AI Gaokao Evaluations Plagued by Chaos: Full Marks Awarded for Incomplete Questions
 06/12 2026
06/12 2026
 440
440

Chaos in Evaluations Must End: An AI-Generated Illustration
Manual Work / Edited by Wage / Produced by Jiaoshu / Unicorn Observation
The annual gaokao (Chinese college entrance examination) has concluded, and the much-discussed exam topics have once again become the focal point for online traffic competition.
Unlike previous years, with the widespread adoption and maturity of large artificial intelligence models, various AI products have come into the public spotlight. While students are tackling questions inside the examination hall, outside, large models are also being “fed” different versions of gaokao questions to compete.
Using gaokao questions to test AI’s problem-solving abilities is understandable. However, some marketing accounts lack a scientific approach and rigorous argumentation, leading to evaluation conclusions that deviate from objective facts and fail to stand up to scrutiny. This not only misleads students and parents but also disrupts the orderly development of the AI industry.
01 Evaluation Blunders: Full Answers from Incomplete Questions
During this year’s gaokao, a self-media article titled “The Toughest Gaokao Physics Question for ‘Selecting Newton’s Successor’: Qianwen Answers All Three Parts Correctly” garnered significant attention on social platforms.
The article claimed to conduct a horizontal AI evaluation using the authentic final physics question from the 2026 Guangdong gaokao, concluding that “Qianwen answered perfectly, while the other two AI models failed throughout.” It leveraged a strong sense of contrast and suspense to attract traffic.
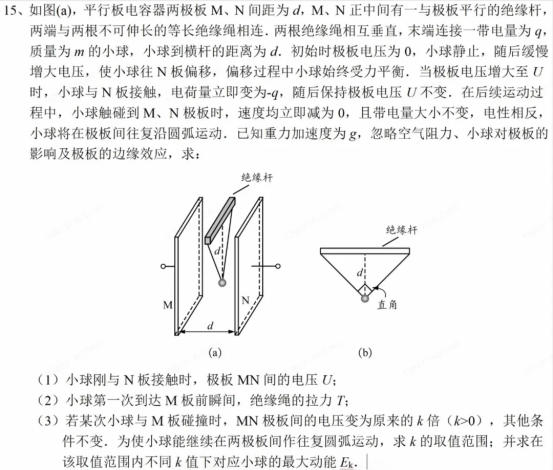
This question used a parallel-plate capacitor, an insulating rod, a charged ball, and an insulating rope as physical models, integrating multiple core knowledge points such as electric field force, gravity, circular motion, and collision-induced charging reversal. The entire question was divided into three progressive sub-questions, each interconnected, with indispensable information in the question stem, graphical descriptions, physical conditions, and inquiry requirements.
At the end of the article, it was stated that physics best exposes AI’s true capabilities because physics questions require comprehensive abilities such as “visual understanding + semantic understanding, abstract thinking + domain knowledge, reasoning and planning, and calculation + verification.” Any break in the chain would render subsequent efforts futile.
From the answer process and results presented in the article alone, no issues seemed apparent.

However, after meticulous reconstruction of the evaluation scenario by vigilant netizens, a hidden “trick” behind the so-called “perfect answer” was uncovered—if parts of this gaokao physics question were removed, leaving only an incomplete question stem and omitting the core inquiry, the Qianwen model could still output a complete answer.
This makes the praised “visual understanding + semantic understanding” appear somewhat ironic. If visual understanding were truly effective, it should have recognized that the “question is incomplete and lacks answer requirements.”
Considering common technical knowledge in the AI industry, it is not difficult to deduce that this model likely had the complete question stem, solution steps, and standard answer for this gaokao physics question in its knowledge base, essentially “memorizing” the answer.
To be fair, including gaokao and other exam answers in AI products is a routine practice and does not constitute “cheating.” The failure of this evaluation ultimately stems from its one-sidedness and lack of scientific argumentation.

