Full-stack Visual Generator Arrives! Latest VINO from SJTU & Kuaishou & Nanyang Technological University: Image and Video Generation + Editing All in One
 01/07 2026
01/07 2026
 527
527
Interpretation: The Future of AI Generation
Key Highlights
Unified Visual Generation Framework VINO: A model that unifies image/video generation and editing tasks under a single framework, eliminating the need for separate modules tailored to specific tasks.
Interleaved Full-Modality Context: By coupling a Visual-Language Model (VLM) with a Multimodal Diffusion Transformer (MMDiT), multimodal inputs are encoded as interleaved conditional Tokens, enabling unified processing of text, image, and video signals.
Token Boundary Mechanism: A mechanism that reuses VLM's special Tokens (start/end tokens) to wrap VAE latent variables in MMDiT, effectively maintaining identity consistency across semantic and latent representations while reducing attribute leakage.
Progressive Training Strategy: A multi-stage training process designed to successfully extend a video generation foundation model into a unified generator with multi-task capabilities, while preserving its original high-quality generation abilities.
Results Overview




Problems Addressed
Fragmentation of Visual Generation Tasks: Existing text-to-image, text-to-video, and visual editing models are typically developed and deployed independently, lacking uniformity.
Conflict and Decoupling of Multimodal Signals: When multiple guiding signals such as text, images, and videos are provided simultaneously, existing models struggle to reliably decouple and prioritize them, leading to semantic conflicts or inconsistent conditional control effects.
Adaptability Differences Between Long and Short Text Instructions: Generation tasks often rely on long descriptions, while editing tasks use short instructions, making it difficult for models to adapt to both formats simultaneously.
Proposed Solution / Applied Technologies
VLM + MMDiT Architecture: Uses a frozen Qwen3-VL as the front-end encoder to process all language and visual conditions, paired with HunyuanVideo (based on MMDiT) as the diffusion backbone network.
Learnable Query Tokens: Introduces learnable Tokens at the VLM input as a flexible interface between high-level instructions and low-level diffusion features, jointly optimized with the generator to enhance alignment and stability of multimodal conditions.
Shared Boundary-Marked Latent Variable Injection: To compensate for VLM's loss of detailed features, VAE latent variables from reference images/videos are injected into MMDiT. The key technology involves reusing VLM's <|vision_start|> and <|vision_end|> Tokens to mark the boundaries of VAE latent variables, ensuring correspondence between semantic and latent features.
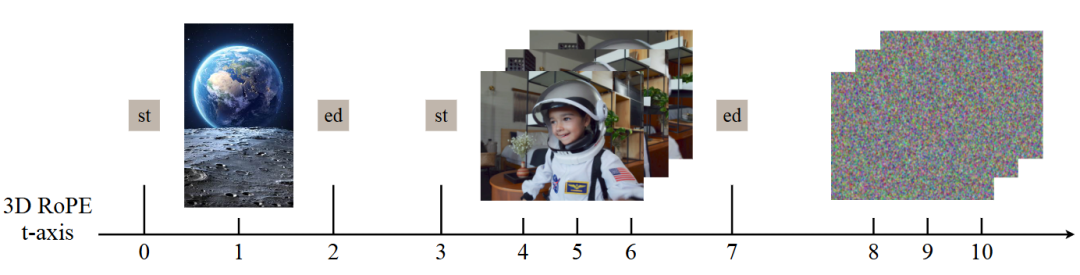
3D RoPE Strategy: Applies unified 3D rotational position encoding along the timeline to process different visual modalities in an interleaved manner.
Achieved Effects
Versatile Multi-Task Performance: On benchmarks like Geneval and VBench, VINO demonstrates strong capabilities in image/video generation and editing.
Instruction Adherence and Consistency: Compared to baseline models, VINO performs better in following complex instructions and preserving identity features (ID preservation) of reference images/videos, especially in multi-identity editing scenarios.
Efficient Capability Expansion: Through progressive training, the model exhibits superior editing capabilities compared to most open-source baselines with only minimal fine-tuning on a small amount of editing data (Stage 3).
