Visual AR Makes a Comeback! 177M Effect Rivals 675M State-of-the-Art Diffusion Model with a 'Plug-and-Play' Regularization reAR
 03/19 2026
03/19 2026
 533
533
Interpretation: The Future of AI Generation

Highlights
Identifies the inconsistency between the generator and tokenizer, where the tokenizer cannot decode the generated token sequence, as the bottleneck in visual autoregressive generation;
reAR, a plug-and-play training regularization method that introduces the visual inductive bias of the tokenizer and mitigates exposure bias to train visual autoregressive models;
Demonstrates that reAR significantly improves visual autoregressive generation across different tokenizers (e.g., FID improves from 3.02 to 1.86 on VQGAN) and even surpasses more complex generative models with fewer parameters.
Summary
Generation Results Display




Problems Solved
The performance of visual autoregressive (AR) generative models in image generation significantly lags behind diffusion models. Researchers have identified the core bottleneck as inconsistency between the generator and tokenizer. Specific manifestations include:
Difficulty for the tokenizer to effectively decode the token sequence generated by the generator back into an image.
Exposure Bias: AR models predict the next token based on real context during training but rely on their own potentially erroneous predictions during inference, leading to the generation of token sequences not seen during training. This is particularly evident in visual AR, where an early error can propagate structural artifacts throughout the image.
Embedding Unawareness: AR models optimize only for the correctness of discrete token indices during training, ignoring how the tokenizer embeds these tokens into continuous space. Even if a token prediction is incorrect, if its embedding is close to the correct token's embedding, image quality may remain high, but AR models are not 'aware' of this. This unawareness prevents the model from effectively leveraging similarity information in the embedding space and may cause the embedding of the generated sequence to deviate from the training distribution.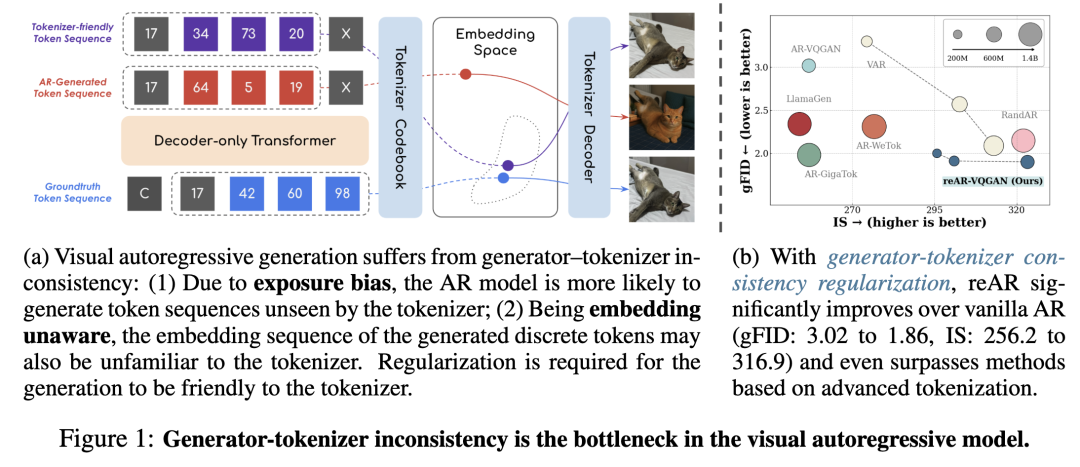
Proposed Solution
Introduces reAR, a plug-and-play training regularization framework designed to address generator-tokenizer inconsistency and enable AR models to generate token sequences more 'friendly' to the tokenizer. reAR introduces token-level consistency regularization.
reAR primarily consists of two complementary strategies:
Noisy Context Regularization: Reduces reliance on 'clean' real context during training by exposing the model to perturbed contexts (i.e., applying uniform noise to the input token sequence). This improves the model's robustness to imperfect prediction histories during testing, thereby mitigating the tendency to generate unseen token sequences due to exposure bias.
