TOP500 supercomputer rankings released: El Capitan tops the list with 1.742 EFlop/s
 11/19 2024
11/19 2024
 639
639

This article is compiled by Semiconductor Industry Insights (ID: ICVIEWS) from nextplatform
The 'El Capitan' supercomputer pioneered the integration of CPU-GPU computing.
According to experts from Lawrence Livermore, El Capitan is comparable to large machines launched by hyperscale enterprises and cloud builders for AI training operations across various metrics. El Capitan is a machine specifically tailored to run the most complex and intensive simulation and modeling workloads ever created, and it excels precisely at the core of the GenAI revolution—new large language models.
Moreover, benefiting from Cray's designed 'Rosetta' Slingshot 11 interconnect and the core components of the EX series systems sold by Hewlett-Packard Enterprise, El Capitan has adopted HPC-enhanced scalable Ethernet, similar to the technology route that the Ultra Ethernet Consortium is trying to promote, as hyperscale enterprises and cloud builders are tired of paying high fees for InfiniBand networks for their AI clusters.
Lawrence Livermore will acquire an extremely powerful HPC/AI supercomputer at a much lower cost than what hyperscale computing companies, cloud builders, and large AI startups pay today. It's difficult to accurately state the difference, but based on my preliminary rough calculations, the cost per unit of FP16 performance for El Capitan is half that of the large 'Hopper' H100 clusters being built by Microsoft Azure, Meta Platforms, xAI, and other companies.
National security is crucial, and certain technological breakthroughs and innovations have positive implications. Taking El Capitan as an example, breaking the architectural limits of system design is of great significance. At the same time, it takes courage to demonstrate capabilities in designing hybrid CPU-GPU computing engines and integrating ultra-fast HBM memory into the shared memory space between these fusion devices. These measures can all bring benefits. Finally, there is a huge difference between El Capitan and the powerful machines being built by hyperscale enterprises, cloud builders, and AI startups.
In August 2019, Hewlett-Packard Enterprise (HPE) secured a multimillion-dollar El Capitan contract. At that time, users only knew that the machine would use the Slingshot interconnect, cost approximately $500 million, and provide sustained performance of at least 150 petaflops. Just a few months earlier, HPE announced its acquisition of Cray for $1.3 billion.
Regardless, the sustained performance of El Capitan was expected to be at least 10 times that of the 'Sierra' hybrid CPU-GPU system built by IBM for the laboratory, with a power range of 30 megawatts. In March 2020, Lawrence Livermore announced that it was collaborating with AMD to develop the computing engine for El Capitan, further stating that the system's peak theoretical FP64 performance would exceed 200 petaflops (the actual system can perform calculations at 64-bit resolution), with a power consumption of approximately 40 megawatts and a cost of no more than $600 million.
The El Capitan hybrid CPU-GPU system has been installed and is nearly fully operational at Lawrence Livermore, widely recognized as the world's most performant system for traditional simulation and modeling workloads, including the peak performance of China's 'Tianhe-3' (205 petaflops) and 'OceanLight' (150 petaflops) supercomputers.
In June 2022, Lawrence Livermore and AMD announced the adoption of fused CPU-GPU devices (which AMD has been calling Accelerated Processing Units or APUs for decades) as the primary computing engine for the El Capitan system. Since then, there has been speculation about the clock speed of the 'Antares' Instinct MI300A devices, the number of GPU compute units in the devices, and their operating clock speeds. It turns out that I believe the clock speed of the MI300A will be higher, requiring fewer clock cycles to achieve the corresponding performance. The machine performance Lawrence Livermore has acquired is better than expected, so its cost-effectiveness even exceeds expected levels.
Bronis de Supinski, CTO of Lawrence Livermore National Laboratory's Livermore Computing Division, revealed that there are a total of 87 computer racks in the El Capitan system, with dozens of additional racks to accommodate its 'Rabbit' NVM-Express fast storage array.
El Capitan boasts a total of 11,136 nodes in liquid-cooled Cray EX racks, each equipped with four MI300A compute engines, totaling 44,544 devices across the system. Each device has 128GB of HBM3 main memory shared by CPU and GPU chips, operating at 5.2GHz, providing a total bandwidth of 5.3TB/s for both CPU and GPU chips.