Architectural Approach
This section introduces a unified framework for multimodal image and video generation/editing. The goal is to design a system capable of accepting heterogeneous control signals—text instructions, reference images or videos, and learnable Tokens—and using them to guide a diffusion-based visual generator. Following the high-level model flow (as shown in Figure 3), this section focuses on three core components: first, Section 2.1 describes how to process multimodal conditions through a Visual-Language Model (VLM) to obtain coherent feature representations; next, Section 2.2 explains how to inject these encoded conditions into a Multimodal Diffusion Transformer (MMDiT) without ambiguity or incorrect cross-modal alignment; finally, Section 2.3 details the training strategy that enables the entire architecture to function as a unified multi-task visual generator supporting a wide range of editing and generation tasks.

Figure 3 | Overview of the VINO pipeline. Our unified framework sets generation conditions on interleaved full-modality contexts, which jointly encode system prompts, prompts/instructions, reference images/videos, and learnable markers. The frozen VLM processes text instructions and visual references, generating multimodal embeddings supplemented by learnable symbols (purple) and separated by special symbols (vision start and vision end). These interleaved multimodal representations are input into the MMDiT module, which also receives VAE latent variables from reference images or videos. The MMDiT model performs denoising based on the complete multimodal context, enabling VINO to execute image and video generation as well as instruction-based editing within a single unified architecture.
Multimodal Conditions
To handle various forms of input, this work employs a frozen VLM model as the front-end encoder for all language and visual conditions. As shown in Figure 4, the system prompt adapts based on the presence and quantity of input modalities. When no visual modality is provided, users supply only text input, serving as the sole condition for text-to-image or text-to-video generation. When visual inputs are present, they are first sorted by type (images first, then videos) and placed at the beginning of the prompt, with each input assigned a unique identifier such as Image 1 or Video 1. Users can then reference these identifiers in the text input to specify different visual conditions, enabling complex multimodal control. Additionally, a set of learnable Tokens is appended to the end of the prompt, extracting cross-modal features into a shared space. These Tokens are also processed using causal masking rather than full bidirectional attention. Finally, the hidden states from the second-to-last layer of the VLM are used as the encoded conditions, projected via a two-layer multilayer perceptron (MLP) for feature projection before being input into the subsequent MMDiT.