Codebook Embedding Regularization: Explicitly aligns the hidden states of the generator Transformer with the embedding space of the tokenizer. Specifically, the Transformer is trained to recover the visual embedding of the current token in noisy contexts and predict the embedding of the current token in shallow layers and the target (next) token in deep layers. This encourages the generator to perceive how tokens are decoded into visual patches, ensuring that even if unseen token sequences are generated, their corresponding embedding sequences remain more compatible with the tokenizer.
Technologies Applied
The reAR framework requires no modifications to any core components of existing visual AR models, including:
No changes to the tokenizer
No changes to the generation order
No changes to the inference pipeline
No introduction of external models
Its core technologies include:
Decoder-Specific Transformer: Maintains the original Transformer-based architecture of AR models for next-token prediction.
Token-Level Regularization Objectives: Introduces, in addition to the traditional next-token prediction loss, additional regularization tasks for recovering the visual embedding of the current token and predicting the embedding of the next token.
Linear Annealing Schedule: Used to control the gradual change in noise levels during noisy context regularization to ensure training stability and expose the model to varying degrees of noise.
**Multilayer Perceptron (MLP)**: Used to project the hidden features of the Transformer into the target visual embedding space for embedding regularization.
Cosine Distance: Used as a metric to measure the distance between generator features and tokenizer embeddings.
Achieved Results
reAR achieves significant performance improvements with excellent generalization capabilities and efficiency:
Significantly improves image generation quality: On the ImageNet dataset, using a standard rasterization tokenizer, gFID decreases from 3.02 to 1.86, and IS increases to 316.9. Under the same model size and training budget, reAR even surpasses alternative paradigms such as traditional MAR, VAR, and SiT.
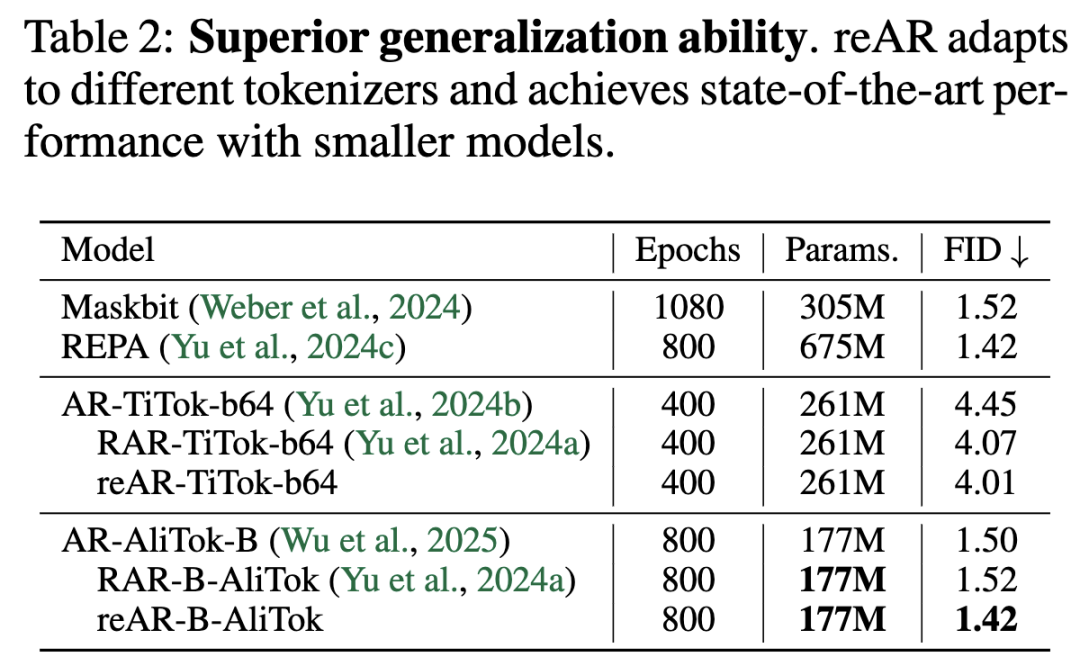
Strong generalization ability across different tokenizers: Even when combined with non-standard tokenizers like TiTok (bidirectional) and AliTok (unidirectional), reAR consistently improves performance (e.g., FID improves from 4.45 to 4.01 on TiTok and from 1.50 to 1.42 on AliTok).
