ChatGPT's 2nd Anniversary: Domestic Large Models in Hot Pursuit
 12/02 2024
12/02 2024
 806
806

In the second year of ChatGPT's inception, OpenAI and numerous domestic enterprises are attempting to "abandon" it.
Amidst questions about the Scaling Law reaching its peak, OpenAI released the o1 model series in September, rekindling the spotlight on "thinking large models."
"I believe the most important message from this o1 model release is that AI development has not slowed down; rather, we are confident about the coming years." Altman expressed full confidence in the o1 release.
Domestic large model manufacturers have also put the task of learning from and surpassing o1 on their agendas. Just over two months later, domestic large model companies followed suit, each introducing their distinctive o1-like deep-thinking models.
Whether it's kimi's k0 math, Deepseek's DeepSeek-R1-Lite, or Kunlun Tech's "Skywork Large Model 4.0" o1 version, all emphasize the importance of logical thinking capabilities in domestic large models.
Domestic Large Models Collectively Follow o1
Without OpenAI disclosing specific o1 technology, domestic large model companies caught up with cutting-edge capabilities in just about two months:
On November 16, Moon's Dark Side unveiled the new k0 math model at a press conference. By adopting reinforcement learning and chain-of-thought reasoning technology, the large model begins to simulate human thinking and reflection processes, enhancing its mathematical reasoning abilities. As the name suggests, its ability to tackle mathematical problems is "far ahead."
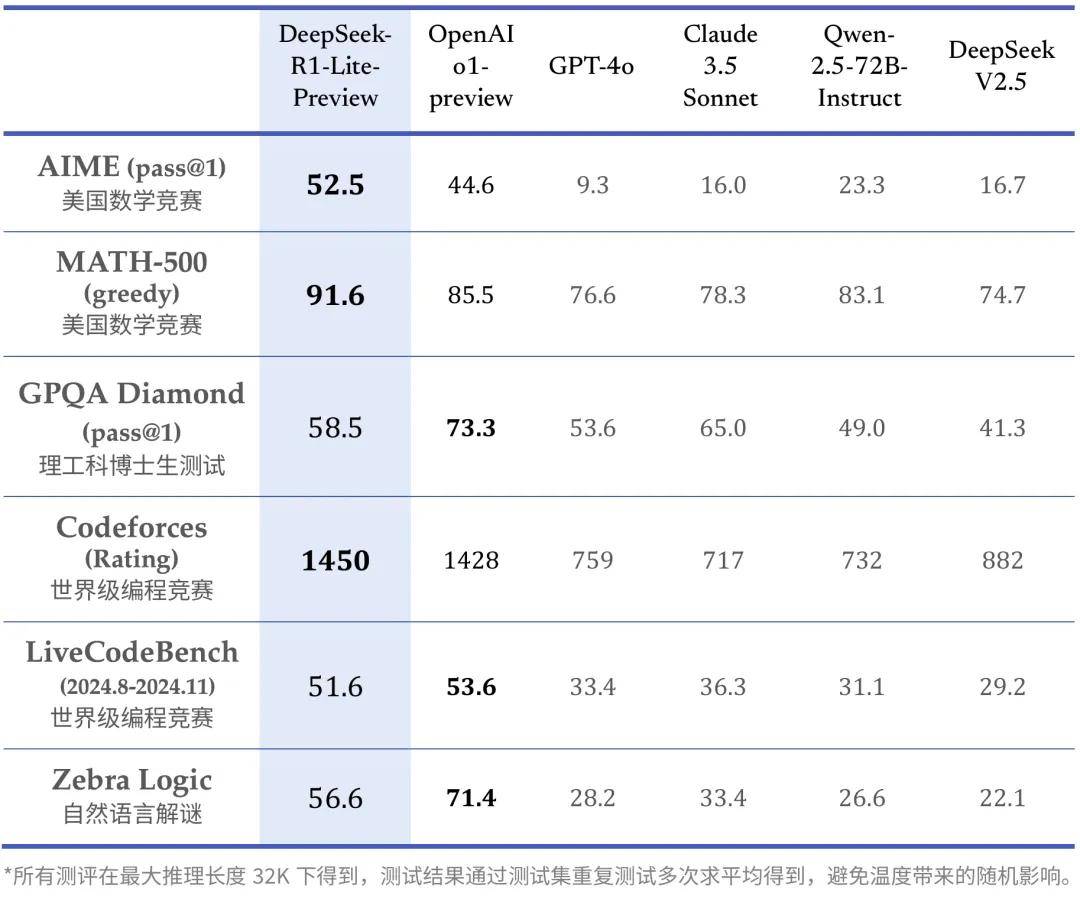
Four days later, Deepseek officially launched DeepSeek-R1-Lite. Compared to OpenAI's o1, R1 unreservedly reveals the entire thinking process of the large model. Officials stated that R1's chain of thought can reach tens of thousands of words. According to official test results, R1 outperformed o1-Preview in AIME (American Invitational Mathematics Examination) and some programming competitions. Deepseek also directly released a beta version on its website, allowing users to experience 50 conversations per day.
