP on real robots achieves expert-level performance, the research team conducted 36 hours of continuous operation with the SOP-trained VLA model, which demonstrated remarkable stability and robustness, effectively handling various challenges encountered in the real world.
2. How Does Robot Scale Affect Learning Efficiency?
Zhiyuan used three robot team sizes (single, dual, and quad configurations) with the same total data transmission volume for comparison. Experimental results showed that a larger number of robots led to higher performance under the same total training time. With a 3-hour training limit, the quad-robot configuration achieved a final success rate of 92.5%, 12% higher than the single-robot configuration.
The research team believes that multi-robot data collection effectively prevents model overfitting to specific characteristics of a single robot. Meanwhile, SOP translates hardware scalability into significant reductions in learning duration, with a quad-robot cluster increasing training speed to achieve target model performance by 2.4 times compared to a single robot.

SOP Learning Efficiency Improvement
3. Is SOP Stable and Effective Under Different Pre-Training Scales?
The research team divided 160 hours of multi-task pre-training data into three groups: 20 hours, 80 hours, and 160 hours, training an initial model for each group before applying SOP.
The study found that pre-training scale determines the trajectory of base model and post-training improvements. SOP provides stable improvements for all initial models, with final performance positively correlated with VLA pre-training quality.
Additionally, comparing the 80-hour and 160-hour experiments, it is evident that on-policy experience yields significant marginal effects in resolving specific failure cases.
SOP achieved approximately 30% performance improvement with just three hours of on-policy experience, while 80 hours of additional human expert data only brought a 4% improvement. This indicates that SOP can efficiently break through VLA performance bottlenecks when pre-training shows diminishing marginal returns.

Comparison of SOP Under Different Pre-Training Data Scales
3. Future Prospects
The research results from Zhiyuan Robotics indicate that system-level coupling of execution and learning is as crucial for successful post-training as the underlying algorithms. By enabling robot clusters to continuously upload online policy experience data and receive updated policy models in return, the SOP framework upgrades traditional phased fine-tuning into a scalable closed-loop learning model.
The study found that the marginal utility of online policy corrections significantly exceeds the utility gains from adding new offline data, a conclusion that aligns with a widespread industry consensus: static datasets cannot fully anticipate the state distribution changes triggered by deployed policies. SOP translates this conclusion into a deployable technical solution at the system level.
Despite demonstrating excellent performance, SOP currently relies on human intervention or task-specific reward signals for training. Future research directions include reducing such supervision costs through learned reward models or task success detection technologies based on foundation models.
Additionally, two open questions remain to be addressed:
1) Whether the current near-linear scaling efficiency can extend to even larger robot clusters;
2) How to achieve continuous acquisition of new skills while avoiding catastrophic forgetting.
Looking ahead, Zhiyuan Robotics envisions a scenario where robot clusters can collectively maintain a shared, continuously iterating policy model using empirical data from actual deployments.
From this perspective, expanding the robot deployment scale is equivalent to augmenting learning computational power—each additional robot further accelerates the optimization process of the policy model.
-
![]()
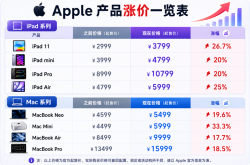
Breaking News! Apple Implements Sharp Price Hikes in the Dead of Night, Scalpers Go on a Stockpiling Spree, iPhone 18 in Jeopardy
-
![]()
Upgraded Wenxin and Paid Doubao: AI Bids Farewell to the 'Traffic-Only' Era
-
![]()
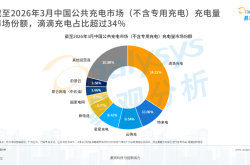
Users Vote with Their Feet, Propelling Didi Charging to Industry Leadership
-
Why Are Chinese Tech Companies Frequently Embroiled in Patent Litigation? Here’s the Real Story!
-
![]()
[Exclusive] Numerous BMW i3 and i4 EV Owners Receive Battery Replacement Alerts, Some After Just 8,000 Kilometers. BMW Attributes It to a System Glitch.
-
![]()
Nandu Puts ‘Gaokao Direct Train’, ‘Sunshine Gaokao Volunteer Filling Guide’, ‘Reliable AI’, ‘Xing Volunteer’, ‘Jiashu AI Volunteer’, and ‘Diebian Volunteer’ to the Test
-
![]()
Limits Can't Stop It! China's Electric Vehicle Supply Chain Infiltrates Indian Market: Pressure Mounts on Japanese Automakers
-
Hot Topic | New Entry Points, New Battles: Alipay Chooses Abao for a Comprehensive Service Hub, WeChat Utilizes AI Cards to Lay the Groundwork