Matches the performance of state-of-the-art diffusion models with fewer parameters: Combined with the advanced tokenizer AliTok, reAR achieves a gFID of 1.42 with only 177M parameters, matching the performance of the larger-scale, state-of-the-art diffusion model REPA, which requires 675M parameters. reAR-S outperforms LlamaGen-XL with 14% of the parameters (201M vs. 1.4B) and surpasses WeTok at only 13-15% of its size.
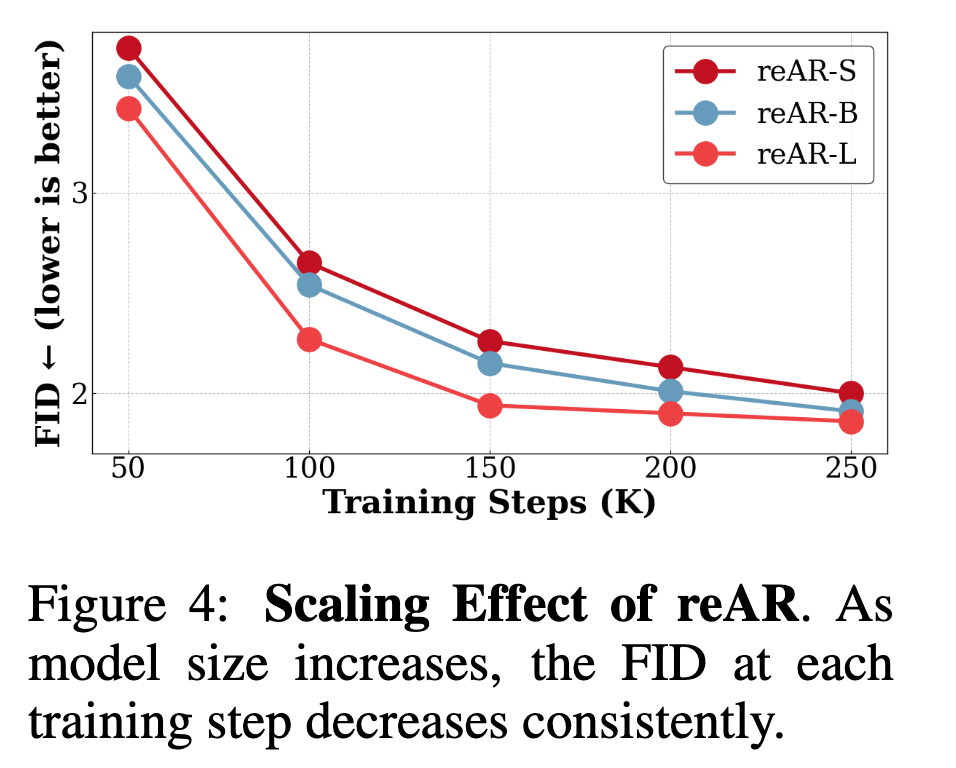
Good scaling behavior: As model size and training iterations increase, reAR's FID continues to decrease, demonstrating its potential in large-scale visual AR models.