Just last Wednesday (November 27), Kunlun Tech also released the Skywork o1 version of its Skywork Large Model 4.0, which boasts complex thinking and reasoning abilities, announcing it as the first Chinese logic reasoning model in China. It also introduced three model versions at once: the open-source Skywork O1 Open, the Skywork O1 Lite optimized for Chinese support, and the Skywork O1 Preview that fully showcases the model's thinking process.
The emerging domestic "o1" large models aim to go beyond simple "model replication."
Based on model test scores, the aforementioned models' performances in mathematics and coding are approaching or even surpassing those of o1:
Taking k0 math as an example, in the four math benchmark tests of middle school entrance exams, college entrance exams, graduate entrance exams, and MATH, which includes introductory competition questions, k0-math outperformed OpenAI's o1-mini and o1-preview models.
However, in more challenging competition test questions, such as the more difficult competition-level math databases OMNI-MATH and AIME benchmarks, k0 math's performance has yet to catch up with o1-mini.
Able to solve difficult math problems, o1-like large models have begun to learn "slow thinking."
By introducing chains of thought (CoT) into the model, large models break down complex problems into smaller ones, simulating the step-by-step reasoning process of humans. This is done independently by the large model without human intervention. Reinforcement learning enables the large model to try various solution methods and adjust strategies based on feedback, with both learning and reflection tasks delegated to the model.
Compared to general models, these products can also provide correct answers to problems that were previously unsolvable, such as "How many 'r's are there in 'strawberry'?" or "Which is bigger, 9.11 or 9.9?" When posed to o1, it can provide the correct answer after some thought.

For example, when asked "How many 'i's are there in 'Responsibility'?" by Deepseek R1, in deep thinking mode, we can see the large model's thought process: it first breaks down the word into individual letters, compares each letter step by step, and finally gives the correct result. In tests, R1's thinking speed is also fast, providing answers in less than two seconds.

Specialization or Ivory Tower: The Two Sides of the o1 Coin
Mass-produced "slow-thinking" large models, enhanced by reinforcement learning and logical chains, have seen tremendous improvements in model capabilities.
