Autoregressive New SOTA! Baidu VideoAR: The First Video VAR Framework, Reducing Inference Steps by 10x, Comparable to Diffusion Models
 01/13 2026
01/13 2026
 573
573
Analysis: The AI-Generated Future 
 Figure 1. VideoAR generates high-fidelity and temporally consistent videos through text prompts.
Figure 1. VideoAR generates high-fidelity and temporally consistent videos through text prompts.
Key Highlights
First Video VAR Framework: VideoAR, the first large-scale framework applying visual autoregressive modeling to video generation, combines multi-scale next-frame prediction with autoregressive modeling.
Spatiotemporal Decoupling Modeling: Successfully decouples spatial and dependency relationships, using intra-frame VAR modeling for spatial content and causal next-frame prediction for temporal dependencies.
Innovative Consistency Mechanisms: Multi-scale Temporal RoPE, Cross-Frame Error Correction, and Random Frame Masking effectively mitigate error propagation in long-sequence generation and stabilize temporal consistency.
SOTA Performance: New SOTA for autoregressive models. Reduces FVD from 99.5 to 88.6 on UCF-101, with inference steps reduced by over 10x.
Comparable to Diffusion Models: Achieves a VBench score of 81.74, competitive with diffusion models one order of magnitude larger in parameters.
Problems Addressed
Inefficiency of Diffusion Models: Existing mainstream video generation models (diffusion and flow matching) are computationally intensive and difficult to scale due to their reliance on bidirectional denoising of the entire time series.
Limitations of Existing AR Models:
Modeling Mismatch: Simple 'next token prediction' does not align well with the intrinsic structure of video data (spatial vs. temporal).
Error Propagation: Autoregressive modeling of long sequences leads to severe error accumulation, causing quality degradation.
Poor Controllability: Existing sampling strategies lack fine-grained control over video dynamics and duration.
Proposed Solution
New Paradigm: Adopts 'Next-Scale Prediction' for intra-frame generation, combined with 'Next-Frame Prediction' for inter-frame dependencies.
3D Multi-Scale Tokenizer: Extends the 2D VAR encoder-decoder into a 3D architecture and initializes it with pre-trained 2D-VAR weights, efficiently capturing spatiotemporal dynamics.
Training Strategy: Employs a multi-stage pre-training process, progressively aligning spatial and temporal learning at increasing resolutions and durations.
Applied Technologies
3D-VAR Encoder/Decoder: Encodes spatiotemporal dynamics into multi-scale tokens.
Multi-scale Temporal RoPE: Replaces standard positional encoding to enhance temporal awareness and bit-level prediction accuracy.
Cross-Frame Error Correction: Increases flip ratios over time and inherits errors during cross-frame transitions, training the model to recover from perturbations.
Random Frame Masking: Weakens excessive reliance on the previous frame, alleviating over-memorization issues.
Spatiotemporal Adaptive Classifier-Free Guidance (CFG): Adjusts guidance coefficients along scales and timesteps to balance semantic fidelity and motion dynamics.
Achieved Effects
UCF-101: Achieves a gFVD of 88.6 (VideoAR-XL), significantly outperforming the previous best AR model (PAR-4×, 99.5 gFVD).
VBench: The large-scale model (VideoAR-4B) obtains an overall score of 81.74, reaching SOTA in semantic scoring, comparable to leading diffusion models like CogVideo and Step-Video.
Efficiency: Inference speed is 13x faster than existing AR baselines (requiring only 30 steps).
Capability: Generates high-fidelity, temporally coherent videos (e.g., 4-second videos at resolution) and supports image-to-video and video continuation.
