Embodied AI: It's Time to Break Free from the 'China Innovates First, Overseas Markets Popularize' Cycle
 02/02 2026
02/02 2026
 573
573

Editor's Note:
Making AI think and act like humans was once the ultimate fantasy in science fiction. Today, with the leap of general-purpose large models into the physical world, the embodied AI brain has become the ultimate high ground in technological competition.
Yet the evolution of technology is never a smooth path. Data scarcity, generalization challenges, and even the slightest hallucinations create a chasm between demos and real-world deployment.
As end-to-end becomes an industry buzzword and VLA models continuously push boundaries, we need sober reflection: What is the optimal architecture for embodied AI brains? How can the flywheel of computational power and data drive the emergence of physical intelligence?
On the eve of this technological paradigm shift, Xinghe Frequency proudly presents the "Embodied AI Brain" series. We will delve into evolving technological paradigms, cut through the hype of technical concepts, return to the essence of systems and architectures, and document the evolutionary journey of agents from having bodies to possessing wisdom.
Few know that the original research on Scaling Law came from Baidu, not OpenAI.
In 2014, during his time researching AI at Baidu's North American lab, Anthropic founder Dario Amodei discovered the holy grail of large model development—the Scaling Law.
After leaving Baidu, Amodei joined OpenAI, where Scaling Law first bore fruit in the U.S., leading to the creation of GPT-3.5.
Yet Baidu had already extensively discussed scaling phenomena in machine translation and language modeling in its 2017 paper, "Deep Learning Scaling is Predictable, Empirically."

At the time, Baidu researchers used LSTM instead of Transformers and didn't label their findings as 'Laws.'
Later, ChatGPT 3.5's debut brought global recognition to OpenAI and sparked the LLM boom.
This chapter in Baidu's history became a source of regret for Yan Junjie, founder of MiniMax, who joined Baidu around the same time as Amodei.
A decade later, as the global AI spotlight shifts from large language models to the more challenging embodied AI, history seems to be repeating itself.
Chinese researchers have had early insights into key architectures, yet overseas teams often receive the credit and applause.
This time, however, China's embodied AI players are determined to rewrite the narrative.
From VLA models and world models to reinforcement learning, they are building a complete innovation ecosystem in critical technology areas, participating in the competition over the nature of intelligence in a more systematic and profound way.

VLA: Empowering Robots with Autonomous Brains
The core value of VLA models lies in breaking the passive dilemma of traditional robots, transforming them from task-specific puppets into intelligent agents capable of autonomous understanding and decision-making.
Chinese teams have long been at the forefront of innovation in this field, though their achievements have been overshadowed by overseas hype.
Early robotics relied on two primary control modes: fixed-program programming and modular control.
Both approaches were essentially human-defined rule systems where robots acted as passive tools, lacking proactive understanding capabilities.
The breakthrough of LLM and VLM technologies enabled a paradigm shift—understanding before generation—allowing models to learn semantics, common sense, and reasoning from large-scale text and image data.
This sparked a technological intuition: If one model could understand language and images, could actions be integrated into the same framework, enabling direct mapping of perceived information into actions?
The rise of VLA models was thus an inevitable result of LLM and VLM technological spillover.
In July 2023, Google DeepMind introduced the RT-2 model, formally proposing the VLA concept.
RT-2 revolutionized robot programming by eliminating the need for engineers to write complex control codes for each task. Instead, robots could autonomously generate appropriate actions through observation and learning.
While RT-2 and similar VLA models can handle basic tasks, two pain points remain: insufficient reasoning for complex tasks and prohibitively high computational costs for fine-tuning and inference.
In June 2024, Chinese company AIZERO, in collaboration with Peking University and other institutions, introduced the state space sequence model Mamba into VLA architecture, creating the lightweight RoboMamba.