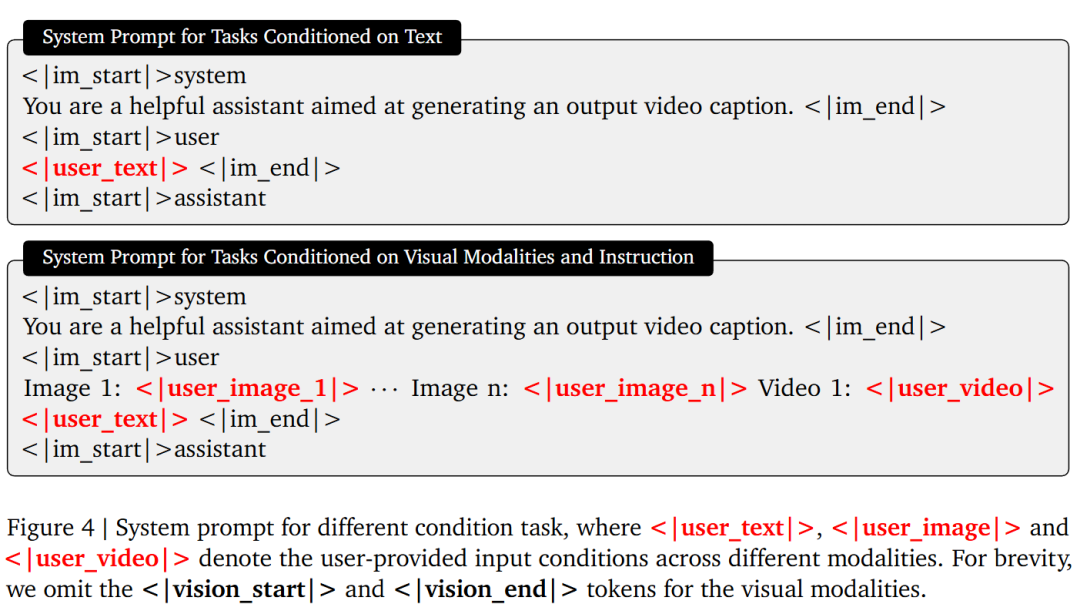
Interleaved Full-Modality Context
While VLM provides robust high-level multimodal semantics, it significantly compresses visual information, resulting in a lack of fine-grained spatial details and texture fidelity. Consequently, it cannot adequately handle tasks requiring precise structural control, such as local editing. To compensate for this information bottleneck, this work supplements VLM embeddings with VAE-encoded latent variables from all visual modalities. As shown in Figure 5, these VAE latent variables are arranged in the same order used in VLM, with noisy image/video latent variables placed at the end. However, simply concatenating image and video latent variables introduces ambiguity. To uniquely distinguish different visual conditions and align each VAE latent variable with its corresponding VLM features, this work reuses VLM's <|vision_start|> and <|vision_end|> embedding vectors. After projecting these embeddings through an MLP to match the MMDiT input dimension, they are used to mark the boundaries of each visual latent variable block. This explicit boundary marking serves as a strong positional cue, allowing the attention mechanism to correctly and effectively partition and interpret different visual condition inputs in the sequence.
Training a Unified Multi-Task Visual Generator
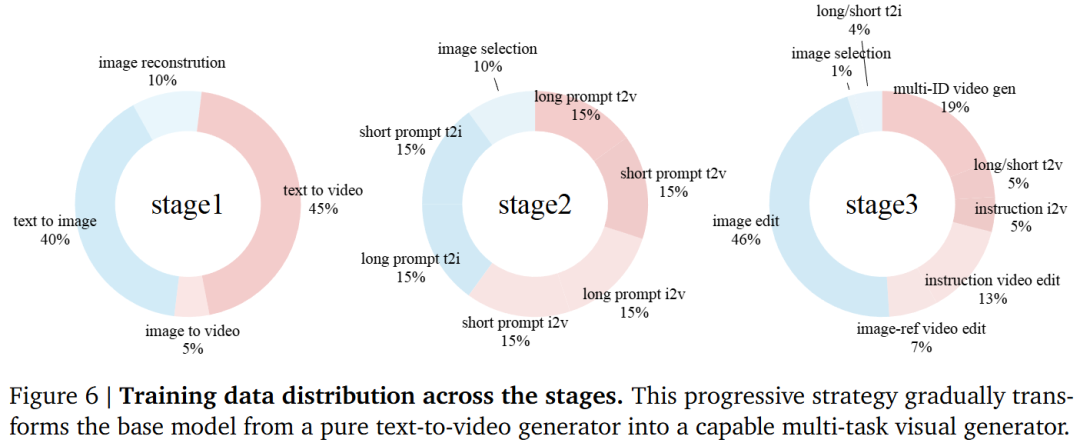
To build a unified visual generator supporting multimodal conditions, this work starts with a text-to-video diffusion model, as it already provides a strong temporal dynamic prior. To replace the original text encoder, the VLM's output space is first aligned with the model's native text encoder. During this initial stage, only a two-layer MLP connector is trained to map between the two embedding spaces. Modern text-to-video models typically rely on long, well-structured text prompts, while editing tasks often involve short instructions, creating a distributional gap. To bridge this gap, this work adopts a progressive training strategy, gradually transitioning the input condition distribution. Specifically, short prompts are treated as an intermediate form between long prompts and concise editing instructions. In the second stage, the model is trained with a mix of long and short prompts to ensure robustness to both forms, and MMDiT parameters begin to be updated at this stage. Once the model adapts to short prompt inputs, it proceeds to the final stage for full multi-task mixed training. The data mixing ratios for each stage are shown in Figure 6. This enables the model to smoothly transition from structured text-video conditions to instruction-based multimodal generation and editing.