Methodology
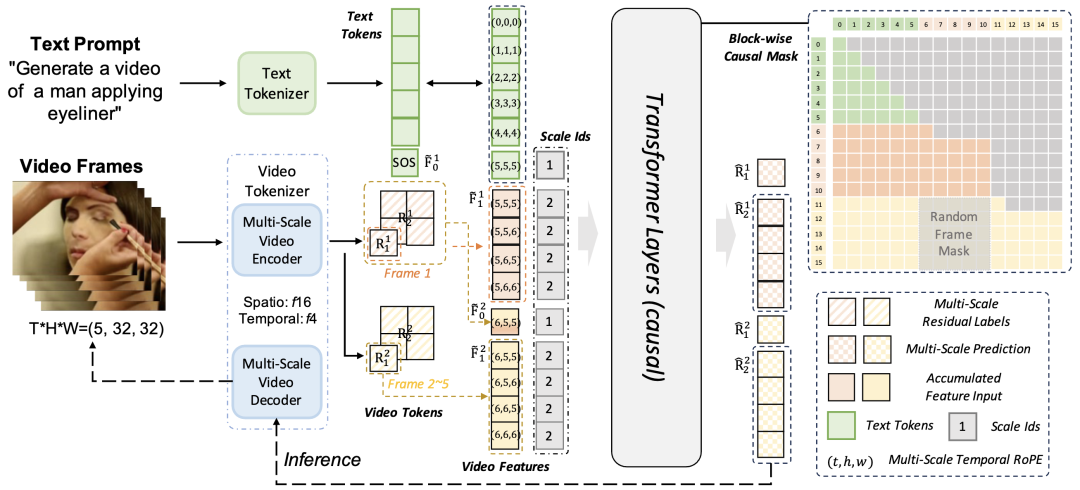 Figure 2. Overall framework for video augmented reality. Given a text prompt, video frames are first compressed into a series of spatiotemporal tokens by a multi-scale causal 3D tokenizer. Each frame is represented by multi-scale residual maps, which are autoregressively predicted by a transformer with chunked causal masking. Input embeddings combine text tokens, accumulated video features, and scale embeddings, while the proposed multi-scale temporal RoPE encodes positional information with temporal, spatial, and scale awareness. Random frame masking is applied during training to mitigate exposure bias and enhance long-term consistency. Finally, a multi-scale video decoder reconstructs video frames from predicted residuals.
Figure 2. Overall framework for video augmented reality. Given a text prompt, video frames are first compressed into a series of spatiotemporal tokens by a multi-scale causal 3D tokenizer. Each frame is represented by multi-scale residual maps, which are autoregressively predicted by a transformer with chunked causal masking. Input embeddings combine text tokens, accumulated video features, and scale embeddings, while the proposed multi-scale temporal RoPE encodes positional information with temporal, spatial, and scale awareness. Random frame masking is applied during training to mitigate exposure bias and enhance long-term consistency. Finally, a multi-scale video decoder reconstructs video frames from predicted residuals.
The VideoAR framework combines the advantages of visual autoregressive (VAR) modeling and next-frame prediction to achieve efficient and high-quality video generation. The process consists of two main parts. First, a **3D Video Tokenizer** is introduced, which compresses raw videos into compact discrete representations while preserving spatial and temporal structures. This tokenizer serves as the foundation for scalable and efficient modeling. Second, an autoregressive video model based on multi-scale residual prediction is designed, where temporal consistency is further enhanced through training strategies proposed in this work.
Visual Tokenizer
3D Architecture: To better capture spatiotemporal correlations, a causal 3D convolutional architecture is employed, enabling the tokenizer to process both images and videos within a unified framework. Specifically, a 3D convolutional encoder with temporal downsampling compresses the input video into a compact spatiotemporal latent representation , where denotes the temporal compression factor. This design leverages inherent redundancies between adjacent frames, achieving efficient video modeling while maintaining fidelity.
To further scale to long video generation, all non-causal temporal operations (e.g., temporal normalization) are removed from the encoder and decoder, ensuring that each latent feature depends only on past frames. This causal design enables inference for extremely long videos to be performed chunk-by-chunk without any performance loss compared to full-sequence inference.
Quantization: Considering the temporal causal modeling in this work, a time-independent quantization method is utilized, where each frame is processed by an independent multi-scale quantizer.