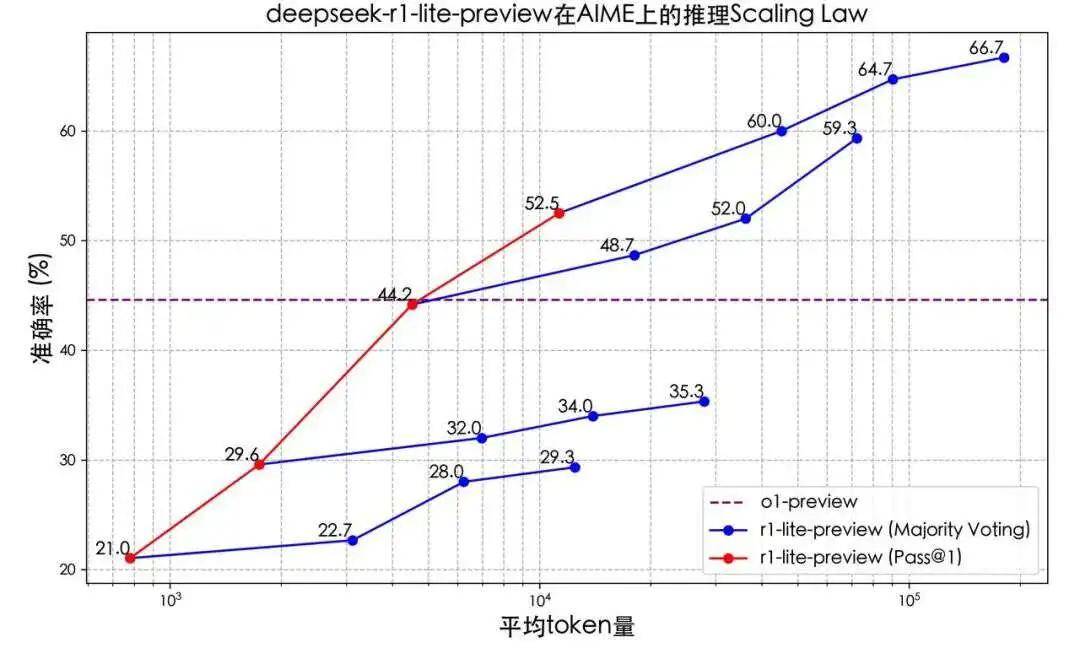
In the test results released by Deepseek, it can be seen that there is a direct proportional relationship between the reasoning time and accuracy of DeepSeek-R1-Lite, i.e., the longer the reasoning time, the better the performance. Compared to previous models without "slow thinking" capabilities, R1's performance is far superior.
With these enhanced capabilities, large models have significantly improved their self-reflection and learning abilities. For example, when confronted with traps, models can avoid problems independently through the chain-of-thought mode.
When releasing its self-developed model, Kunlun Tech gave the large model a "trap" question. It was asked to convert "qíng rén yǎn lǐ chū xī shī" to Chinese. During the first round of thinking and conclusion drawing, the large model proactively identified that "xī shī" was incorrect and found the accurate translation through reasoning.

On the one hand, slow-thinking models significantly enhance large models' performance in specific disciplines, further improving their ability to solve difficult problems; on the other hand, the substantial consumption of tokens may not necessarily yield the returns users desire, which is often criticized by users.
In some cases, increasing the length of a model's chain of thought can improve efficiency as the model can better understand and solve problems.
However, this does not mean it is the optimal solution in all cases.
For example, considering common-sense questions like "1+1>2," using previous large model capabilities is more efficient and cost-effective. This requires large models to judge the difficulty of problems independently and decide whether to use deep-thinking mode to answer corresponding questions.
In scientific research or complex project planning, increasing the length of the chain of thought can be beneficial. In these scenarios, deeply understanding various variables and their interactions is crucial for formulating effective strategies and predicting future outcomes.
Moreover, transitioning from reinforcement learning applications in specific scenarios to general models may pose certain challenges in balancing training computational power and costs.
Judging from the models released domestically, the base model parameters for current "slow-thinking" large model developments are not large. For example, the model versions provided by Deepseek and Kunlun Tech are based on smaller-scale models: Skywork o1 Open is based on the open-source Llama 3.1 8B model, and Deepseek also emphasizes that it currently uses a smaller base model that cannot fully unleash the potential of long chains of thought.
"One thing that is highly likely is that during the RL training phase, the computational power required may not be less than that required for pre-training. This may be a non-consensus view." When discussing o1, StepStar CEO Jiang Daxin once mentioned this issue.
Future large models should not expend significant effort on simple problems. To develop models that truly unleash the power of chains of thought will require some time.
