Jordan, Zilliz's Overseas Business Chief: Vector Databases Shatter R&D Obstacles, Propelling AI Paradigm Evolution | 2025 Jixin AIGC Summit Speech Transcript
 01/07 2026
01/07 2026
 581
581
On December 26, 2025, the [Imagine · 2025 Jixin AIGC Summit] was successfully convened at the Pudong Software Park Building in Shanghai. Mr. Jordan, who heads Zilliz's Overseas Business division, delivered a speech titled "The Impact of Vector Databases on R&D Paradigm Shifts." He provided an in-depth analysis of how vector databases are revolutionizing the foundational logic of AI R&D. His talk covered topics ranging from the characteristics of unstructured data and methods to address large model hallucinations to the diverse application scenarios of vector technology.

Jordan, Zilliz's Overseas Business Chief
Jordan emphasized the following key points:
“In AI operations, vectorizing unstructured data is currently one of the most prevalent and well-established data processing techniques.”
“Hallucinations manifest in various forms, such as when AI generates incorrect responses, which we can intuitively notice in our daily lives.”
“Everything has the potential to be vectorized.”
Presented below is Jordan's original speech, as organized by Jixin, with the aim of providing valuable insights to all attendees.
01 Challenges in Data Governance
“Unstructured data can, in fact, be represented using vectors.”
To start with a simple definition, beyond traditional scalar forms (such as a string of characters in a field), data types like videos, audio, and images are classified as unstructured data. These unstructured data types can indeed be represented through vectors.
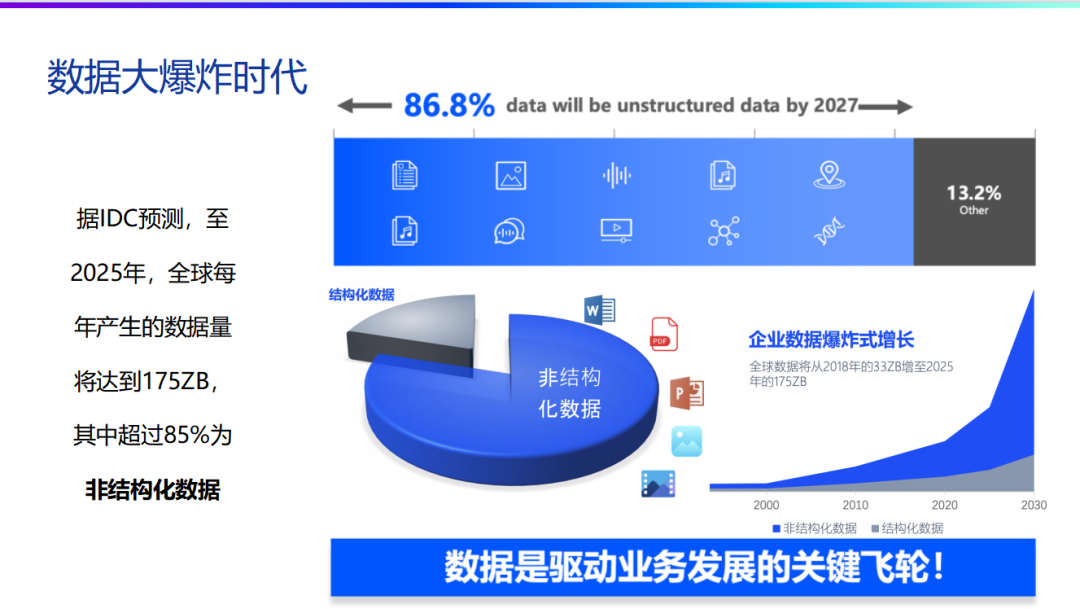
Consider the variety of information we receive daily. Besides textual data, a significant portion comes from videos, audio, and other formats. In reality, the proportion of unstructured data in our lives is far greater than many might realize. This pie chart effectively illustrates the proportion of information in our daily information intake, with unstructured data clearly holding a dominant position. Of course, in the realm of computer science or data governance, the application of unstructured data is still in its nascent stages.
Our mission centers on addressing challenges related to unstructured data. Let's approach this from a basic mathematical perspective. Drawing on knowledge from early analytic geometry, we can represent numerous aspects of life as points within a two-dimensional, three-dimensional, or even an infinite-dimensional coordinate system.
Taking three dimensions as an illustration, consider the words: 'bread' (in Chinese) and 'bread' (in English). 'Bread' (Chinese) can be depicted by a set of feature vectors (e.g., xyz123) in vector space. In traditional keyword searches, directly matching 'bread' (Chinese) with 'bread' (English) is challenging—traditional searches can only align keywords that literally coincide, such as 'noodles' (miàn, meaning 'noodle' or 'surface') and 'package' (bāo, meaning 'package' or 'wrap'), and fail to grasp the semantic connection between the two. However, if we map them into a geometric framework, with 'bread' (Chinese) as 123 and 'bread' (English) as 124, in vector space, we can compute their relative geometric relationships and distances, thereby determining their correlation.
This is why we can employ a straightforward geometric approach to link unstructured data that was previously impossible to match or relate. Of course, this is merely a basic example. If we can expand these dimensions by a factor of a hundred, a thousand, or even ten thousand, the volume of information that a string of geometric characters can encompass will vastly surpass our imagination.
02 Crisis of Model Reliability
“Hallucinations manifest in various forms, such as when it generates incorrect responses, which we can intuitively notice in our daily lives.”
A well-known manufacturer's large model previously showcased its capabilities through a question: How many 'o's are in the word 'school books'? This is a straightforward question, yet some earlier iterations of the large model answered that there were two, which is clearly at odds with the actual observation by the human eye—the correct answer should be four 'o's.
