Is VLA Dead? This Company Wants to Equip Robots with 'Physical Intuition' Using VLOA
 05/14 2026
05/14 2026
 562
562

Author|Li Murong
In May this year, Jim Fan, the head of NVIDIA Robotics, made a bold statement at the Sequoia Summit: 'VLA is dead.'
These four words brought to the surface the long-simmering anxieties within the embodied intelligence industry.
How, exactly, should we solve the robot generalization puzzle?
RoboScience, having completed RMB 1 billion in Series A financing, offers its own solution: VLOA (Vision-Language-Object-Action).
Compared to VLA, VLOA embeds 'Object' between vision and action, focusing on how objects should move. The model doesn't just 'see and execute'—it can, to a certain extent, understand 'how actions occur and evolve in the physical world.'
VLOA transforms tasks into an understanding of object trajectories and generates actions accordingly, fundamentally addressing generalization challenges to some extent.
This round of financing will primarily be used to further develop the VLOA model and advance the engineering and mass production of self-developed robot platforms.

What's Behind the RMB 1 Billion Financing?
Capital interest in RoboScience actually began last year.
During the angel round, JD, China Merchants Capital, and Zero2IPO Ventures showed their confidence with a RMB 200 million investment.
In this year's Series A round, the financing scale expanded further, with cumulative funding exceeding RMB 1.3 billion. Investors include numerous well-known domestic and international industry giants and top-tier financial institutions.
Behind the sustained capital pursuit lies a bet on the team's capabilities and the VLOA model.
The uniqueness of the RoboScience team lies in its combination of engineering implementation capabilities and cutting-edge academic research achievements.
Founder Tian Ye completed his undergraduate studies at the University of Science and Technology of China's School of Physics before joining the Stanford AI Lab under the mentorship of Andrew Ng.
During his seven years at Apple, he served as the technical lead for the Apple AI Platform, participating in the development and implementation of core projects such as Apple Intelligence, on-device dynamic neural networks, and compiler fusion systems. He brings mature experience in AI technology deployment and ecosystem construction.
This means he doesn't just understand models—he understands how to deploy them into hardware systems.
Another key figure on the team is Chief Scientist Shao Lin, who is not only an assistant professor in the Computer Science Department at the National University of Singapore but also the co-chair of the IEEE Robotics and Automation Society's Technical Committee on Machine Learning.
He has long been deeply involved in cutting-edge fields such as robot perception and manipulation, reinforcement learning, and robotic operation models. He has published over 35 papers in top conferences and journals like ICRA, IROS, and IEEE, keeping his technical achievements at the industry's forefront.

Heavily influenced by Apple's product philosophy, this team chose a full-stack approach of 'self-developed models + self-developed platforms' from the very beginning.
They believe that if models and hardware are disconnected, it will never be possible to truly understand where robots fail in the real world—whether it's a perception error or an execution issue. Closed-loop iteration must be controlled at both ends.
This 'software-hardware integration' strategy aligns perfectly with capital's preference for closed-loop capabilities in hard technology.
Puhua Capital's assessment when leading the Pre-A round accurately summarizes market expectations for this approach:
RoboScience's innovative VLOA large model architecture and its fast-slow brain hierarchical system not only solve long-standing generalization challenges in the industry but also establish an efficient data closed loop through its self-developed RoboMirage simulation engine, paving the way for the realization of general-purpose robots.