Breaking Through the Second Stage of AGI: Domestic Acceleration in Exploring Product Implementation
Why do major companies view o1 as the next necessity?
In the "Five Stages to AGI" defined by OpenAI and AI Spectrum, both companies classify multimodal and large language model capabilities as L1, the most basic level of capability.
The emergence of o1 signifies that large model capabilities have broken through to the L2 stage. Since then, large models have truly acquired logical thinking abilities, capable of planning, validating, and reflecting without human intervention.
Currently, although overseas companies represented by OpenAI have taken the lead in realizing "slow-thinking" large model capabilities, domestic manufacturers are thinking more about catching up. While simultaneously following up on o1-like products, large model companies are already considering how to integrate o1 capabilities with existing AI application directions.
Regarding concerns about the stagnation of large model training progress, it can be seen that o1 can provide new support for the Scaling Law amidst data depletion.
Previously, large model training had reached a "no data available" dilemma. As available high-quality data resources become increasingly limited, this poses a challenge to AI large models that rely on massive data for training.
The entry of more large model companies may jointly explore greater possibilities. "o1 has scaled to a significant size. I believe it brings a new paradigm for Scaling technology, which we might call RL Scaling. Moreover, o1 is still immature; it's just the beginning," said Jiang Daxin.
In existing AI applications, the ability of chains of thought has already helped improve the effectiveness of AI technology.
Taking AI Spectrum's "Reflective AI Search" as an example, combined with the ability of chains of thought, AI can break down complex problems into multiple steps for step-by-step search and reasoning. Through internet search + deep reasoning, and then synthesizing all answer information, AI can provide a more accurate answer.
As large models begin to learn "self-thinking," the door to L3 (Agent) is also being opened by large model companies.
"It took some time to move from L1 to L2, but I believe one of the most exciting things about L2 is that it can relatively quickly achieve L3. We expect this technology will ultimately lead to very influential agents." When discussing o1, Sam Altman affirmed the potential of "slow-thinking" models in driving agent development.
In realizing agent capabilities, the chain of thought is a crucial step for agent functionality. By applying the chain-of-thought capability, large models can plan received tasks, break down complex requirements into multiple steps, and support agent task planning.
A recent surge of "autonomous agent" products represents a breakthrough in Agent capabilities: by breaking down task execution to the extreme, AI begins to learn to use mobile phones and computers like humans, helping users complete cross-application operations. Agents launched by companies like AI Spectrum and Honor can already help users complete ordering tasks through commands.
However, given the current situation, developers still need to specifically adjust the output effect of agents based on the capabilities of o1-like products to make them closer to human usage habits.
How to balance the evolution of large model reasoning and user demand for efficiency without overthinking? This was a question raised by Yang Zhilin at the Yunqi Conference a few months ago. This question still needs to be addressed by domestic large model manufacturers.
-
![]()
139 Institutions Conduct Research as Robotec Promptly Secures a Major Order Worth 129 Million Yuan!
-
![]()
Zeiss Boosts Investment to Expand 25,000-sqm Optical Plant, Elevating Its Exclusive EUV Optical Manufacturing Capabilities!
-
![]()
SAIC’s Four Key Divisions See Leadership Overhaul: Lu Xiao Moves to Passenger Cars, Xu Ping Takes Charge of GM, Wu Yun Leads Volkswagen
-
![]()
Nearly a Year On, Traffickers Still Reap Tens of Thousands by Selling Zeekr 9X in Russia
-
![]()
Apple’s New Business Model: Pay $39 a Month, But at What Cost to Your Wallet?
-
![]()
Tencent Places Its Bets on WorkBuddy: The Next Frontier in AI-Driven Office Solutions, Vying for the Smart Gateway
-
![]()
Apple Reclaims Global Market Cap Crown: Is a Strong Device the True Path for AI?
-
![]()
Apple Regains Global Market Cap Leadership: Are Smart Devices the Future of AI?