Meituan's 'Multi-Agent Model' Shows Initial Potential, with the Pharmaceutical Industry Emerging as a Prime Target for the 'Large Model Tax'
 01/13 2026
01/13 2026
 497
497

01
Major Launches (New Models/Products/Open Source)
①Meituan Unveils EvoCUA: Open-Source Computer Operation Model Ranks 4th in OSWorld
Meituan has recently open-sourced its latest multimodal large model, EvoCUA, on GitHub and Hugging Face, selecting OSWorld as its benchmarking platform. OSWorld is a benchmark designed to evaluate the proficiency of multimodal agents in executing tasks within real computer operating systems. It requires models to accomplish complex tasks by observing screens and manipulating keyboards and mice, mimicking human behavior.
During testing, EvoCUA achieved a task completion rate of 56.7%, securing the top spot among open-source models and fourth place overall. It outperformed OpenCUA-72B, developed by the University of Hong Kong and Moonshot AI, by 11.7%, and Qwen3-VL-Thinking, developed by Alibaba, by 15.1%.
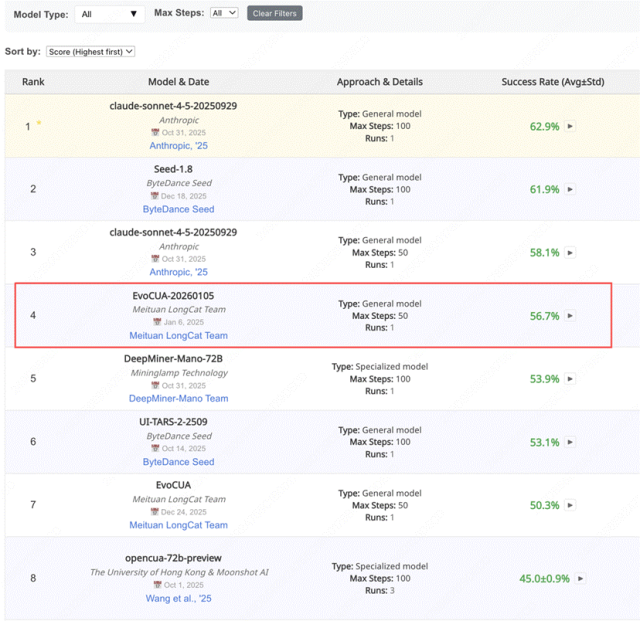
The model delivers high performance in just 50 steps, utilizing fewer parameters and demonstrating superior task execution efficiency. In terms of applicable scenarios, the model supports end-to-end automation, seamlessly operating common software such as Chrome, Excel, PPT, and VSCode through screen captures and natural language instructions, enabling the completion of intricate multi-round tasks.
According to the project introduction, the model's innovation lies in its unique data synthesis and training paradigm, which enhances computer usage capabilities while preserving general multimodal understanding.
Brief Comment:
This model is essentially akin to Manus, leaning more towards a multi-agent application than just a standalone model.
EvoCUA's notable performance improvement with fewer parameters and half the steps underscores the effectiveness of its training method, marking a significant advancement for open-source models in automation.
However, a 56.7% task completion rate remains confined to 'impressive lab performance' rather than 'real-world user satisfaction'.
It's noteworthy that EvoCUA's performance gap with the top three models—Anthropic's claude-sonnet-4.5 and ByteDance's Seed-1.8—is minimal. Although it cannot define scenarios, it can still claim a portion of the 'computer usage' scene's influence (discourse power) within the open-source ecosystem.
Meituan may not anticipate immediate commercialization of EvoCUA, but open-sourcing the model boosts its technological influence while optimizing internal processes such as office operations and maintenance, achieving a dual benefit.
②Anthropic Introduces Claude for Healthcare, Venturing into the AI Healthcare Industry
Following OpenAI and Alibaba's launches of AI healthcare products, Anthropic has also joined the fray. On January 12, Anthropic officially launched Claude for Healthcare, simultaneously expanding Claude for Life Sciences' capabilities, adding another significant player to the AI healthcare landscape.
Claude for Healthcare's customer base is categorized into three segments: healthcare institutions, insurance companies, and patients. It offers an HIPAA-compliant AI suite with the following core features:
Firstly, direct access to three major official databases: CMS policy library, ICD-10 coding system, and the National Provider Identifier Registry, supporting high-value tasks such as medical insurance pre-authorization reviews, claim appeals, and coding validation;
Secondly, new Agent skills: FHIR (international standard for healthcare information exchange) development support (enhancing healthcare system interoperability) and pre-authorization review templates (customizable for institutional processes);
Thirdly, personal health data integration: Users can authorize access to data sources such as Apple Health, Android Health Connect, and lab test reports. Claude generates concise interpretations, identifies health trends, and assists in preparing consultation questions. All data is not utilized for model training, and users retain full control throughout.
Claude has established connections to key platforms such as Medidata (clinical trial platform), ClinicalTrials.gov, ChEMBL (drug database), Open Targets, and Owkin (pathological image analysis), introducing new skills like automatic clinical trial protocol generation, regulatory document assistance, and trial progress monitoring.