This issue is not confined to domestic settings but also occurs overseas. The model would even ingeniously add information about the positions of these letters, but the locations it provided were also incorrect.
However, if follow-up questions were posed to correct it, the model was sometimes capable of reflecting and rectifying itself. Under correction, the model would perform another calculation and ultimately arrive at the correct answer.
What is this phenomenon termed? There is a highly specialized term for it: Hallucination. This is, in fact, a deeply philosophical concept. When we engage with a large model as a conversational partner, the responses it provides that are not grounded in facts are considered hallucinations.
Hallucinations can manifest in diverse ways, but in daily life, the most apparent perception is when it generates incorrect responses. These are relatively minor issues, but envision if the user is a scholar conducting rigorous academic research. In 2023, we conducted a simple test using an older version of the model without any context, directly asking: Which are the top three districts in Shanghai by GDP? The model responded with Pudong New Area, Wuhan New Area, and Yangpu District. Regardless of whether Pudong New Area and Yangpu District are in the top three, we can be certain that Wuhan New Area does not belong to Shanghai, indicating another instance of hallucination.
But how can we overcome this phenomenon? This actually involves a well-established method in the technical field: Retrieval-Augmented Generation, commonly referred to as RAG. Simply put, we address this shortcoming in operations by manually inserting a knowledge base when posing a question, providing the large model with corresponding data (such as the actual GDP data of various districts under Shanghai's jurisdiction). Consequently, the large model will furnish the correct answer. This is a very basic prototype of RAG, assisting users in leveraging the strengths of large models when processing documents or solving daily life problems while avoiding interference with accurate information.
However, in certain scenarios, it may not be so straightforward because we may not have a pre-existing knowledge base. What should we do then? The solution is simple: Add a directive to the prompt given to the large model, stating, "Do not fabricate information if there is no answer." When the large model receives this information, for example, when faced with a question like "Which district ranks third in Shanghai by GDP?", if the information in the existing knowledge base cannot ascertain the answer, it will respond truthfully and offer some relevant explanations. In short, it will ultimately avoid providing misleading conclusive statements, preventing significant deviations from impacting real-life operations.
If you prefer not to delve into complex IT concepts, you can simply comprehend it as follows: When we incorporate these optimization measures in the backend and across various interactive links on the user or business end, various evolutions and variations of RAG emerge. This is also a crucial aspect of the AI innovations we currently emphasize at the terminal or business end.
03 Bottlenecks in Technological Application
“Everything has the potential to be vectorized.”
In 2022, numerous individuals still invested substantial economic resources and team efforts into exploring creativity. However, the growth capabilities of models posed considerable challenges for us. RAG, on the other hand, enables us to resolve many practical business problems in a relatively lightweight and convenient manner.
So, what role does the vector database play in this context? It can be understood that in communication with large models, the underlying layer of all language content is not a string of standardized scalars but rather semantic vectors—semantics are vectors. Therefore, when you need to insert a knowledge base for a large model on a massive scale, the foundational support actually originates from a vector database.
This leads us to contemplate the migration of application scenarios: In what areas will vector databases be instrumental? Horizontally, they can function in scenarios such as search, recommendation systems, large models, and risk control, with the horizontal axis extending infinitely. Vertically, they correspond to types of unstructured data, all of which can be vectorized. The intersection of the two generates countless application scenarios for empowerment.
These capabilities are indeed applicable in daily life. For instance, when shopping on e-commerce platform A, if you find an item particularly expensive, you can take a photo and search for it on e-commerce platform B, only to discover that the same item is 90% cheaper elsewhere. How is this accomplished? It involves extracting the vector features of the two images and comparing them to calculate their most suitable nearest-neighbor relationship under a specific algorithm in the coordinate system, enabling us to find the most cost-effective product.
This is an application in a commercial scenario. As previously mentioned, in molecular drug development, we can vectorize molecular structures. Among our clients are material-type enterprises, and even in the field of autonomous driving, with the emergence of more and more multimodal solutions, related technologies can discern differences between various types of data, all of which can be achieved with the assistance of vector databases.
-
![]()
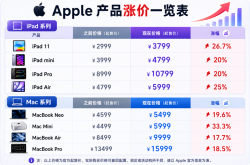
Breaking News! Apple Implements Sharp Price Hikes in the Dead of Night, Scalpers Go on a Stockpiling Spree, iPhone 18 in Jeopardy
-
![]()
Upgraded Wenxin and Paid Doubao: AI Bids Farewell to the 'Traffic-Only' Era
-
![]()
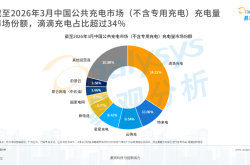
Users Vote with Their Feet, Propelling Didi Charging to Industry Leadership
-
Why Are Chinese Tech Companies Frequently Embroiled in Patent Litigation? Here’s the Real Story!
-
![]()
[Exclusive] Numerous BMW i3 and i4 EV Owners Receive Battery Replacement Alerts, Some After Just 8,000 Kilometers. BMW Attributes It to a System Glitch.
-
![]()
Nandu Puts ‘Gaokao Direct Train’, ‘Sunshine Gaokao Volunteer Filling Guide’, ‘Reliable AI’, ‘Xing Volunteer’, ‘Jiashu AI Volunteer’, and ‘Diebian Volunteer’ to the Test
-
![]()
Limits Can't Stop It! China's Electric Vehicle Supply Chain Infiltrates Indian Market: Pressure Mounts on Japanese Automakers
-
Hot Topic | New Entry Points, New Battles: Alipay Chooses Abao for a Comprehensive Service Hub, WeChat Utilizes AI Cards to Lay the Groundwork