According to the November Top500 list, the MI300A CPU chipset operates at 1.8 GHz, while AMD specifications indicate a peak operating frequency of 2.1 GHz for the GPU chipset. The chipset contains three 'Genoa' X86 compute complexes, each with eight cores for a total of 24 cores, etched using TSMC's 5-nanometer process. The six Antares GPU chipsets on the MI300A devices have 228 GPU compute units, totaling 912 matrix cores and 14,592 stream processors. In terms of vector units, the MI300A has a peak FP64 performance of 61.3 trillion floating-point operations, and on matrix units, its FP64 performance is double that of vector units, at 122.6 trillion floating-point operations.
Each El Capitan node has a peak FP64 performance of up to 250.8 teraflops, and when all nodes are connected, the total FP64 performance reaches 2,792.9 petaflops, with 5.475 PB of HBM3 memory at the front end. Below the CPU and GPU compute chips are four I/O chips, etched using TSMC's 6-nanometer process, used to integrate and connect these components to HBM3 memory.
Notably, there are still six compute chips (referred to as XCDs in AMD terminology) on the MI300A package, perfectly matching the six GPU chips. The custom 'Trento' CPU XCDs (eight per node in a single chip) of Oak Ridge's 'Frontier' supercomputer have a one-to-one ratio with four independent dual-chip 'Aldebaran' MI250X GPUs. This one-to-one packaging format has persisted across multiple generations of Cray supercomputers' CPUs and accelerators, which may not be coincidental. In a sense, the MI300A is a six-way X86 CPU server cross-coupled with a six-way GPU system board.