Training: To achieve efficient and stable training of the video tokenizer, a 3D inflation strategy is adopted, initializing the model from a well-trained image tokenizer. This initialization provides a strong spatial prior, significantly stabilizing the optimization process and accelerating convergence. Specifically, following the inflation process in [34], the weights of the last slice in the temporal dimension of the 3D CNN are filled with those of the image tokenizer, while the remaining temporal parameters and discriminator are randomly initialized.
The tokenizer is trained using a set of standard complementary objective functions. Reconstruction loss, perceptual loss, and commitment loss are applied to each frame. Following [33], LeCAM regularization is used to improve stability, and entropy penalty is employed to encourage codebook utilization.
The overall training objective is formulated as follows:
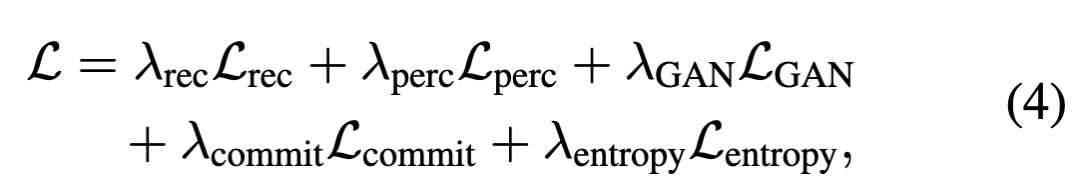
where represents the balancing weights for different objectives. This training scheme ensures that the tokenizer learns compact and expressive spatiotemporal representations, facilitating reconstruction fidelity and downstream autoregressive video generation.
Autoregressive Video Modeling
Extension to 3D Architecture: Based on the spatiotemporal features extracted by the 3D tokenizer, the visual autoregressive (VAR) paradigm is extended from images to videos. Specifically, the transformer autoregressively predicts the residuals of the -th frame based on all previously generated frames, coarser scales of the current frame, and text prompts:
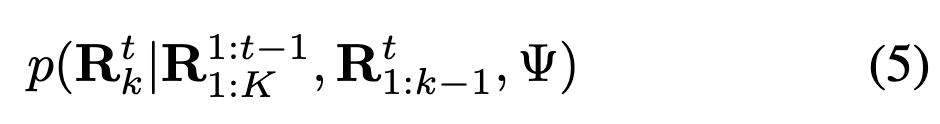
where denotes the multi-scale residual maps of all past frames, and represents the coarser-scale residuals already generated for the -th frame. The input features for the -th frame at scale are constructed as follows:
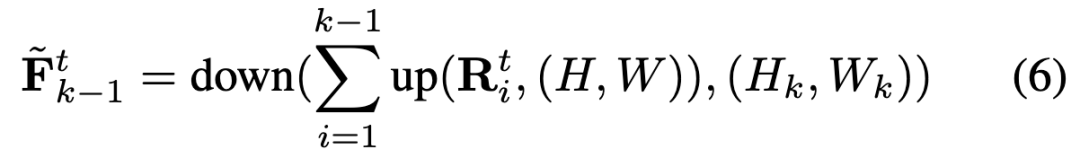
where and denote spatial upsampling and downsampling, respectively.
To initialize generation, the features of the first frame at the first scale ( in Figure 2) are set to a special token embedding, enabling text-conditioned generation. For subsequent frames (), the features at the first scale () are initialized from the accumulated features of the previous frame, injecting temporal context into the generation of the next frame.
Multi-scale Temporal RoPE: To better capture spatiotemporal dependencies, multi-scale temporal RoPE is introduced, an extension of Rotary Positional Embedding (RoPE) that decomposes the embedding space into three axes: time, height, and width. The design principles of multi-scale temporal RoPE are threefold: (1) compatibility with the native RoPE formulation for text tokens; (2) explicit temporal awareness; and (3) spatial consistency across frames for multi-scale inputs.