Experiments
Experimental Setup
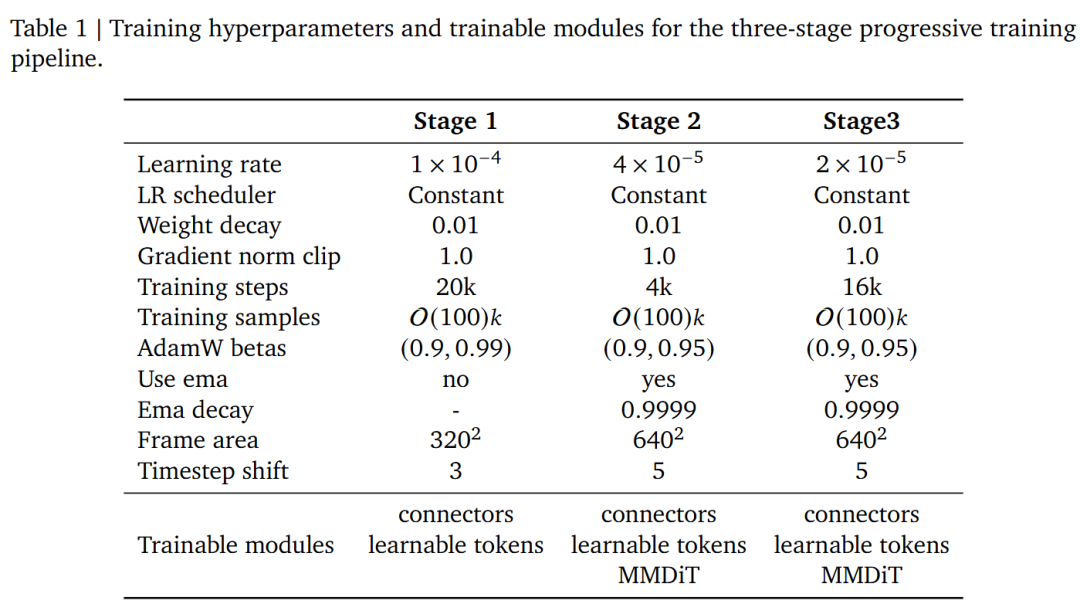
Base Model: Uses Qwen3VL-4B-Instruction as the multimodal encoder and HunyuanVideo as the visual generator for initialization. Data Strategy: Combines large-scale open-source image/video collections with high-quality distilled data. Employs a dynamic resolution bucketing strategy to balance computational load while maintaining original aspect ratios. Training Details: Divided into three stages, trained using DeepSpeed ZeRO-2. Dynamically adjusts the number of video frames and reference images based on the task.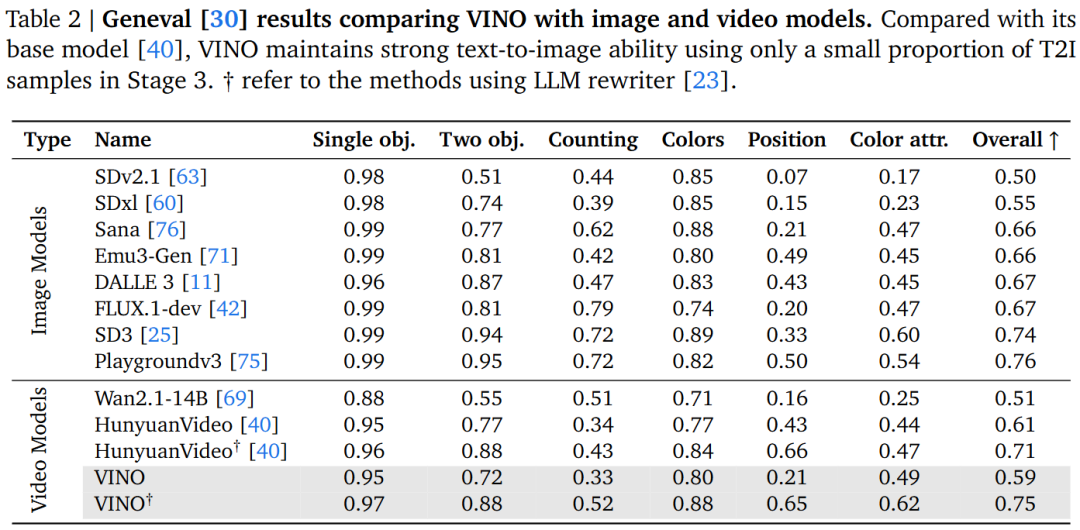
Visual Generation Performance
Preservation of Basic Capabilities: Despite the small proportion of standard text-to-image/text-to-video data in Stage 3, VINO's performance metrics on the Geneval and VBench benchmarks are highly comparable to those of the HunyuanVideo backbone network, proving that the training strategy effectively avoids catastrophic forgetting.