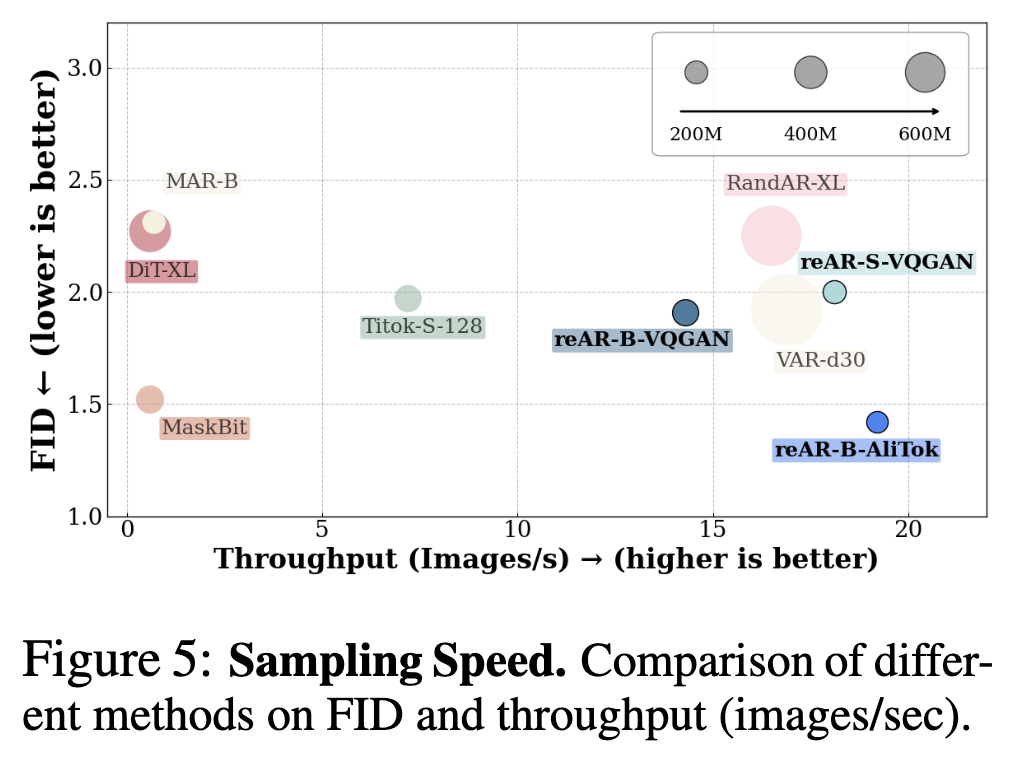
Faster sampling speed: Like other autoregressive models, reAR benefits from KV-cache, achieving higher sampling speeds than diffusion models and MAR. reAR-B-AliTok even achieves lower FID at faster speeds than parallel decoding methods like Maskbit.
Higher generalization ability and robustness: reAR narrows the performance gap between training data and unseen data and exhibits higher robustness under noisy inputs, thereby improving generalization capabilities.
reAR: Consistency Regularization in Visual AR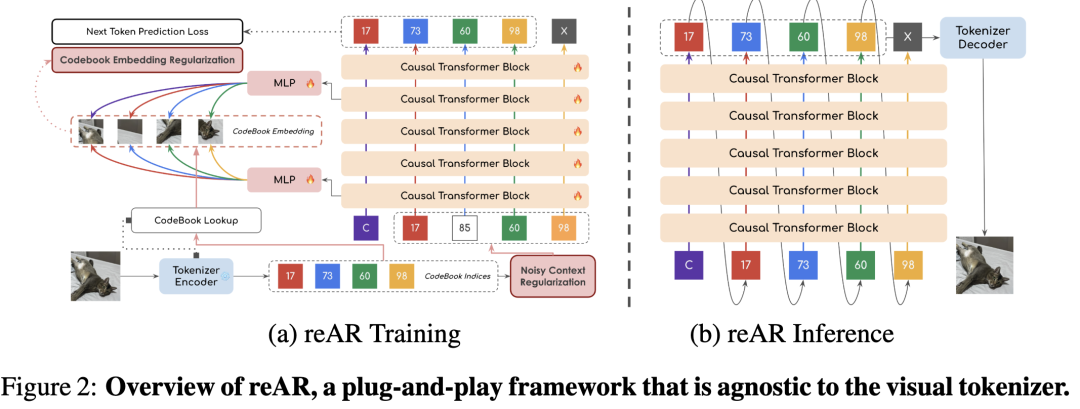
Unlike natural language,
To verify this hypothesis, the paper investigates and quantitatively analyzes how existing visual autoregressive models are affected by inconsistency. Based on these observations, reAR is proposed: Regularizing Token-Level Consistency in Visual Autoregressive Generation, a plug-and-play regularization training method designed for visual autoregressive models. In summary, reAR introduces visual embeddings looked up from the discrete tokenizer into the hidden features of the generator under noisy contexts. Despite its simplicity, reAR allows autoregressive models to leverage visual signals compatible with the tokenizer and significantly reduces inconsistent behavior.