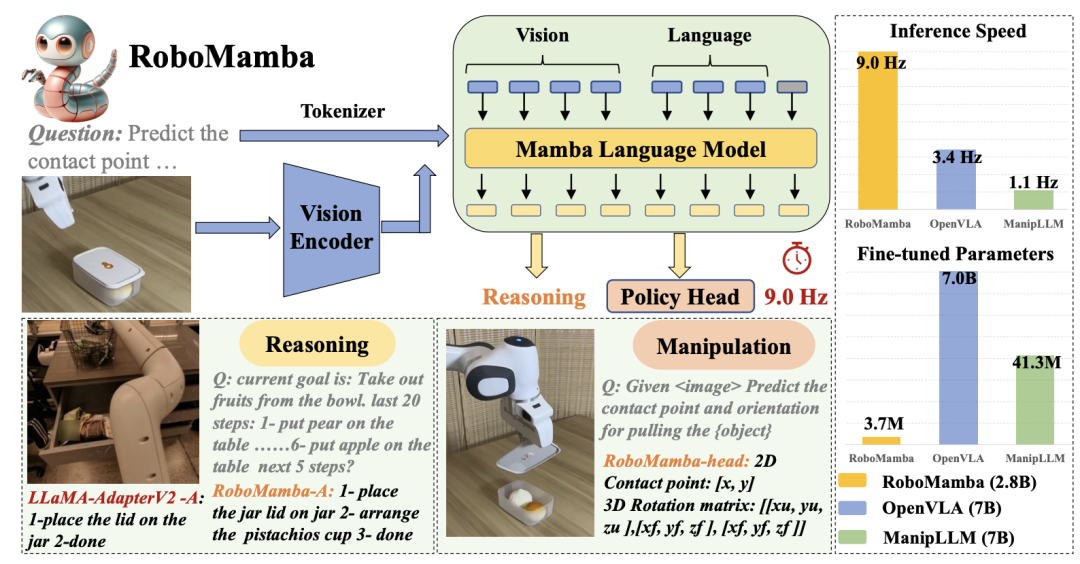
Compared to previous VLA models, RoboMamba reduced complexity while significantly enhancing long-sequence reasoning capabilities, achieving a dual improvement in efficiency and reasoning generalization.
This paper was selected for NeurIPS 2024, marking the first international voice from a Chinese embodied AI company in the VLA field.
Today, VLA models have become the mainstream approach for embodied AI brain development. Within this consensus, many players are exploring specialized paths.
In the end-to-end VLA model space, players are generally divided into two camps: hierarchical end-to-end and pure end-to-end.
Representatives of the former include Figure AI, Star Era, Galactica, and Stardust Intelligence, while the latter features Physical Intelligence and Independent Variable Robotics.
It's important to clarify that hierarchy represents an implementation path within end-to-end systems; the two are not oppositional.
The core of pure end-to-end lies in using unified or few large models to directly map perception to action decisions. Hierarchical end-to-end employs System 1 (fast) and System 2 (slow) brain approaches internally to separate task understanding from execution.
Recently released models like Sharpa's CraftNet and Figure AI's Helix02 have incorporated System 0 to further enhance robotic operation precision and accuracy, making VLA model deployment more practical.
However, in the current embodied AI competition, when asking about the most representative technological work, overseas companies like Physical Intelligence, Figure AI, and Google are always mentioned first.
Yet Chinese companies have made significant efforts in this area, often finding their early achievements popularized by foreign teams.