Given a multimodal input containing text prompts and video tokens, text tokens are assigned the same time, height, and width indices as video tokens to maintain compatibility with RoPE. Let denote the token of the -th frame at scale and spatial position , where and . The positional encoding is defined as:
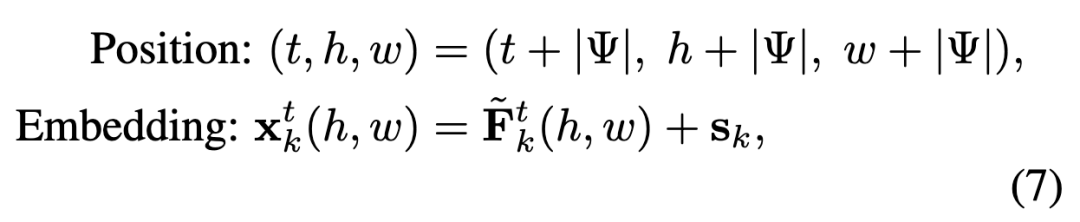
where the spatial index remains consistent across frames, while the temporal index increases with to maintain order. Additionally, a learnable scale embedding is added to distinguish between coarse-to-fine scales during autoregressive generation.
Temporal Consistency Enhancement: Autoregressive video generation suffers from error accumulation: as increases, quality degrades due to training-testing discrepancies. Two complementary strategies are employed to mitigate this issue: cross-frame error correction with a time-ramped schedule and random frame masking with a causal sliding window.
Cross-Frame Error Correction: Following the bitwise formulation in Infinity, each token in is represented as bits . To address error propagation accumulation along extended frame sequences, **time-dependent corruption** is introduced, injecting perturbations with gradually increasing flip ratios to simulate inference conditions (see Figure 3).
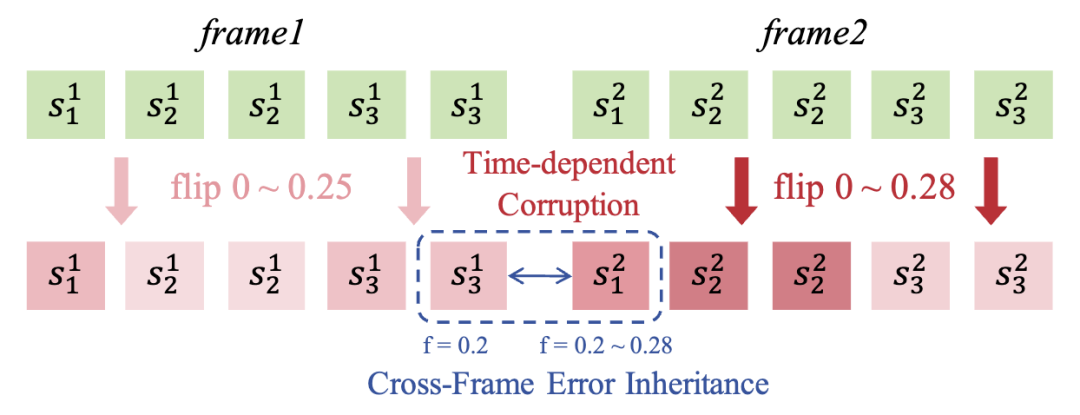 Figure 3. Proposed cross-frame error correction in this work.
Figure 3. Proposed cross-frame error correction in this work.
Furthermore, since the errors at the final scale of each frame inevitably propagate to the first scale of the next frame, a **cross-frame error inheritance** mechanism is proposed. Specifically, the flip ratio at the first scale of each frame is initialized within a range above the flip ratio at the final scale of the previous frame. By forcing the model to correct these inherited perturbations at the first scale, the training process enhances temporal robustness and significantly mitigates the impact of errors from previous frames on subsequent generation.