Understanding the Bottlenecks in Visual Autoregressive Generation
The performance of autoregressive models can be evaluated by the correct token ratio (CTR) between the generated token
Amplified Exposure Bias. Exposure bias is a well-known issue in sequence models: during teacher-forcing training, the model predicts the next token given real context, but during inference, it must condition on its own predictions, which may contain errors. In visual autoregressive generation, this paper hypothesizes that the visual tokenizer amplifies this effect, as exposure bias leads to more unseen token sequences and propagates structural errors in pixel space. To verify this, consider a token sequence
Since both protocols fix the number of real tokens to

Embedding Unawareness. During training, AR models are optimized only for token correctness, while the tokenizer decoder operates in embedding space. This paper hypothesizes that even if the predicted token is incorrect, if its embedding is close to the correct token's embedding, the decoded image may still maintain high visual quality. To verify this, this paper introduces the replacement ratio
Figure 3(b) displays the results. As increases, the average embedding similarity improves, and LPIPS declines significantly. Qualitatively, as shown on the right side of Figure 3(b), this substitution, performed without altering CTR, produces decoded images more faithful to the ground truth (e.g., clearer predictions of shirts and human legs). This suggests that incorporating tokenizer embeddings into the training of AR models may enhance their alignment.
A direct method to increase generator-tokenizer misalignment is to reuse the tokenizer’s codebook embeddings in the embedding layer or prediction head of the AR model. However, this approach often leads to suboptimal performance unless the tokenizer design is sophisticated. This paper hypothesizes that such rigid integration is not ideal: it may limit the scalability of large AR models with small tokenizers, and the codebook embeddings themselves may not be the optimal representation for the primary task of next-token prediction. Embeddings need to be introduced into the model in a less constrained manner.
Generator-Tokenizer Alignment Regularization
These findings reveal a training-inference misalignment: solely maximizing the correctness of predicted token indices is insufficient for visual AR models. An appropriate inductive bias is needed to train the generator to produce token sequences that are more consistent with the tokenizer during inference.
To address this misalignment, reAR introduces token-level alignment regularization during the training of visual AR models. Specifically, the decoder-only Transformer is trained to perform next-token prediction under noisy contexts, while its hidden representations are regularized by the visual embeddings of the correct current token in shallow layers and the embeddings of the correct next token in deep layers. This encourages the AR model to interpret the current token similarly to the tokenizer while improving robustness to exposure bias, then predicting next-token embeddings compatible with the decoder.
Below, this paper denotes the AR model as , the tokenizer codebook as , the training dataset as , and the discrete token sequence as .
Noisy Context Regularization. While techniques like scheduled sampling can mitigate exposure bias, this paper opts for a simple approach that preserves the parallel training of Transformers. Specifically, this paper applies uniform noise to the input, denoted as . Formally:
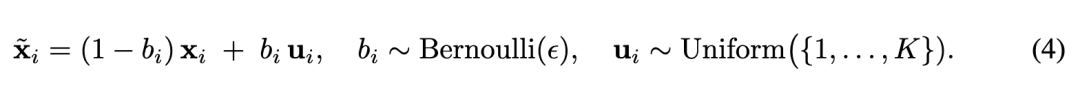
where is a Bernoulli random variable with probability , and is uniformly sampled from codebook indices. In practice, the choice of strongly influences training stability. To ensure the AR model is exposed to sequences with varying noise levels, this paper samples for each token sequence, where represents the normalized training progress. Here, is an annealing schedule controlling the maximum noise level during training. The AR model is then trained to predict the next correct token based on the noisy context. Formally:
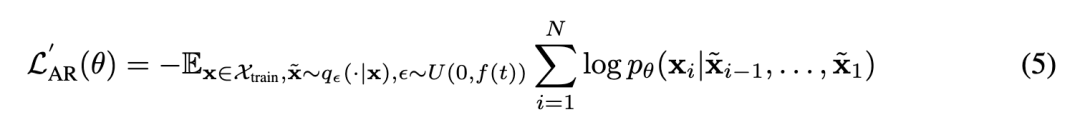
Empirically, annealed uniform noise augmentation stabilizes training compared to fixed-ratio noise augmentation.