Reference-Based Generation Capabilities: On the OpenS2V benchmark (for subject-specific video generation), VINO demonstrates a clear advantage, effectively generating customized videos based on reference images.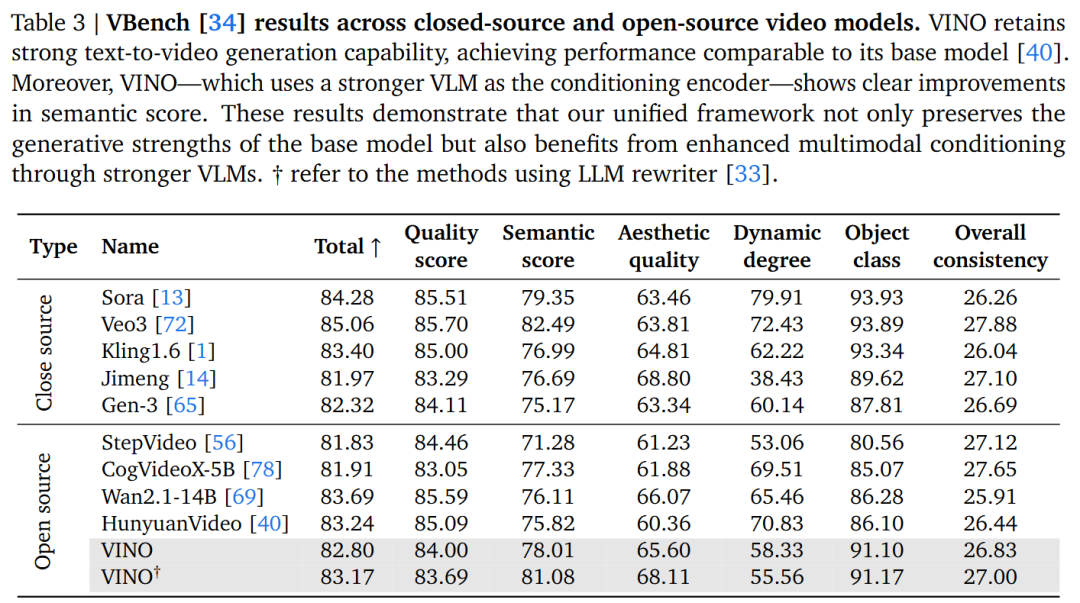
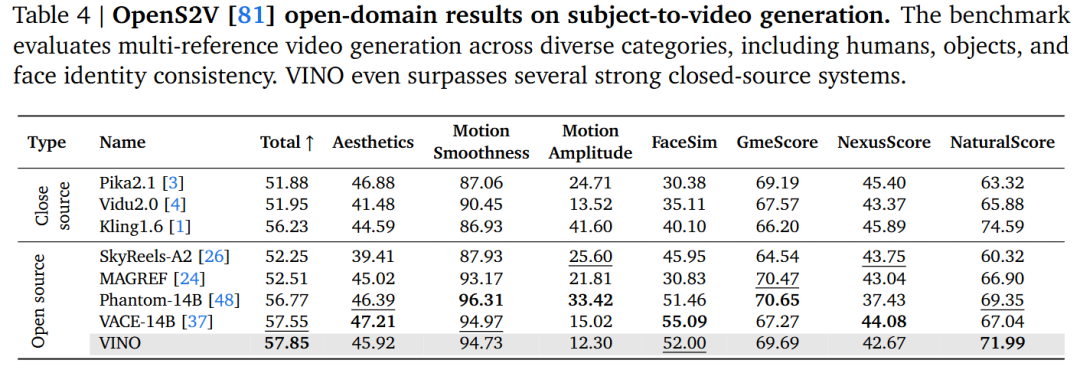
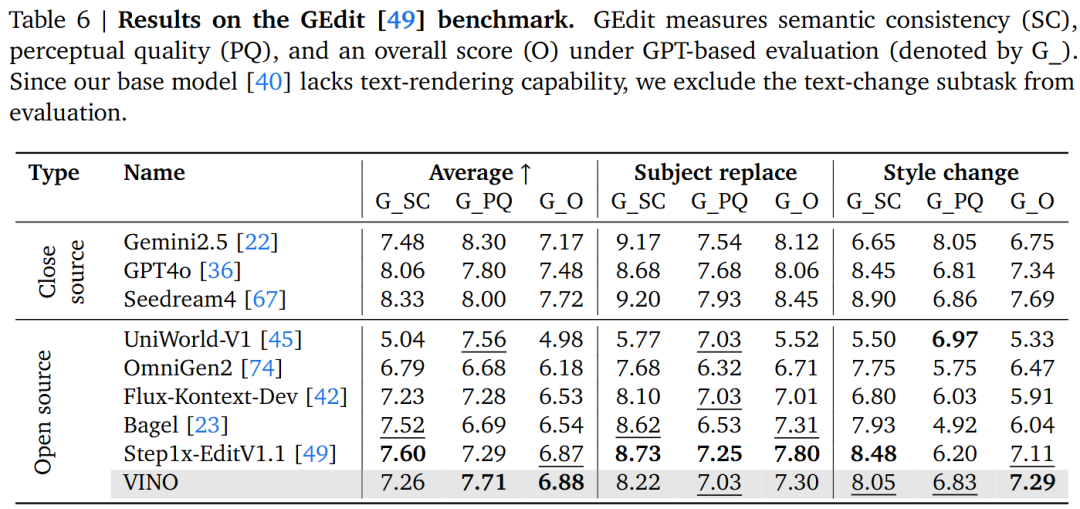
Visual Editing Performance
Image Editing: In the ImgEdit and GEdit benchmarks, VINO rapidly surpasses most open-source baselines in editing capabilities after undergoing only a small amount of training in Stage 3 (1k steps). This is attributed to the strong instruction-following ability brought by progressive training.