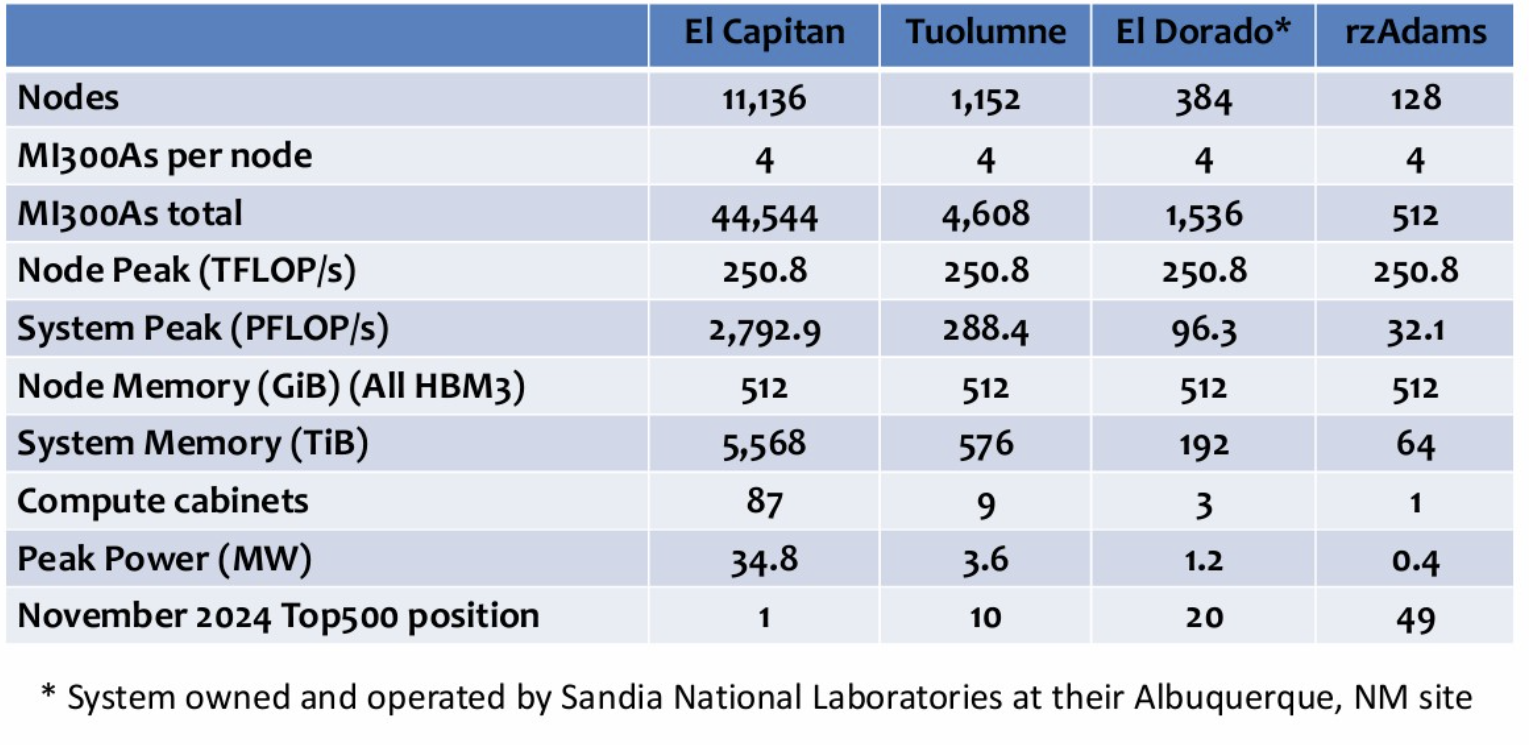
Below is a summary table showing the relevant parameters of the El Capitan system, its 'Toulumne' and 'rzAdams' chips in the El Capitan block at Lawrence Livermore, and the 'El Dorado' system at Sandia National Laboratory:
A schematic diagram of the El Capitan server node is as follows:
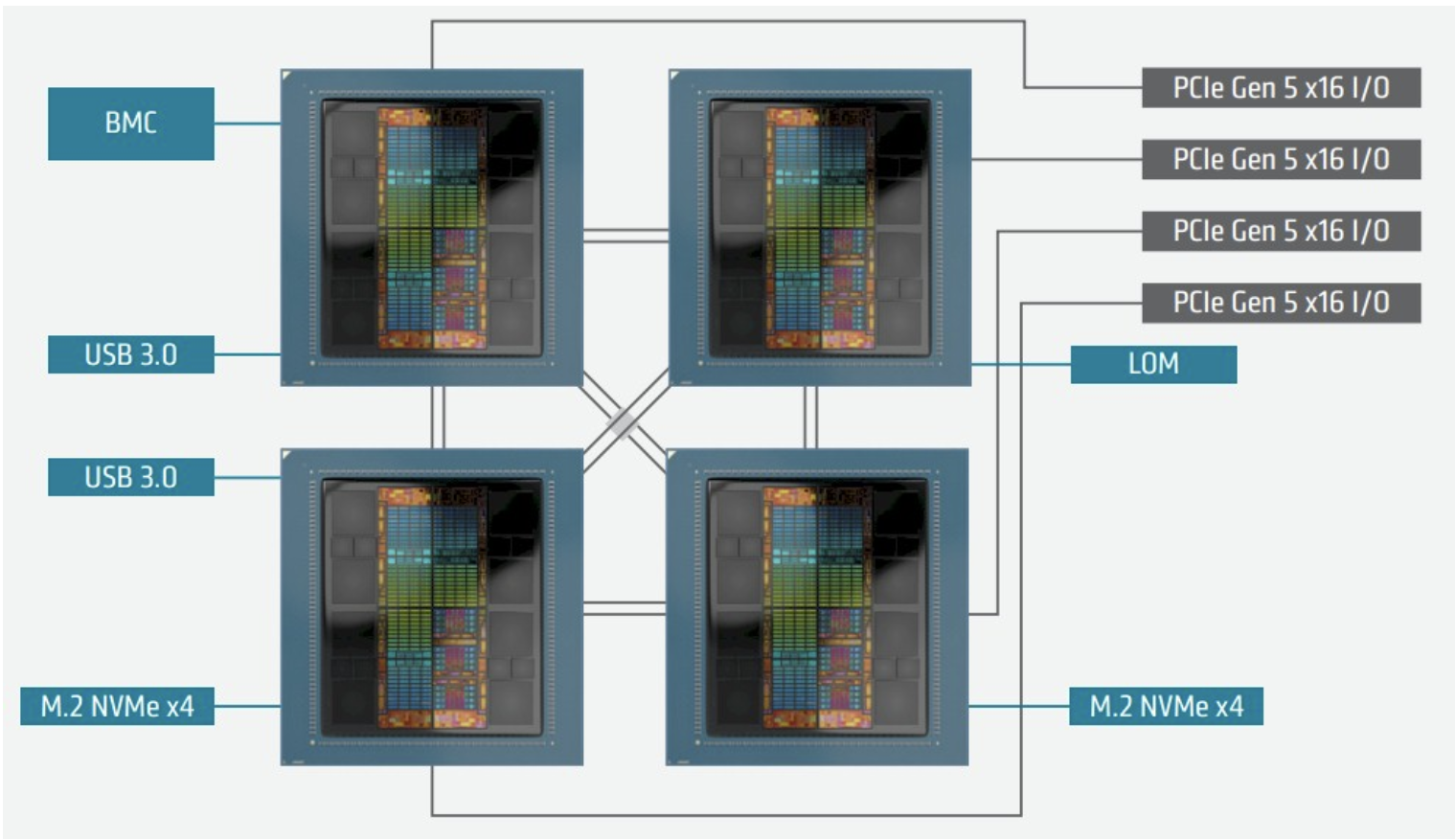
As you can see, there are four Infinity Fabric x16 ports with a total bandwidth of 128 GB/s, interconnecting the four MI300A devices in a memory-coherent manner.
Additionally, there are four ports that can be configured as PCI-Express 5.0 x16 slots or Infinity Fabric x16 slots. In this case, they are set to the former to insert Slingshot 11 network interface cards, which actually interconnect the APUs across the entire system through the Slingshot 11 architecture.
Finally, an interesting observation about the El Capitan system is that technically, the part of the machine used to run the High-Performance Linpack benchmark that ranks supercomputers can achieve a performance of 2,746.38 petaflops. (If there are a total of 44,544 APUs on the physical machine, 43,808 APUs are activated on this part, accounting for 98.3% of the machine's capacity.) The last 46 teraflops (the third and fourth significant digits of the performance) at the end of the rated performance are larger than all but 34 machines on the November 2024 Top500 list. The rounded-off numbers omitted when referring to '2.7 exaflops' are almost equivalent in scale to the 'MareNostrum 5' supercomputer at the Barcelona Supercomputing Center.