Codebook Embedding Regularization. Instead of directly applying codebook embeddings, this paper proposes adding a regularization task to recover the current embedding and predict the next embedding. Specifically, this paper applies a trainable MLP layer to project hidden features into a target space of the same dimension as the visual embeddings. To simplify notation, this paper uses to denote features from shallow layer and for deep layer . Aligned with the design of the decoder-only Transformer, the shallow layer aims to predict the embedding of the current token, while targets the next token. Formally:
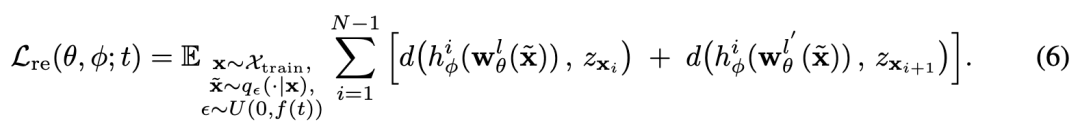
where is the cosine distance used to evaluate the distance between different features, denotes the mapping from features of the th current token to the embedding space, is the embedding of the current token looked up from the codebook, and is the embedding of the next token. In implementation, this paper applies regularization to the layers initially closest to the tokenizer embeddings in vanilla AR (i.e., Layer 1 for encoding regularization and Layer 15 for decoding regularization) to avoid potential conflicts with the primary task of next-token prediction.
Generator-Tokenizer Alignment Regularization. Combining noisy context regularization and codebook embedding regularization, the objective of reAR is:
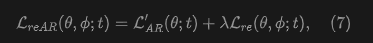
where is the weight of the regularization term. Note that this paper also aligns the hidden features of noisy tokens with the embeddings of real tokens, which further encourages the autoregressive model to predict codebook embeddings in a robust manner. This joint effect is crucial for improving the performance of visual autoregressive generation.
Experiments and Analysis
Experimental Setup
A summary of this paper's experimental setup is as follows:
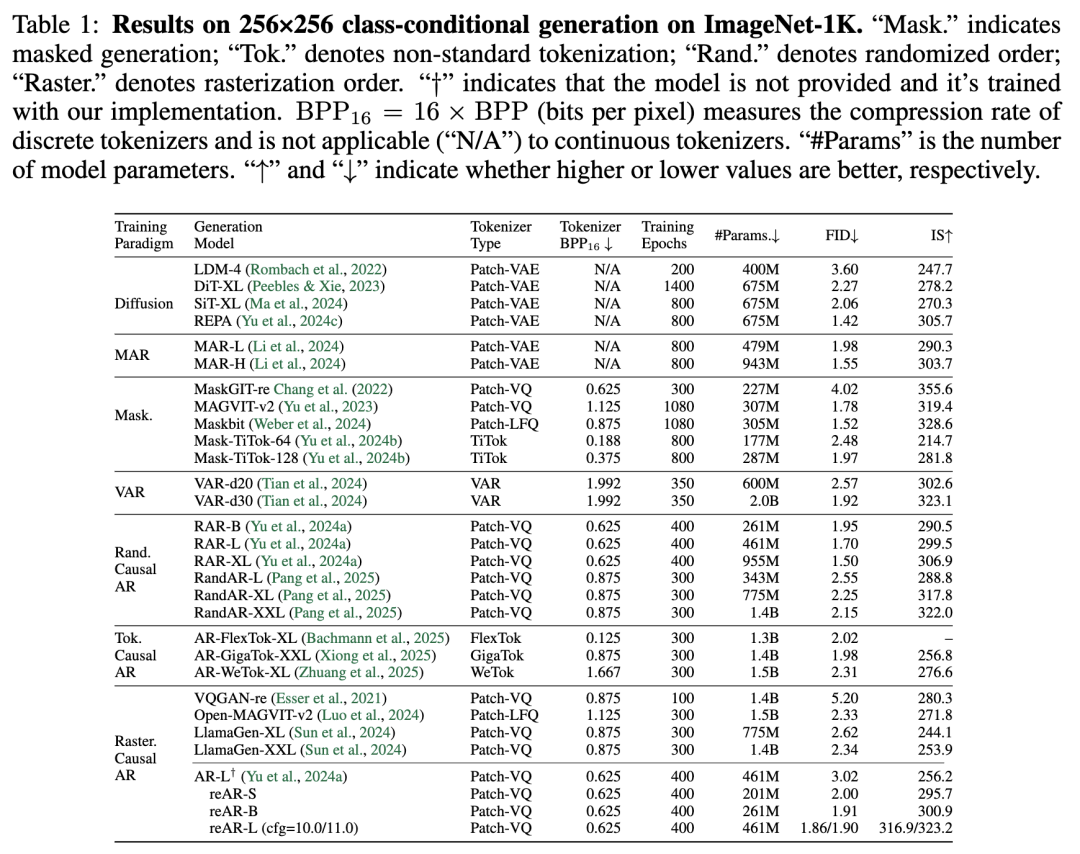
Datasets and Evaluation. This paper evaluates reAR using the ADM protocol on ImageNet-1K at 256×256 resolution. Each model generates 50k images using classifier-free guidance. This paper reports FID (lower is better) and IS (higher is better) and compares training efficiency by epoch count and parameter count required to achieve the same quality. Baselines cover diffusion models, masking generation (continuous and discrete), VAR, random-order AR, advanced tokenizer AR, and standard raster AR (see Table 1).