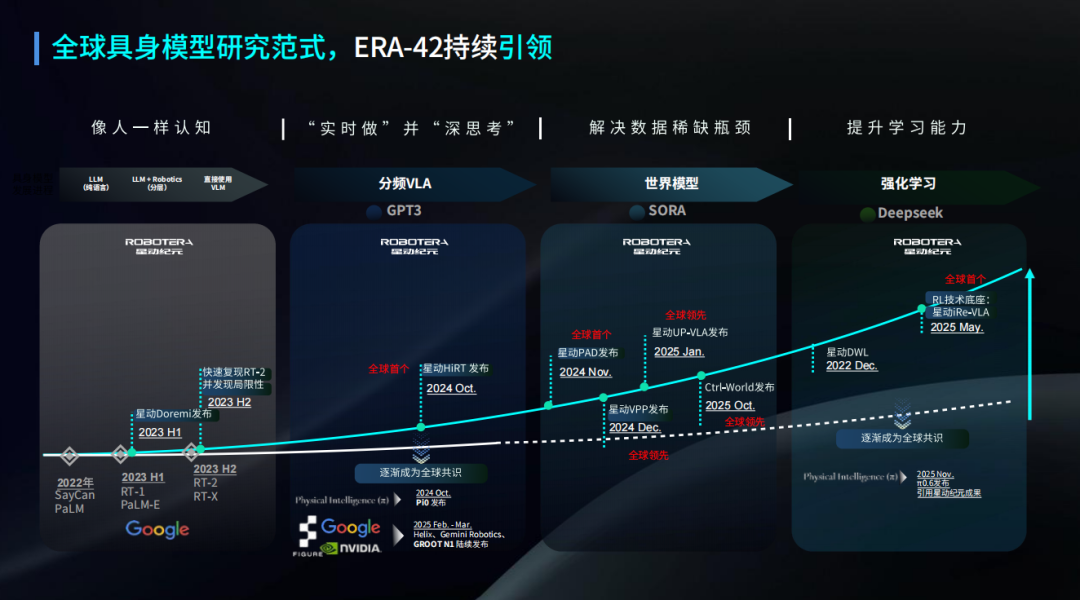
For example, the hierarchical end-to-end architecture gained widespread attention with Figure's Helix01 release in February 2025, but Star Era had already introduced its HiRT fast-slow hierarchical architecture in September 2024 and applied it to its proprietary end-to-end robotic large model ERA-42.
Notably, ERA-42 was the first domestic model to control robotic limbs and dexterous end-effectors using a single embodied brain VLA.
Wang Qian from Independent Variable Robotics had a similar experience. Their team began developing an any-to-any model for multimodal input-output in October-November 2024, simultaneously completing research on embodied Chain of Thought (COT).
This aligned highly with the technical direction of PI's π0.5 model released in mid-2025.
This pattern of Chinese innovation followed by overseas popularization mirrors the earlier LLM regret (LLM regret) and represents a challenge Chinese embodied AI players must overcome.

World Models: Enabling True Understanding of the Physical World
After VLA equips robots with real-time perception and response capabilities, a new question arises: How can robots develop profound understanding and predictive capabilities about the physical world like humans?
Even the most advanced VLA models operate in open-loop execution modes—predicting actions based on current visual information and language instructions without anticipating consequences. This makes strategy adjustment difficult when unexpected situations arise.
This technological pain point has made world models a hot research direction in embodied AI, with many scholars believing they hold the key to achieving Artificial General Intelligence (AGI).
Simply put, world models enable robots to simulate and reason ahead.
By dynamically perceiving environments and learning patterns, they construct virtual environmental models that predict how actions will alter the environment, providing forward-looking decision bases for robots.

Currently, no unified definition exists for world models in the industry. Different teams have pursued three distinct technical routes based on varying cognitive understandings.
Yann LeCun's research team argues that true intelligence must understand "why" like humans.
LeCun has long questioned whether LLMs can achieve AGI, citing fundamental flaws in linguistic representation. He proposes world models based on the V-JEPA architecture.
These models don't rely on language texts but understand the physical world through learning video and spatial data while possessing planning, reasoning, and long-term memory capabilities.
Fei-Fei Li's World Labs focuses on spatial intelligence, enabling AI to understand object relationships, occlusion, perspective, and motion patterns in 3D space.
They've developed systems that infer 3D structures from 2D images, emphasizing geometric consistency and physical plausibility with direct applications in robotic navigation and manipulation.
Google DeepMind's Genie represents another approach—training models to generate interactive virtual worlds from images and text.
The latest Genie3 can create corresponding 3D environments from textual descriptions, enabling AI to learn physical laws and interaction strategies through diverse training environments.
Technical analysis reveals:
LeCun's direction is most idealistic but hardest to implement;
Li's approach has high costs and lacks understanding of physical principles in 3D generation;
Google Genie's method is currently the most feasible but still faces the simulation-to-reality gap.
In this world model competition led by foreign players, Chinese teams aren't mere spectators but have long engaged in practical engineering implementations.
In December 2024, Star Era released VPP, an algorithmic framework integrating world models—the first globally to deeply fuse world models with VLA architecture.