VLOA Model Breaks Through Generalization Bottlenecks in Embodied Intelligence
Over the past two years, VLA models have become the most mainstream 'brain' models in the robotics industry, using vision to perceive the environment, language to understand tasks, and action to execute instructions.
They provide robots with a simple, unified, and easily explainable 'brain paradigm,' enabling task understanding capabilities for the first time.
UBTECH Walker S2 and Zhipingfang AlphaBot 2 have both incorporated or emphasized VLA models to varying degrees.
However, problems gradually emerged. VLA seems to only understand tasks, not the physical world.
In April, a paper published on arXiv used causal intervention experiments to demonstrate that VLA models 'catastrophically fail' in dynamic scenes.
When the environment changes, the model tends to repeat previous actions rather than adjust based on the new state. More seriously, in complex scenarios, multimodal semantic features can experience 'semantic collapse,' causing the model to lose its ability to distinguish.
Peter Chen, co-founder of Covariant, once bluntly stated:
'VLA is good at answering 'what is this,' but not at answering 'what will happen after doing this'—it lacks an understanding of physical causal chains.'
The VLOA model, building on traditional VLA, isolates 'Object' as a core intermediate layer between vision-language and action.
RoboScience argues that all robot operations essentially involve changing an object's position, orientation, and interaction relationships in 3D space.
Whether it's turning a bottle cap, folding clothes, or picking up a cup, no matter how complex the task, it can ultimately be uniformly described as 'changes in object trajectories.'
The entire model architecture is divided into two layers:
The upper layer, V→O (Vision to Object), is handled by an embodied world model responsible for semantic planning, understanding objects in the scene and the intent of instructions, and answering how an object's state should change to complete a task.
The lower layer, O→A (Object to Action), is managed by a general-purpose operation model responsible for physical execution, enabling the robot to manipulate objects according to physical laws to produce the desired motion changes.
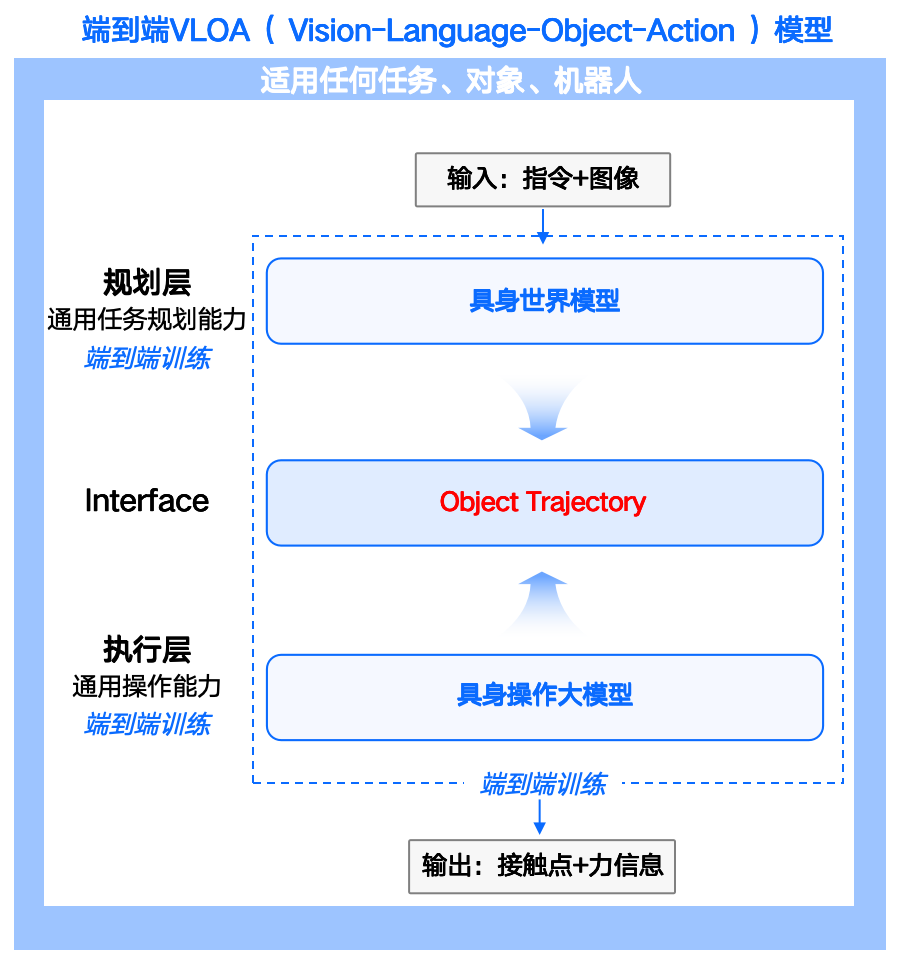
What's transmitted between the two layers is the object trajectory (Object Trajectory) expressed in 3D point cloud form, including the object's position, orientation, motion direction, and prediction confidence.
In other words, VLOA attempts to make 'object motion' the foundational language for robots to understand the world.
This approach offers three advantages over VLA.
First, the generalization foundation is closer to real physical operations.
Traditional VLA resembles 'action memorization,' while VLOA focuses on object motion patterns, which are closer to the essence of real-world operations.
Second, it enables cross-platform generalization.
The upper-layer world model isn't tied to a specific robot form, so theoretically, the same model can be transferred to different robot platforms, including single-arm, dual-arm, humanoid, and wheeled robots.
Third, it achieves better results with less data.
The hierarchical model structure makes data collection and processing more organized. By focusing on the essence of robot-physical world interactions—object motion trajectories—vast amounts of video data can become training resources, reducing reliance on real-robot data.
According to the team, the embodied world model has already accumulated millions of hours of multimodal operation datasets and continues to grow at a rate of hundreds of thousands of hours per week.
Not long ago, Elon Musk also mentioned using video training to replace real-robot data, demonstrating the forward-thinking nature of RoboScience's approach.