Model Configuration. This paper uses MaskGIT VQGAN (rFID = 1.97) as the tokenizer and a DiT-style AR backbone. This paper reports reAR-S/B/L, with 20/24/24 causal Transformer layers and hidden sizes of 768/768/1024, respectively. To assess reAR's generalization capability, this paper also combines it with TiTok and AliTok, adopting their original settings.
Training. All models are trained for 400 epochs (batch size 2048) on 8 A800 GPUs using AdamW, gradient clipping (norm = 1), and accumulation. The learning rate warms up to over the first 100 epochs and then decays to over the remaining 300 epochs. Class labels are dropped with a probability of 0.1 to enable classifier-free guidance during inference.
reAR Implementation. This paper applies a linear schedule to annealed noise augmentation. Embedding regularization is implemented using a 2-layer MLP (hidden size 2048, weight ): the shallow layer regularizes the current embedding at , while the deep layer regularizes the decoding features at depth across the entire Transformer ( for reAR-S/B/L, respectively).
Main Results
Generation Quality. As shown in Table 1, even with a standard raster-order AR model and a simple 2D patch tokenizer, reAR achieves excellent results. reAR-S outperforms previous raster AR models like LlamaGen-XL (FID 2.00 vs. 2.34; IS 295.7 vs. 253.9) using only 14% of the parameters (201M vs. 1.4B) and surpasses advanced tokenizer AR models like WeTok with just 13-15% of their size. At a similar scale, it matches RAR and outperforms RandAR, while reAR-L outperforms MAR-L and VAR-d30. Although diffusion and masking generation models remain strong, reAR narrows the gap with fewer training epochs.
Generalization Capability. This paper also evaluates reAR on non-standard tokenizers, TiTok and AliTok. Unlike RAR, which primarily aids bidirectional tokenization, reAR consistently improves performance for both bidirectional (TiTok: 4.45 → 4.01) and unidirectional (AliTok: 1.50 → 1.42) tokenizers. Notably, it approaches diffusion-based REPA and outperforms Maskbit while using fewer parameters (177M vs. 675M/305M), as detailed in Table 2.
Scaling Effects. This paper also investigates whether reAR maintains the scaling behavior of the original AR models. Specifically, this paper plots FID for different model sizes across training epochs. As shown in Figure 4, FID consistently decreases with increasing model size and training iterations, revealing reAR's potential for large-scale visual AR models.