Star Era's world model approach in VPP resembles Google's 2024 Genie1, focusing on video-based AI training to understand the world, as internet videos have long been crucial sources of robotic data.

By using predicted visual representations from video diffusion models as robotic strategy inputs, the Star Era team achieved general robotic strategies on generative video models for the first time.
Besides helping robots understand the physical world, world models reduce learning difficulty while serving as supervisory and predictive systems to observe strategy learning effects.
Direct robotic command execution risks damage and increases detection complexity. Through prior experience prediction, robots can halt strategies if subsequent operations are likely to fail.
In October 2025, Star Era and PI jointly published Ctrl-World, proposing the first controllable generative world model that breaks through three bottlenecks of traditional world models: single-perspective hallucinations, imprecise action control, and poor long-term consistency.
Currently, world models serve more as technological tools to enhance VLA model performance.
However, as technological paths converge and VLA models improve, along with further research commercialization, world models may well become the next mainstream paradigm in embodied AI after VLA.

Reinforcement Learning: From Imitating Experience to Autonomous Evolution
As VLA models address the challenge of agency and world models fill the gap in predictive capabilities, the next core requirement for embodied AI is optimization.
Reinforcement learning (RL) emerges as the key technology to meet this demand and has become a focal point in current embodied AI research.
It forms a perfect complement with VLA and world models:
VLA equips robots with perception and understanding abilities.
World models provide robots with prediction and imagination capabilities.
Reinforcement learning empowers robots with reinforcement learning and optimization capacities.
The core logic of reinforcement learning is not overly complex—it essentially simulates the human trial-and-error learning process.
Through a closed-loop mechanism of trial-and-error and reward feedback, robots autonomously explore action strategies, eventually converging the model toward optimal policies.
The greatest advantage of this learning mode lies in its independence from massive expert demonstration data or manually designed action rules. Robots can adapt to unknown scenarios through autonomous exploration and even discover efficient strategies beyond human imagination.
As early as 2016, AlphaGo's victory over human Go world champions using reinforcement learning brought this technology into the limelight. However, its practical implementation in embodied AI has long faced bottlenecks.
Early robots had high hardware costs, and the trial-and-error process of reinforcement learning often led to equipment wear. Additionally, the complexity of variables in real-world environments made it difficult to design reasonable reward functions, limiting RL applications mostly to virtual simulation scenarios.
Over the past year, with advancements in VLA and world models, along with optimizations in RL algorithms, this technology has once again become a research hotspot in embodied AI.
This resurgence of interest in reinforcement learning is also driven by Sergey Levine, a leading authority in the field and founder of Physical Intelligence.
His team's series of published achievements not only validated the potential of combining reinforcement learning with VLA but also reshaped industry perceptions of embodied AI training paradigms.
One of Sergey Levine's research focuses is offline reinforcement learning, which trains models using existing historical data without requiring real-time trial-and-error in physical environments. This approach avoids equipment damage and safety risks while significantly reducing training costs.
His team's latest π*0.6 model demonstrates another performance milestone for VLA models, even accomplishing highly challenging tasks like peeling oranges, flipping socks, and unlocking doors with keys at the Robot Olympic.

However, π*0.6 also reveals a core pain point in reinforcement learning: the difficulty of designing reward functions.
In complex tasks, the value of individual actions is hard to quantify, and reward standards vary greatly across different scenarios. Consequently, the π*0.6 model had to incorporate supervised learning paradigms for auxiliary training, failing to fully leverage reinforcement learning's advantage of autonomous exploration.
This limitation has made engineers realize that while offline reinforcement learning offers cost control and high safety, it struggles with unknown scenarios beyond training data and lacks generalization capabilities. This necessitates the introduction of online reinforcement learning to dynamically optimize strategies through real-time environmental feedback.
At this stage of technological development, breakthroughs by Chinese teams have demonstrated unique value.
The iRe-VLA framework released by Xingdong Era in May 2025 represents the world's first integration of online reinforcement learning into VLA models, providing a breakthrough solution to core challenges in reinforcement learning.