Video Editing: Compared to methods like VACE-Ditto, VINO demonstrates stronger instruction adherence and visual quality under the same inputs, capable of accurately executing complex operations such as 'object removal' and 'style transfer'. 

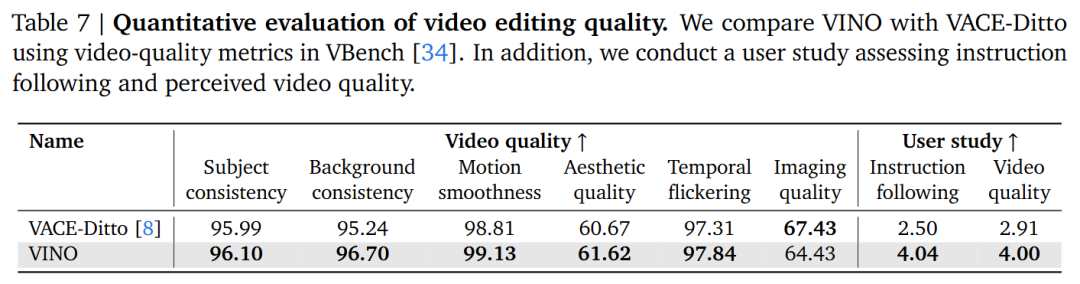
Ablation Experiments
Role of Learnable Tokens: Introducing learnable tokens significantly enhances training stability (smoother optimization curves) and improves the fidelity of multimodal conditions. Removing these tokens leads to increased gradient noise and degraded performance in tasks such as object removal/replacement.