The Ultimate Answer to Generalization Is Still on the Way
Today, the entire embodied intelligence industry is competing toward the same ultimate goal: general-purpose robots.
True general-purpose robots won't just complete a single task—they'll continuously adapt in an infinitely changing world, just like humans.
Currently, embodied intelligence generalization faces three challenges:
Task generalization: Can robots understand and execute never-before-seen new task instructions, rather than just repeating trained fixed procedures?
Scene generalization: Can robots maintain stable operation in unfamiliar environments, remaining reliable when moving from the lab to the real world?
Object generalization: Can robots manipulate new objects never encountered during training, maintaining stable operation when materials, shapes, weights, friction, and flexible structures all change?
These three challenges make the transition of embodied intelligence from 'usable' to 'reliable' exceptionally difficult.
The emergence of the VLOA model provides a highly imaginative technological path for breaking through generalization bottlenecks. Currently, the entire industry is tackling generalization challenges through multiple technological approaches.
In April this year, Physical Intelligence released its latest π0.7 model, demonstrating a 'compositional generalization ability' that even surprised the research team.
In the training data, the model had almost no exposure to air fryer operations, with only two extremely peripheral related clips.
Yet the model ultimately formed a functional understanding of 'how an air fryer works' by combining different robot operation clips, web pre-training knowledge, and historical action experiences, successfully completing the task.
Using compositional generalization, the model no longer rote-memorizes solutions for specific tasks—it can migrate existing experiences to solve unknown problems.
Some companies are advancing routes that fuse world models with VLA.
Zhipingfang, one of China's earliest startups to deploy end-to-end VLA, released its Video2Act fusion architecture in November last year, combining world models with VLA.
This not only lets robots 'understand tasks' but also enables them to predict physical change processes, enhancing reasoning and decision-making capabilities in complex environments.

JD Joy Future Academy, within the VLA framework, proposed the JoyAI-RA 0.1 model, introducing a unified action space to provide a standardized action interface for robots of different forms.
The model can learn from human videos, simulated trajectories, and real-robot actions within the same space, significantly improving the efficiency of cross-entity knowledge transfer.
This reflects another important industry trend: robots are attempting to break free from the fragmented state of 'one model per machine.'
Additionally, Magic Atom released its self-developed world model, Magic-Mix.
This model consists of two core engines: Magic-Mix WAM handles physical environment understanding, spatial reasoning, and action decision-making.
Magic-Mix Creator serves as an offline data generation engine, reducing reliance on expensive, time-consuming real-robot data collection by synthesizing large volumes of training data, providing continuous data supply for the model, and forming a 'data generation-training-feedback' closed loop.
Essentially, this architecture directly addresses the long-standing pain points of VLA models—insufficient generalization and unstable execution in the real world—enabling robots to understand the physical world, predict the future, and make decisions.
Industry controversy over VLA models reached a peak in May when NVIDIA Robotics head Jim Fan declared 'VLA is dead' at the Sequoia AI Ascent Summit, sparking intense debate.
While many researchers argue that VLA still plays an irreplaceable role in numerous scenarios, this sentiment at least reflects the industry's broader concerns about existing models' generalization capabilities.
Wang Zhongyuan, dean of the Zhiyuan Institute, pointed out that the most practical path is to overcome specific scenarios through 'VLA + reinforcement learning,' letting robots start operating in the real world, accumulating more data through actual operation, forming a data closed loop, and finally addressing generalization challenges.
Guo Yandong, founder of Zhipingfang, believes:
'VLA is far from over—it's the strongest main pathway to physical world intelligence. The industry is rapidly moving toward a hybrid route of 'world model + VLA.' The next generation of robot brains will be brain-inspired VLA.'
Against this industry backdrop, RoboScience's RMB 1 billion Series A financing represents capital's vote for the 'AI brain route.'
VLOA doesn't just make models memorize more scenarios—it makes them understand the physical essence of operations, learning 'how objects move.' Its generalization capability must ultimately be validated through the continuous operation of hundreds or thousands of robots in real-world environments.
Currently embroiled in conceptual debates—whether VLA is dead, end-to-end or hierarchical approaches, whether world models are the endpoint or a transitional solution—it's premature and unnecessary to reach definitive conclusions.
The most important thing is how to continuously enhance model capabilities through architectural innovation.
There's no standard answer to the generalization challenge, but the direction is clear: whichever path is taken, models must ultimately evolve from 'doing what they've seen' to 'doing what they understand.'
The deciding factor in this competition won't be who shouts the next slogan first, but who first makes models truly understand the physical world.
-
![]()
Why Does Jensen Huang So Openly Praise China’s AI?
-
![]()
"Wudang" Unveiled: Arm China's Next-Gen AI VPU Redefines Video Encoding
-
![]()
From Energy Conservation and Carbon Reduction to AI Decision-Making: GECON East Intelligence and Chery Group Explore a New Green and Smart Paradigm for Automobile Manufacturing
-
![]()
WAIC 2026 Observation | AI Accelerates Towards the Core of Industries, Industrial AI Enters a Critical Phase
-
![]()
Volkswagen China Fires the First Shot in Foreign-Funded 'White Box Delivery'!
-
![]()
AI Agent Smartphones: The Next Competitive Edge Transcends Large Models
-
![]()
Over 880 Million Yuan Worth of Orders Unveiled, Bidding Launched for Shenzhen Eastern Public Transport
-
![]()
Tesla's Robotaxi Hits the Road: A Monumental Gamble with an Uncertain Future