Through algorithmic optimizations, the framework ensures real-time feedback while reducing trial-and-error risks and equipment wear to acceptable levels, enabling robots to autonomously explore and dynamically optimize action strategies in real-world environments.
Notably, the core ideas of iRe-VLA served as an important reference for the reinforcement learning module in the π*0.6 model.
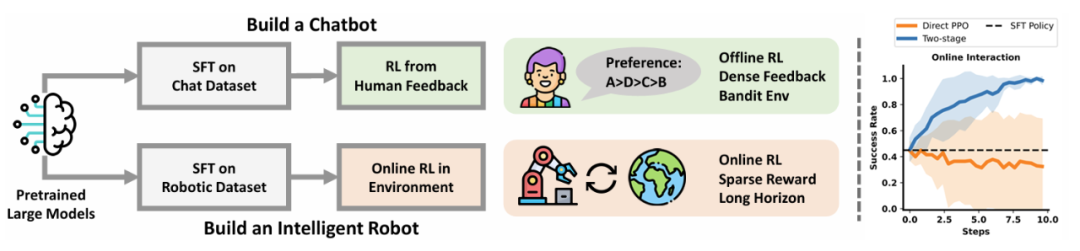
Differences Between LLM and Embodied AI in Reinforcement Learning
Around the same time as iRe-VLA's release, Chinese player Lingchu Intelligence unveiled Psi-R1, a hierarchical end-to-end VLA + reinforcement learning algorithm model. R1 enables robots to overcome long-term complex task challenges in open scenarios through an autonomous reasoning system based on the CoAT framework.
In November 2025, Zhiyuan introduced the world's first real-robot reinforcement learning technology for embodied AI, deployed in a Shanghai smart equipment production line. This innovation reduced robot training cycles from weeks to just over ten minutes while achieving a 100% task completion rate.
In this wave of reinforcement learning advancements, Chinese players are not mere followers but contributors, demonstrating both academic influence and earlier industry collaboration compared to international counterparts.
Reflecting on the development of large language models (LLMs), a key lesson is that early insights do not guarantee ultimate success. The path from theoretical understanding to industrial leadership involves a lengthy journey of engineering, productization, and ecosystem building.
Today, in the field of embodied AI—considered the next breakthrough in physical AI—Chinese teams have demonstrated parallel progress with global peers across critical technological areas.
The competition in embodied AI is essentially a dual contest of original innovation capabilities and implementation efficiency, as well as a battle for discourse power.
To avoid the regrets of the LLM era, we need to focus on two priorities:
1. Strengthen the market-oriented dissemination of academic achievements to ensure Chinese teams' technological innovations are recognized by the industry and market, breaking the monopoly of international teams over track ( track should be translated as "the field" or "the track " is possibly a typo, here using "the field") discourse power.
2. Accelerate technology implementation and iteration, using real-world application feedback to optimize technologies and form a closed loop of academic innovation-industrial implementation-iterative upgrading, transforming original achievements into genuine product competitiveness.
History may not repeat itself exactly, but it often rhymes. At least for now, the probability of success stands at 50-50 between Chinese and U.S. players.
-
![]()
Total Investment Hits Nearly 3.28 Billion! Goertek Launches Mass Production of 12-Inch Transparent Substrate Wafer for AR Glasses’ Micro-Nano Optical Components
-
![]()
Why Is This Precision Optical Film Leader Worth Reevaluating with a Tens of Millions Procurement?
-
![]()
AI Costs Plummet by 90% Over Nine Years: Key Insights from Davos You Shouldn’t Miss
-
Doubao, Your Late-Night AI Companion, Now Eyes Profitability
-
![]()
SRC Empowers SEER Intelligence to Reach a Market Cap of Tens of Billions, Yet Fails to Sustain Profitability
-
![]()
China’s Embodied AI Industry Faces Fierce Domestic Competition, Making Overseas Expansion Essential for Survival
-
![]()
32.8 Billion Yuan Investment! Goertek’s 12-Inch AR Glasses Optical Wafer Base in Lingang Begins Operations
-
![]()
How Far is the All-New Li Auto L8 from Being the Best Five-Seat SUV with In-House Full-Stack Development?