Sampling Speed. Like other autoregressive models, reAR benefits from KV-cache to achieve high sampling speed. This paper measures throughput with a batch size of 128 on a single A800 GPU (as shown in Figure 5). With KV-cache, autoregressive models run significantly faster than diffusion models and MAR. Moreover, reAR-B-AliTok achieves lower FID with faster sampling speed compared to parallel decoding methods like Maskbit, TiTok, VAR, and RandAR.
Ablation Studies
This paper conducts ablation studies on reAR's key components, focusing on the weighting and layer selection for encoding/decoding regularization, as well as noise augmentation strategies.
Regularization Layers. Using reAR-S trained for 80 epochs without classifier-free guidance, this paper analyzes the optimal layers for embedding regularization (as shown in Table 3). This paper ablates the presence and position of regularization and compares it with a naive bound embedding strategy. For decoding regularization, early layers (e.g., Layer 10) offer little benefit, while Layer 15 performs best; applying deeper layers slightly degrades performance. For encoding regularization, the first layer is optimal as it aligns best with token embeddings, while deeper layers harm generation quality. Notably, applying regularization to the layers closest to the target embedding space in vanilla AR—encoding at Layer 0 and decoding at around depth—yields the best results. This paper hypothesizes that such placement minimizes interference with the primary task of next-token prediction. Based on these findings, this paper uses EN@0 + DE@15 for reAR-S and EN@0 + DE@18 for reAR-B/L.
Regularization Weight. As shown in Table 3, the regularization weight has a negligible impact on generation quality, likely because the AdamW optimizer is insensitive to loss magnitude. For simplicity, this paper uses .
Noise Augmentation. This paper further ablates the design of noise augmentation, exploring two strategies: (1) assigning different noise levels to each token sequence and (2) annealing the maximum noise level during training. Results are shown in Table 4, based on the default setting with codebook embedding regularization (EN@0 + DE@15 for reAR-S). All models are trained for 400 epochs to assess the effects of different schedules. This paper finds that a fixed noise level increases FID from 2.12 to 2.08, while a higher level () causes training collapse (FID = 3.15). Randomizing the noise level to the [0, 0.5] range further improves FID to 2.05. Combining this with an annealing schedule, where , produces stronger results (2.02 FID). Finally, using a truncated linear schedule achieves the best performance with 2.00 FID. These results highlight the effectiveness of appropriately annealed noise augmentation.
Joint Effect of Alignment Regularization. As shown in Table 4, using embedding regularization alone () yields an FID of 2.12, while noise augmentation alone results in 2.18. In contrast, combining both further improves performance, reducing reAR-S's FID to 2.00. This indicates that both noisy context regularization and codebook embedding regularization are important.
Conclusion
This work identifies the key bottleneck in visual autoregressive generation as the mismatch between the generator and tokenizer—namely, the difficulty for AR models to generate token sequences that can be effectively decoded back into images. To address this, reAR, a simple regularization method, is proposed, which significantly improves visual AR performance while remaining independent of tokenizer design. This paper hopes this work will encourage future efforts to unify generators and tokenizers in visual AR models and, more broadly, to develop unified multimodal models.
References
[1] REAR: Rethinking Visual Autoregressive Models via Generator-Tokenizer Consistency Regularization
-
![]()
WeChat Collaborates with Huawei/Honor/Xiaomi on A2A: Is This the Dawn of AI Integration?
-
![]()
NVIDIA RTX Spark: Powerful, Yet Not the Ideal Choice for the Agent Era
-
![]()
NVIDIA RTX Spark: Powerful, but Is It the Right Fit for the Age of Agents?
-
![]()
A Genuine Threat or Just a Publicity Stunt? World's Premier AI Firm Warns: AI Evolving Autonomously, Slipping Beyond Human Control
-
How Meituan is Becoming the 'Interface' for AI Integration into the Physical World
-
![]()
RoboScience Machine Science Makes ICRA Best Paper List for Two Years Running with Its 'Embodied Brain' Innovation
-
![]()
Focusing on UTG Ultra-Thin Flexible Glass! CSG Optical New Material Production Base Establishes in Xianning, Hubei
-
![]()
AI Meets Optics: Tsinghua Smart Vision Secures A+ Round Funding Led by Hillhouse Capital