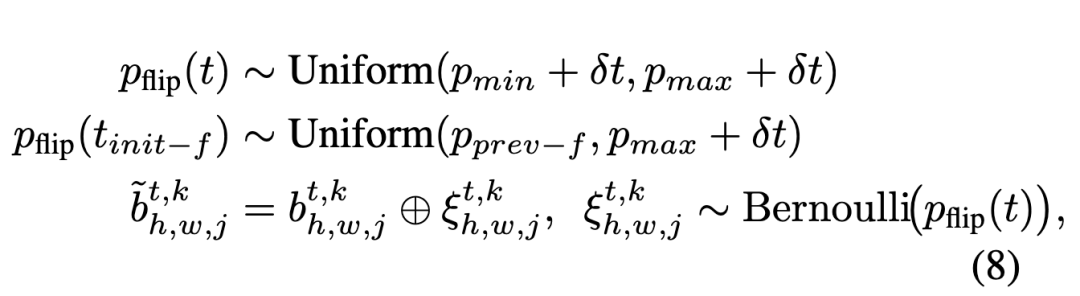
where denotes exclusive OR, and represents the factor for increasing the flip range. The model is conditioned on the corrupted history and supervised by a self-correcting objective with requantized errors, improving robustness to compound errors.
Random Frame Masking: Let the attention window size be . For each step , a random causal context is constructed, where are independently and identically distributed. Let denote the text keys/values, and denote the video keys/values from frames in . The attention output for the -th frame is:
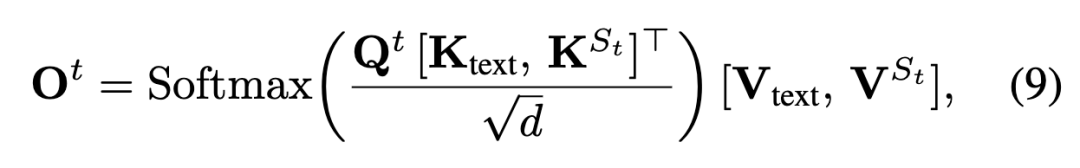
This approach suppresses excessive reliance on distant frames while preserving necessary temporal context.
Multi-Stage Training Pipeline: Following Infinity, the training objective of this work is defined as the bitwise cross-entropy loss between predicted residual maps (tilde{Y}_t) and ground truth (Y_t). To achieve robust temporal consistency and high-quality synthesis in long-duration, high-resolution videos, this work adopts a progressive multi-stage training strategy.
Stage I: Joint pre-training on large-scale image and low-resolution video datasets enables the model to acquire fundamental spatiotemporal representations while benefiting from efficient convergence.
Stage II: Continued training on higher-resolution image and video data enhances fine-grained visual fidelity and temporal coherence.
Stage III: Long-video fine-tuning using only high-resolution video datasets enables the model to capture extended motion dynamics and long-range temporal dependencies. This hierarchical training scheme effectively balances training stability, scalability, and generation quality across diverse video domains.
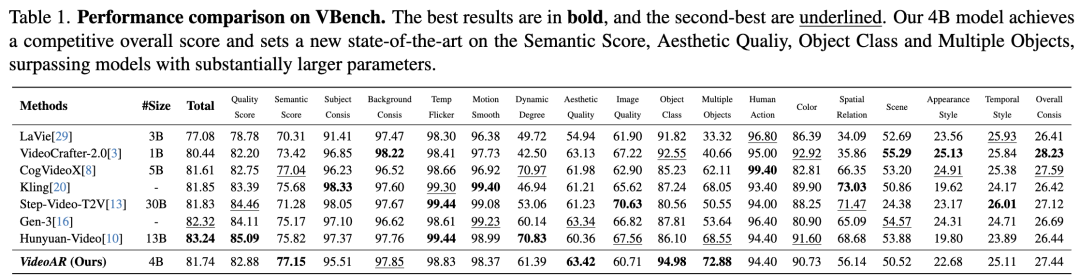
Temporal-Spatial Adaptive Classifier-free Guidance (CFG): During testing, this work leverages cached states to perform causal decoding on (tilde{Y}_{ Experiments Experimental Setup Datasets: This work conducts experiments on diverse benchmarks, covering low-resolution toy datasets and high-resolution real-world long-video generation. For short video generation, this work uses UCF-101 (containing 8K video clips across 101 action categories) as a standard benchmark for human action modeling. For long videos and open-domain scenarios, this work performs large-scale pre-training and evaluation on proprietary internal datasets. All videos are uniformly resized to 256² pixels and temporally upsampled to 16 frames depending on the dataset. Evaluation Metrics: This work evaluates models from two dimensions: reconstruction quality and generation quality. For reconstruction, this work reports Fréchet Video Distance (rFVD), which directly reflects the fidelity of the learned video tokenizer. For generation quality, this work measures gFVD on a held-out human-centric test set from UCF-101. Additionally, to assess real-world generation performance, this work evaluates on the standard VBench, which provides a comprehensive set of perceptual and temporal metrics designed specifically for video generation models. Experimental Results