Interestingly, Unicorn Observation presented this evaluation article praising Qianwen to Qianwen itself, asking if it was scientific and objective.
Qianwen concluded that “this is not a double-blind, random, multidimensional scientific evaluation” and pointed out that the article’s biggest scientific flaw was the lack of randomness in sample selection: concluding “one model got all correct, two got all wrong” based on a single question (albeit the final one) and then deriving that “physics best exposes AI’s true capabilities” is statistically invalid. This single question might just be a “strong suit” in Qianwen’s training data, or its algorithm might happen to align with the question’s logical traps.
A true scientific evaluation should include various types of questions (e.g., simple conceptual questions, complex calculation questions, experimental questions). Testing only the “toughest” question can only indicate performance under extreme conditions, not overall physics proficiency.
Here, we commend Qianwen for its self-awareness.
02 Logical Distortions: Chaos Abounds in Gaokao Evaluations
A rigorous AI capability evaluation should adhere to the core principles of “objectivity, fairness, completeness, and reproducibility.” The evaluation scenario, testing materials, and judging criteria must be transparent, with conclusions based on real test data.
The self-media evaluation that sparked controversy had multiple flaws throughout, from test design and process presentation to conclusion derivation, rendering its final conclusions entirely untenable—even the praised Qianwen model “felt embarrassed to accept” them.
Particularly noteworthy is that the evaluation used authentic gaokao questions, which are publicly available and often contain numerous errors in their initial versions as they circulate online based on candidates’ recollections. A professional evaluation should properly proofread the questions and test using the AI model’s reasoning abilities rather than searching for answers online.
Whether motivated by traffic-chasing, lack of professional competence, or information asymmetry, there have been numerous blunders in this year’s gaokao question evaluations.
Some evaluations engaged in “random scoring,” deliberately packaging flawed, logically incoherent answers as “perfect” marketing materials, glorifying obvious derivational errors and symbolic misuses as “problem-solving highlights,” and even crafting “perfect score myths” tailored to specific AI models.

For instance, consider this AI answer sheet praised as having scored perfectly. The original question conditions included “when 0 < x < 1,” but the AI answer skipped this crucial part, leading to an incorrect solution. Yet, it was still hailed as a “perfect answer.”
Other evaluations were also highly unrigorous, producing “sensational” results—such as claiming that none of the large models answered correctly—only for netizens to later discover that the question had been transmitted incorrectly, leading to absurd outcomes.
More egregiously, some evaluations did not disclose the complete answer process, instead compiling lists of AI problem-solving abilities based solely on a few screenshots and snippets of text. The data sources for these lists were unclear, and comparison dimensions were missing, yet they spread wildly on social platforms.
Such evaluations lack professional knowledge, featuring flowery language, exaggerated rhetoric, and absolute terms like “strongest,” “peak,” and “crushing peers.” They evaluate AI performance based solely on subjective feelings, completely losing neutrality and objectivity.
Leveraging the gaokao hotspot as a gimmick, these evaluations have transformed into marketing tools, disrupting the public’s judgment of AI’s true capabilities and undermining the reference value and professional credibility that evaluations should possess. They have reduced rigorous technical comparisons to mere tools for traffic hype. It is time to put an end to this. (End)
-
![]()
Insta360 Leads Global Market, Yet Profit Signals Remain Subdued
-
Marketing and Transaction Growth: Entering the Age of the Agent
-
![]()
Dongfeng’s Solid-State Batteries Set for Mass Production and Vehicle Integration in H2 2026
-
Marketing and Transaction Growth: Entering the Age of Agent
-
![]()
Stock Prices Hit Rock Bottom & Regulatory Interviews Raise Dual Alarms in Auto Industry
-
![]()
Can the Hongqi G919 Surmount the Challenge Posed by the Mengshi 917?
-
![]()
AI Gaokao Evaluations Plagued by Chaos: Full Marks Awarded for Incomplete Questions
-
![]()
For Two Straight Months, No BBA Model Has Exceeded 10,000 Monthly Sales in the Chinese Market