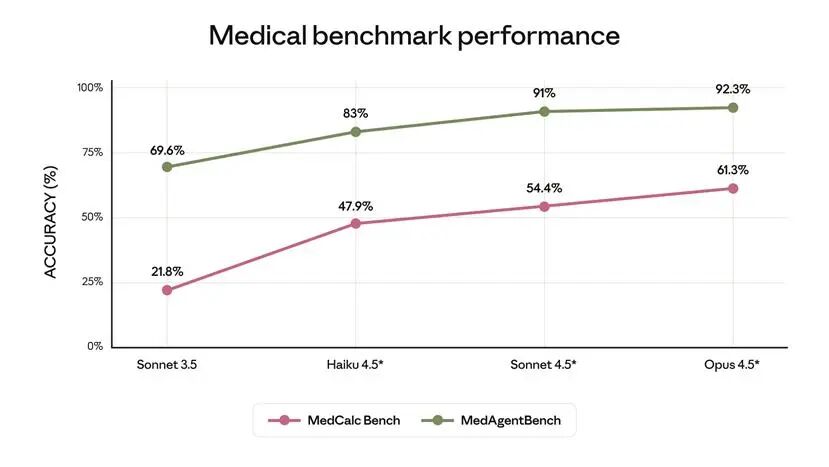
According to test results, Anthropic's latest product, Claude Opus 4.5, significantly outperforms in simulation tasks like MedAgentBench (Stanford healthcare agent evaluation) and MedCalc (medical calculations), while effectively reducing hallucinations in 'factual honesty' assessments, aligning more closely with clinical reliability requirements.
Brief Comment:
OpenAI, Anthropic, and Alibaba all focusing on AI healthcare in the short term indicates that AI application scenarios are gradually becoming well-defined. First AI programming, then AI healthcare, the application paradigm has successfully transitioned from Chatbot to Agent.
Compared to OpenAI's earlier AI healthcare products, Anthropic's involvement is deeper, penetrating multiple high-value workflows. However, implementation remains highly dependent on institutional IT system integration and faces issues like unclear responsibility boundaries, posing significant risks.
02
Technical Advancements (Papers/SOTA/Algorithms)
①Google's New Discovery: Repeating Prompts Enhances Accuracy of Mainstream LLMs
Recently, Google Research published a paper titled 'Prompt Repetition Improves Non-Reasoning LLMs,' which, though concise, reveals a surprising phenomenon:
Simply repeating a user's prompt once significantly enhances large models' performance across multiple tasks without enabling reasoning, increasing generation length, or extending response time.

The research team applied this method to seven mainstream models, including Gemini 2.0 Flash, Gemini 2.0 Flash Lite, GPT-4o-mini, GPT-4o, Claude 3 Haiku, Claude 3.7 Sonnet, and Deepseek-V3, across seven benchmark tests. The results showed:
1. In 70 experiments, repeating prompts positively improved model performance in 47 tests without causing degradation;
2. In tasks with specific structures like NameIndex, accuracy soared from 21% to 97%;
3. The effect was more pronounced in unfavorable structures like 'options first' or 'questions last'.
The research team believes this phenomenon stems from the model's reallocation of contextual attention during the prefill stage. Repeating prompts allows the model to obtain stronger semantic anchoring early in token processing, reducing understanding biases caused by positional shifts. When models are asked to 'reason step-by-step,' they implicitly complete similar information reinforcement, neutralizing the effect of repeated prompts.
In simpler terms, large models can only view input from left to right once during the answer preparation phase and cannot revisit it. If questions and key information are too far apart, it may lead to 'forgetting' or 'misunderstanding.' Repeating prompts allows large models to review the question once more, enabling all words to 'see' each other through attention mechanisms, reducing misjudgments caused by word order issues. However, when models are asked to 'think step-by-step,' users can observe the model's process of restating and organizing the question in the 'thinking section,' making manual prompt repetition unnecessary.
Brief Comment:
Current large models remain highly sensitive to prompt input order. This simple yet effective technique cleverly bypasses the model architecture's inherent limitations, transforming input into a fully connected semantic network and artificially repairing information flow asymmetry, which is quite reasonable from a vector space perspective. Perhaps not everyone thought of 'repeating once,' but no one treated it as a universal, quantifiable technical means to verify.
However, it's important to note that the models tested in this paper now appear somewhat outdated. Whether this technique works on the most advanced current models remains to be seen.
03
Computing Power and Infrastructure (Chips/Cloud/Data Centers)
①Google Urgently Removes Some Medical AI Overviews
Recently, the UK's Guardian newspaper uncovered in an investigation that Google's AI Overviews (a feature generating structured answers based on the Gemini large model) provided misleading data lacking individualized reference ranges in health queries like liver function tests. Google has quietly removed the AI summary feature for related keywords.
According to the Guardian's test results, when users searched for the normal range of liver function tests, AI Overviews provided a fixed interval without indicating that the range could vary significantly based on age, gender, ethnicity, or even testing equipment. Such 'one-size-fits-all' answers could lead patients to misjudge their conditions.
Currently, queries like 'liver function test' and similar phrases no longer trigger AI summaries, only displaying related search results. Google subsequently responded, stating that its internal clinical team, after review, believed 'most information provided was not incorrect and supported by high-quality websites,' indicating continuous improvement but refusing to comment on the feature's removal. The British Liver Trust stated that temporarily shutting down individual queries only 'treats symptoms, not the root cause,' and that AI Overviews' issues in the medical field remain unresolved.
Brief Comment:
Without strict medical knowledge graphs, clinical review processes, and robust reasoning capabilities, directly using general large models for health information distribution still poses significant safety risks.
Google's AI Overviews provided highly absurd answers like 'using glue to stick cheese on pizza' and 'eating stones for nutrition' in 2024. Now, with Google's growing influence, the risks of outputting health advice in 'authoritative summary' form are surging. In contrast, OpenAI has chosen to focus on daily health companionship rather than diagnostic scenarios. At this stage, AI healthcare's priority is not professionalism but risk avoidance.
-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’