Video Reconstruction: The effectiveness of autoregressive video generation models largely depends on the quality and compactness of their underlying video tokenizers. This work assesses this aspect by reporting reconstruction Fréchet Video Distance (rFVD). Table 2 presents a comparative analysis on the UCF-101 dataset, demonstrating that our model achieves an exceptional balance between compression efficiency and reconstruction fidelity. Our VideoAR-L tokenizer employs aggressive 16× spatial compression, encoding video clips into compact 16×16 potential token grids. Compared to recent state-of-the-art video tokenizers like MAGVIT and OmniTokenizer (both operating at only 8× compression), this design reduces sequence length by 4×. Despite the significant reduction in token density, our tokenizer maintains outstanding reconstruction quality, achieving an rFVD of 57.8, on par with MAGVIT (58). This result highlights the effectiveness of our tokenizer in preserving fine-grained spatial and temporal structures, laying a strong and efficient representational foundation for downstream autoregressive video generation. Video Generation on UCF-101: Our VideoAR framework establishes a new state-of-the-art (SOTA) on the UCF-101 dataset, marking a paradigm shift in achieving superior generation quality and unprecedented inference efficiency. As shown in Table 3, our 2B-parameter model, VideoAR-XL, achieves a new best FVD of 83.2, surpassing the previous leading autoregressive model, PAR-4x (91.5), by 11%. Even our smaller 926M model, VideoAR-L, outperforms it with an FVD of 90.3. However, the most significant advancement lies in inference speed: requiring only 30 decoding steps (a reduction of over 10×), VideoAR-L generates videos in just 0.86 seconds, achieving over 13× faster inference than PAR-4x. This dual improvement directly stems from our architectural innovations. High-fidelity spatial details are preserved through intra-frame visual autoregression, while robust temporal consistency is guaranteed. Real-World Video Generation: To further validate the effectiveness and scalability of our method, we pre-trained a 4B-parameter VideoAR model on challenging real-world video generation tasks. As shown in Table 1, our model achieved an overall VBench score of 81.74, demonstrating performance comparable to or even better than current state-of-the-art models with significantly larger scales, such as the 30B Step-Video-T2V and 13B Hunyuan-Video. A fine-grained analysis of VBench metrics reveals our model's key strengths. Notably, VideoAR achieved a new SOTA Semantic Score (SS) of 77.15, surpassing all competitors. This result underscores its exceptional ability to maintain precise text-to-video alignment. While maintaining competitive general visual quality metrics, such as Aesthetic Quality (AQ) and Overall Consistency (OC), these superior performances in semantics and motion clearly demonstrate our model's unique advantages. Qualitative results (Figure 4 and supplementary materials) further confirm our quantitative improvements. VideoAR consistently generates visually compelling