If Lawrence Livermore allows HPL to run on all APUs in the system, El Capitan's performance will increase by another 1.65%, and we believe improvements in the interaction between computation, memory, and interconnect can further boost its performance by about 5%. If Lawrence Livermore can increase software and network tuning performance by 7.5%, the machine's peak HPL capacity will exceed 3 exaflops, a goal we expect the laboratory to achieve given its significance. This will be double the initial expected performance of El Capitan when the project started five years ago—and on schedule and within budget.
*Disclaimer: This article is originally created by the author. The content reflects the author's personal views and is republished for sharing and discussion purposes only. It does not represent our endorsement or agreement. For any objections, please contact us.
-
![]()
Will the Upcoming Kimi Replicate MiniMax's Trend?
-
![]()
BYD at the Crossroads of Scale and Profitability
-
![]()
Is It Down to a Daily Payment of Just 29 Yuan?!
-
Observing the Fate of Joint Venture Automakers from Skoda's Exit from China
-
![]()
Doubao Boosts Sales, Qianwen Streamlines Mobile Recharges: Large Models Step into the 'Era of Practical Deployment'
-
![]()
Pony.ai Explains Robotaxi 'Profit Replication Strategy': How to Scale from a Vehicle Earning RMB 338 Daily to 20 Cities?
-
![]()
Behind the Crazy High Valuation: Is MiniMax a Bubble or a Glimpse into the Future?
-
![]()
The Bottom-end Electric Vehicle Market Collapses: What Should Leapmotor and Chery Do as They Enter the Market?