Impact of Image CFG: Increasing the weight of Image Classifier-Free Guidance (Image CFG) enhances the preservation of the visual identity of reference images, but excessive weights can suppress the diversity of actions.
Role of Special Tokens (Boundary Markers): If special boundary tokens are not used in the VAE latent variable sequence, the model incorrectly entangles the temporal structure of videos with static image latent variables, resulting in noticeable artifacts in the first generated frame. 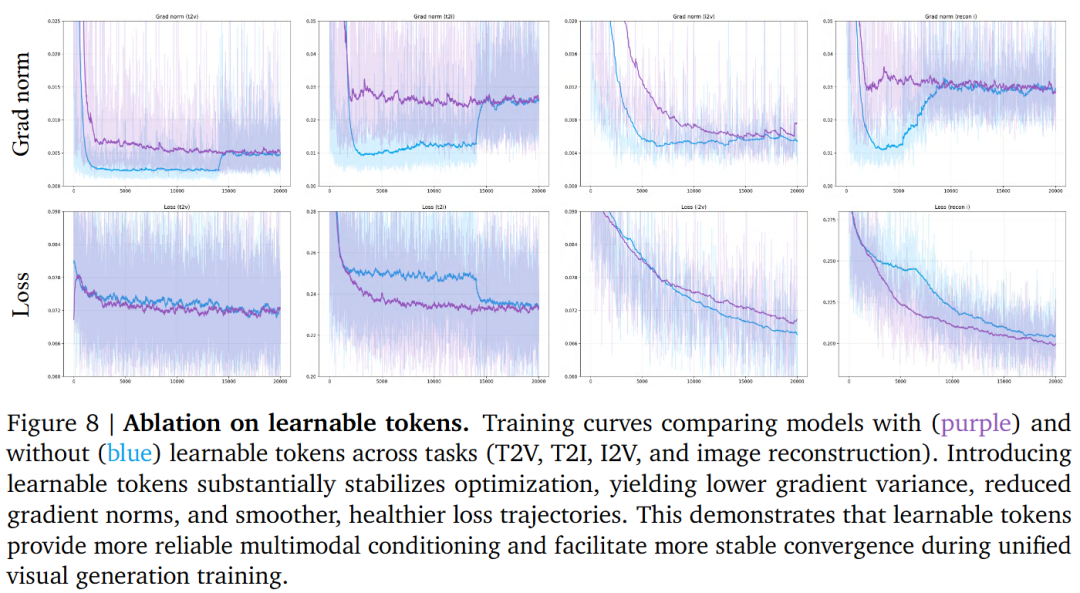
Conclusion
VINO is a unified visual generator capable of performing image and video generation and editing within a single framework. Through carefully designed model components and a conditional pipeline that accepts interleaved full-modal contexts, VINO seamlessly integrates heterogeneous inputs and handles a wide range of visual tasks. Extensive comparative experiments demonstrate the effectiveness and robust performance of our method. Additionally, the progressive training strategy employed in this work enables the model to acquire robust multitasking capabilities while preserving the generative advantages of the underlying video backbone network, ultimately yielding a coherent and unified visual generator. VINO provides a flexible, scalable foundation for many-to-many visual generation and paves the way for more general multimodal generation systems.
Limitations and Future Work:
Text Rendering Capability: The base model lacks text rendering capability, putting VINO at a disadvantage in benchmarks involving text editing. Editing Data Quality: The quality of existing instructional editing datasets is generally lower than that of large-scale generative datasets, with limited motion and simple structures, which may lead to a slight decline in visual fidelity or action richness after introducing editing tasks. Computational Cost: In MMDiT, the complexity of the full attention mechanism grows quadratically. Therefore, when reference videos and a large number of reference images are provided, inference latency increases significantly. Modal Limitations: The currently supported modalities are limited by the VLM. Exploring more powerful and comprehensive VLMs is a future research direction. References
[1] VInO: A Unified Visual Generator with Interleaved OmniModal Context
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’