and semantically coherent videos, spanning imaginative artistic stylizations, high-fidelity natural scenes, and dynamic human actions with strong temporal consistency. Critically, these results confirm that our VideoAR strategy provides a compelling alternative to diffusion-based paradigms. It achieves SOTA-level performance, particularly in semantic control and motion depiction, while offering strong potential for improved scalability and significantly higher inference efficiency. Image-to-Video and Video-to-Video Generation: As an autoregressive video generation model, our proposed VideoAR can directly extend future frames from preceding content (including initial images and sequence frames) without external fine-tuning. For evaluation, we sampled several test cases from VBench-I2V. We demonstrate multiple examples of image-to-video (I2V) and video-to-video (V2V) generation, where VideoAR achieves single-shot or multi-shot continuous video generation. As shown in Figure 5, VideoAR-4B accurately follows semantic prompts aligned with input images across various settings, including object motion control and camera trajectory adjustments. For video continuation tasks, VideoAR can generate natural and consistent content over multiple iterations, ultimately producing long videos exceeding 20 seconds in duration. Ablation Studies We conducted comprehensive ablation studies on the UCF-101 dataset. All models were trained for a fixed 1,000 steps, sufficient to reveal clear trends in model performance. Effect of Multi-scale Temporal RoPE: Our first enhancement replaces standard positional encoding with multi-scale temporal RoPE. As shown in the second row of Table 4, this single modification reduces FVD from 96.04 to 94.95. This result underscores the importance of rotational relative position encoding for modeling complex spatiotemporal dynamics in video data, thereby improving inter-frame consistency. Effect of Temporal-Consistency Enhancement: Next, we evaluated our proposed cross-frame error correction mechanism, which consists of two synergistic components. (1) We first activated Time-dependent Corruption, a data augmentation strategy that simulates inference-time conditions during training. This addition further reduced FVD to 93.57. (2) Building on this, we incorporated Error Inheritance Initialization, which encourages the model to correct inherited perturbations for improved future predictions. This final step produced our complete model, achieving a SOTA FVD of 92.50. Further ablation of Random Frame Masking was conducted on our large-scale real-world dataset, as strong augmentation on the smaller UCF-101 dataset might hinder model convergence. As shown in Table 5, incorporating this technique during the 256px training phase improved the overall VBench score from 76.22 to 77.00. Discussion Comparison with Concurrent Work InfinityStar: This work highlights several key differences compared to InfinityStar. (1) Spatio-temporal Modeling Paradigm: InfinityStar employs a 3D-VAR formulation where each generation block operates over temporal windows of frames. In contrast, our VideoAR adopts a next-frame prediction paradigm combined with multi-scale modeling within each frame. This design enables fine-grained spatial modeling through structured coarse-to-fine generation while maintaining temporal consistency through explicit frame-by-frame prediction. (2) Training Strategy: InfinityStar is fine-tuned from a well-established 8B-scale image generation foundation model, benefiting from strong pre-training priors. In contrast, our VideoAR is trained from scratch using joint low-resolution image-video data, focusing on learning unified spatiotemporal representations ab initio. (3) Training Scale and Sequence Length. Additionally, VideoAR employs a relatively moderate sequence length for training, primarily due to practical training considerations at this stage. Therefore, the temporal coherence of long horizons has not been thoroughly explored. However, the proposed framework has no inherent limitations on sequence length and is fully compatible with training involving longer contexts. As the training scale and sequence length increase, this work anticipates further gains in long-term consistency. Conclusion VideoAR, a novel scalable autoregressive video generation paradigm based on the principle of next-scale prediction. By extending the VAR framework to the video domain, VideoAR unifies spatial and temporal modeling through a causal 3D tokenizer and a Transformer-based generator. The proposed multi-scale temporal RoPE enhances spatiotemporal representation learning, while cross-frame error correction and random frame masking effectively mitigate cumulative errors and improve the stability of long video generation. Extensive experiments demonstrate that VideoAR not only achieves state-of-the-art gFVD (88.6) and VBench (81.7) scores but also offers a 13-fold improvement in inference speed compared to existing AR baseline models. These findings highlight autoregressive modeling as a practical and powerful alternative to diffusion-based methods, paving the way for efficient and large-scale video generation. References [1] VideoAR: Autoregressive Video Generation via Next-Frame & Scale Prediction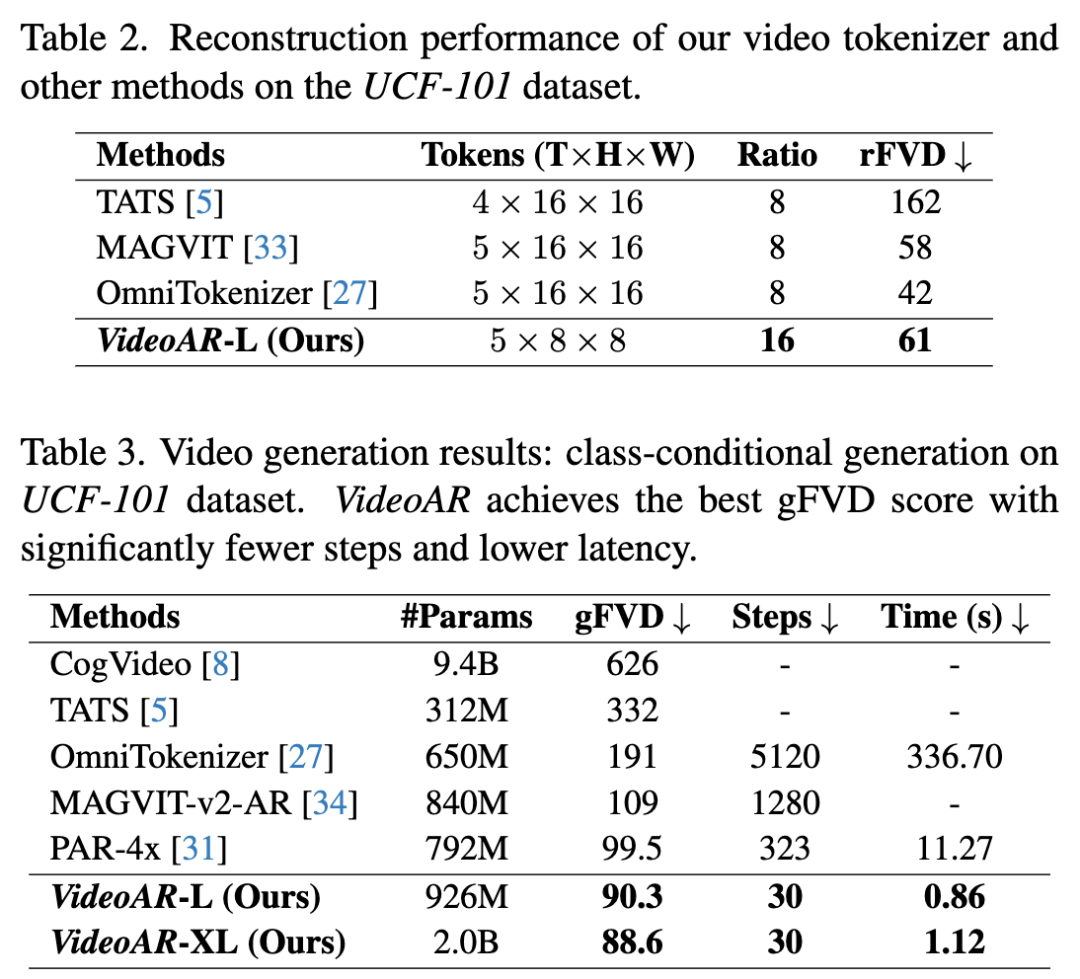





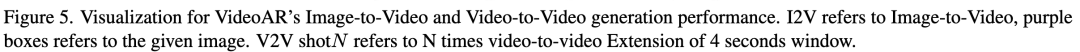


-
![]()
Jitian Xingzhou: A Pioneer in Optical Payloads Secures Hundreds of Millions in Series B Funding!
-
![]()
Orders Secured Through to the Second Half of the Year! The Rationale Behind the 'Surge' in Demand for This Company’s Optical-Grade Base Films
-
![]()
Beyond Patents: The Retail Rivalry of Insta360 and DJI Unfolds
-
![]()
180 Billion Market Cap Vanished! How Did Seres Fall So Far?
-
![]()
Blockbuster! Domestic storage takes the global double crown for the first time, from an AI company
-
![]()
China Spearheads Formulation! World's Pioneering Global Technical Regulation for Automated Driving Systems Greenlit and Unveiled
-
![]()
Farewell to Pulsed Support Policies: Three Major Auto Policy Directions from Multiple Departments Take Effect on the Same Day
-
![]()
Embercore AI’s Accelerated Funding: The Robot Industry’s Shift Toward ‘Learning Systems’